LDA模型原理与应用详解
LDA(Latent Dirichlet Allocation)是一种在文本挖掘和机器学习领域广泛应用的主题模型,用于分析文档集合中的潜在主题和话题分布。本篇文章由哈尔滨工业大学智能技术与自然语言处理实验室的报告人轩文烽于2010年12月15日讲解,主要围绕以下几个部分展开:
1. **背景**:LDA的目标是解决如何从一组文档中识别出隐藏的主题,以及这些主题随时间的变化和文档之间的关联。文档集合的内容被假设包含多个主题,而LDA旨在揭示这些主题及其在文档中的表现。
2. **准备知识**:
- **概率分布**:理解基本的概率概念,如多项分布,它用于计算随机事件发生的概率。
- **Bayesian Network**:贝叶斯网络是概率图模型,用来表示变量之间的依赖关系,对LDA建模过程有重要作用。
- **Expectation-Maximization (EM)算法**:一种常用的迭代优化算法,用于参数估计,在LDA中用于最大化似然函数。
- **Variational Inference**:这是一种近似方法,通过优化变分分布来估计模型参数,简化了计算复杂性。
3. **LDA模型原理**:
- LDA假定每个文档由多个主题组成,而每个主题又由一组词语组成。
- 使用Dirichlet分布作为先验,模型通过观测到的词频来推断文档中的主题分布和主题内的词语分布。
- EM算法在这个框架下工作,通过迭代的方式更新主题分布和词语分配,直到收敛。
4. **简单应用**:
- 举例说明如何将LDA应用于实际场景,如新闻分类、社交媒体分析或学术论文主题聚类,展示模型如何帮助理解和组织大量文本数据。
5. **Further Reading** 和 **有用资源**:
- 提供了一些进一步阅读材料,帮助读者深入了解LDA的理论和实践应用,包括相关研究论文和开源工具。
6. **主要参考资料**:
- 列出了关键参考文献,供深入研究者参考,涵盖了LDA理论的基础和最新进展。
总结起来,这篇文档介绍了LDA的基本概念、建模原理、实现方法以及其在实际问题中的应用。掌握这些知识,可以帮助分析者挖掘文本数据中的主题结构,并理解文档集合中主题的动态变化。

概率分布—Dirichlet分布
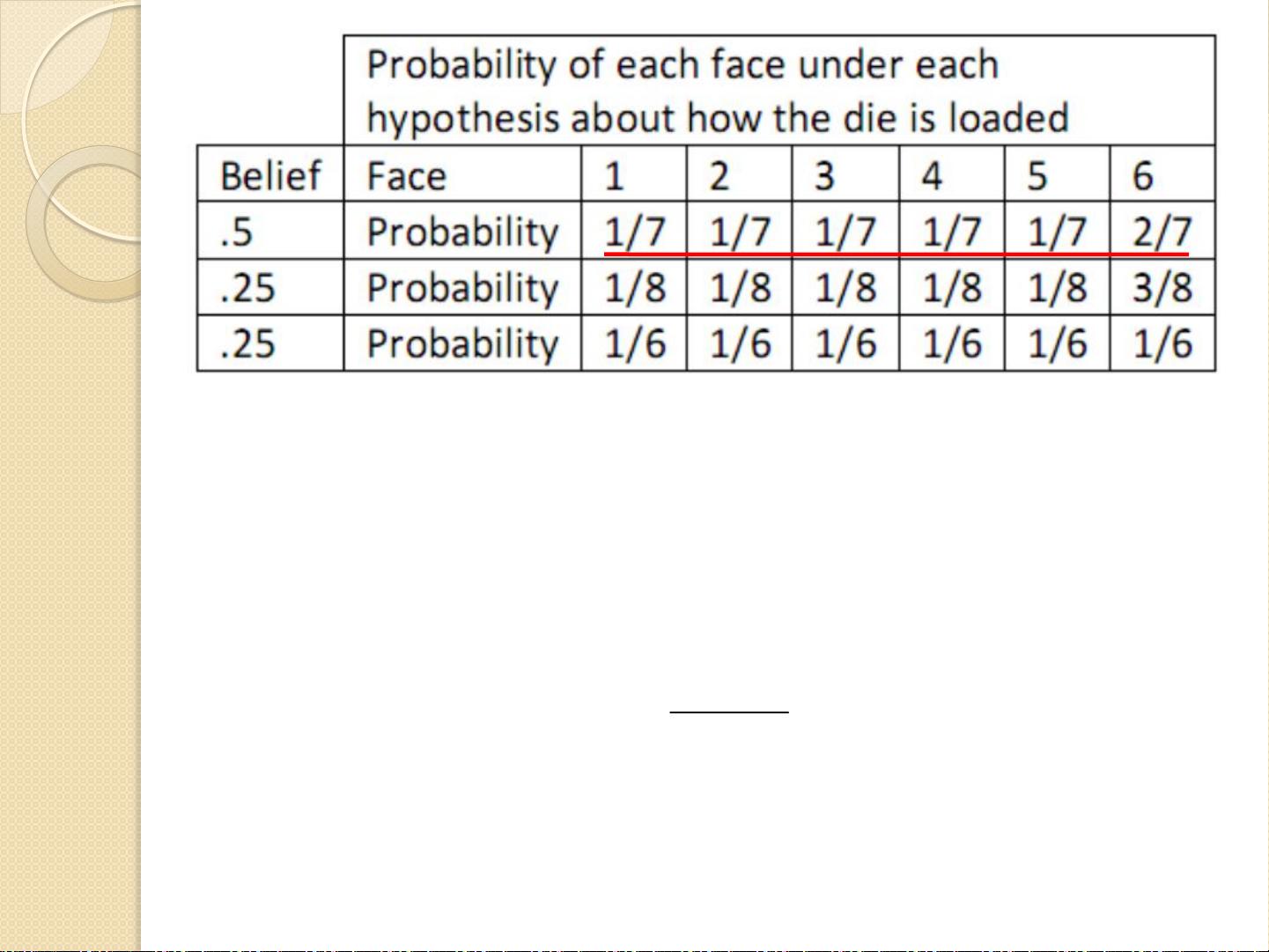
假设我们在和一个人玩掷骰子游戏。正
常情况下我们都会认为骰子的每个面出
现的概率是相等的,为1/6;但是现在
我们看到掷骰子的人连续掷出6,不免
心生猜测:
50%的可能:6出现的概率为2/7,其他
各面为1/7;
25%的可能:6出现的概率为3/8,其他
各面为1/8;
25%的可能:各面的概率为1/6
剩余42页未读,继续阅读
2021-10-03 上传
2020-12-23 上传
2021-09-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情









