Spark与TensorFlow深度整合:分布式深度学习实战与原理解析
200 浏览量
更新于2024-07-15
收藏 2.58MB PDF 举报
"当Spark遇上TensorFlow分布式深度学习框架原理和实践"这篇文章探讨了深度学习技术在现代IT领域的热门趋势,特别是谷歌推出的深度学习框架TensorFlow与Apache Spark的结合。随着机器学习和深度学习的广泛应用,TensorFlow因其强大的功能和易用性受到广泛关注。Spark和TensorFlow的融合允许用户在已有的Spark集群上进行深度学习任务,无需额外配置专用的深度学习服务器,从而节省成本和资源。
文章首先概述了大数据的价值,指出其在项目中的三种主要应用,包括数据处理、模型训练和结果分析。大数据的价值体现在数据驱动决策和优化业务流程中。在这个过程中,Spark作为数据处理的核心框架,通过RDD(弹性分布式数据集)提供了分布式计算的能力,确保数据一致性、高效并行处理和容错机制,简化了开发者的工作。
接着,文章介绍了Spark的主要特性,包括核心抽象RDD的设计理念,以及Spark生态系统中包含的组件库、部署环境和数据来源。SparkSQL和Spark Streaming等工具在文中也得到了提及,它们扩展了Spark在结构化和实时数据处理上的能力。
在深度学习方面,文章重点讨论了Spark与TensorFlow的协同工作。TensorFlow作为模型训练框架,专注于模型构建、反向传播、梯度更新和超参数调整等过程,其计算模型依赖于输入x和目标y。而Spark则在模型训练的前阶段,负责数据预处理、特征提取和实时数据整合等任务。
文章还分享了如何使用TensorFlow on Spark(TF on SPARK)开源框架来构建分布式图像分类模型的实际案例。通过结合Spark的高效计算能力和TensorFlow的强大模型构建能力,用户可以在大规模数据集上进行高效的深度学习模型训练。
这篇文章深入浅出地解释了Spark与TensorFlow深度学习框架集成的关键原理,为读者提供了实际操作的指导,展示了如何在分布式环境中有效利用这两个工具进行深度学习项目的开发和实施。通过这种方式,企业可以更好地利用现有资源进行高性能的AI项目开发,降低运维成本。"
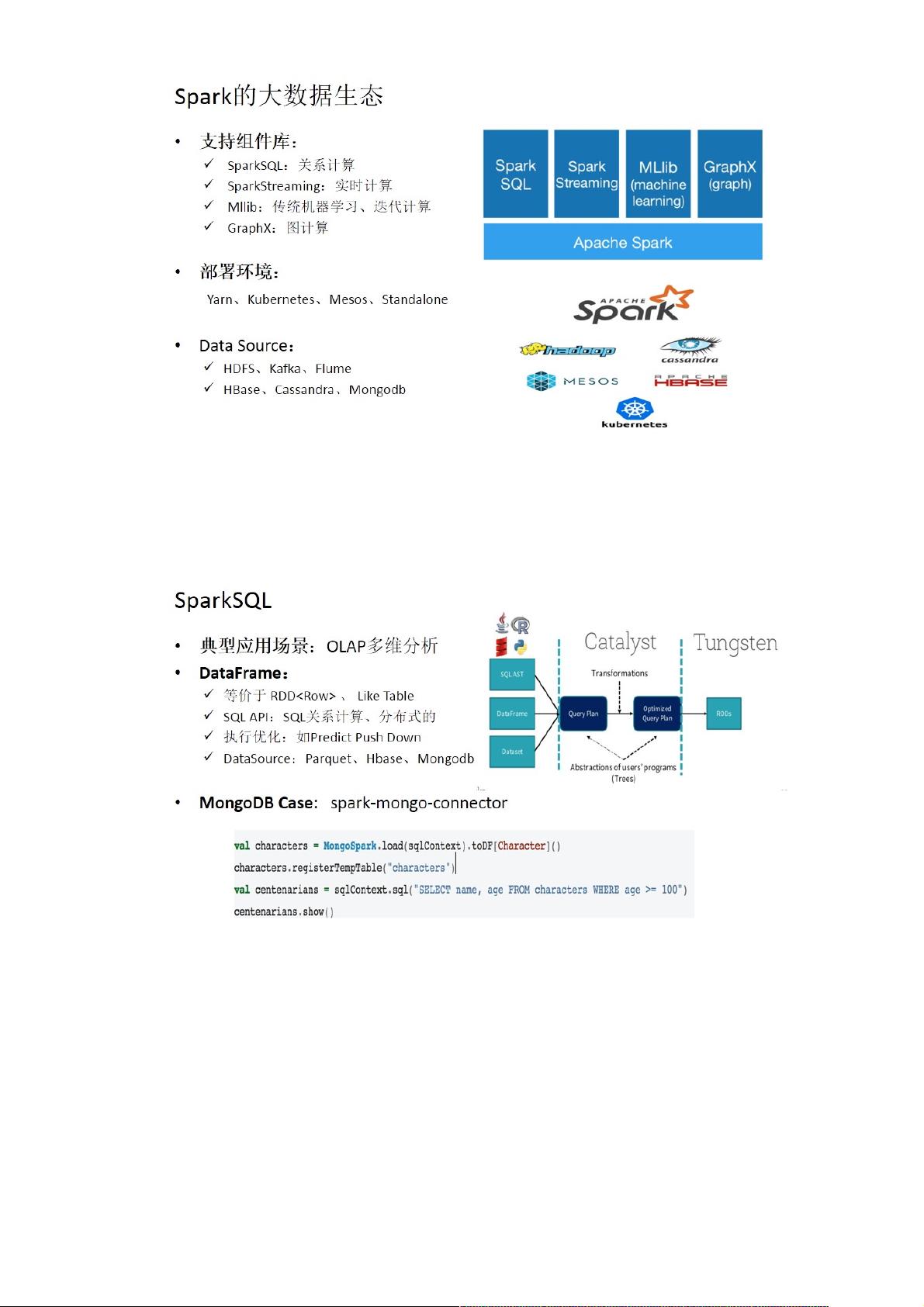
3.Spark SQL和Spark Streaming:
我们简要介绍一下这两个比较重要的组件,首先是spark sql,它的典型应用场景是OLAP多维分析,它提供了一个DataFrame
抽象接口,等价于RDD,如下图所示。
Spark Streaming是spark的一个实时处理组件,它的典型应用场景是实时特征处理,它提供了一个Dstreams抽象接口,直观
上理解Dstreams就是一个持续的RDD,如下图。
剩余14页未读,继续阅读
326 浏览量
2024-07-18 上传
306 浏览量
207 浏览量
171 浏览量
326 浏览量
207 浏览量
134 浏览量
点击了解资源详情

weixin_38607195
- 粉丝: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- 64位WIN10下通过文件操作驱动USB警示灯技术分享
- Java图片上传功能实现教程
- 安装gcc 4.4.7-4.el6.x86_64软件包的方法与步骤
- 基于ASP.Net MVC和Ajax技术的高校管理系统
- Zachery Zbinden的学术网站:探索JavaScript领域
- 深入分析GMT0104-2021云服务器密码机技术规范
- Android 2.1版摄像机功能使用指南
- 注入辅助工具内部版:深度应用与优化
- 探索AGV自动引导小车在Solidworks中的应用
- Android文件存储实现日程安排应用解析
- React开发入门与项目脚本使用指南
- ANN7.8稳定版发布:性能提升,安全优化
- mina框架源码深度解析及安卓交互应用
- MATLAB源码实现GMDH自组织网络模型预测时间序列
- Python101研讨会代码挑战解析
- CSS3动画实现3D骰子滚动效果教程
