基于Spark的电影社区网站个性化推荐与用户性别预测
需积分: 13 159 浏览量
更新于2024-08-05
5
收藏 1.75MB DOCX 举报
本Spark课程设计旨在构建一个电影社区网站,该网站不仅提供电影介绍、评论、影讯查询和购票服务,还致力于提升用户满意度。设计的核心目的是通过数据预处理和个性化推荐算法来实现用户性别分类和评价分类结果的准确性,从而提供更精准的电影推荐。
设计要求包括:
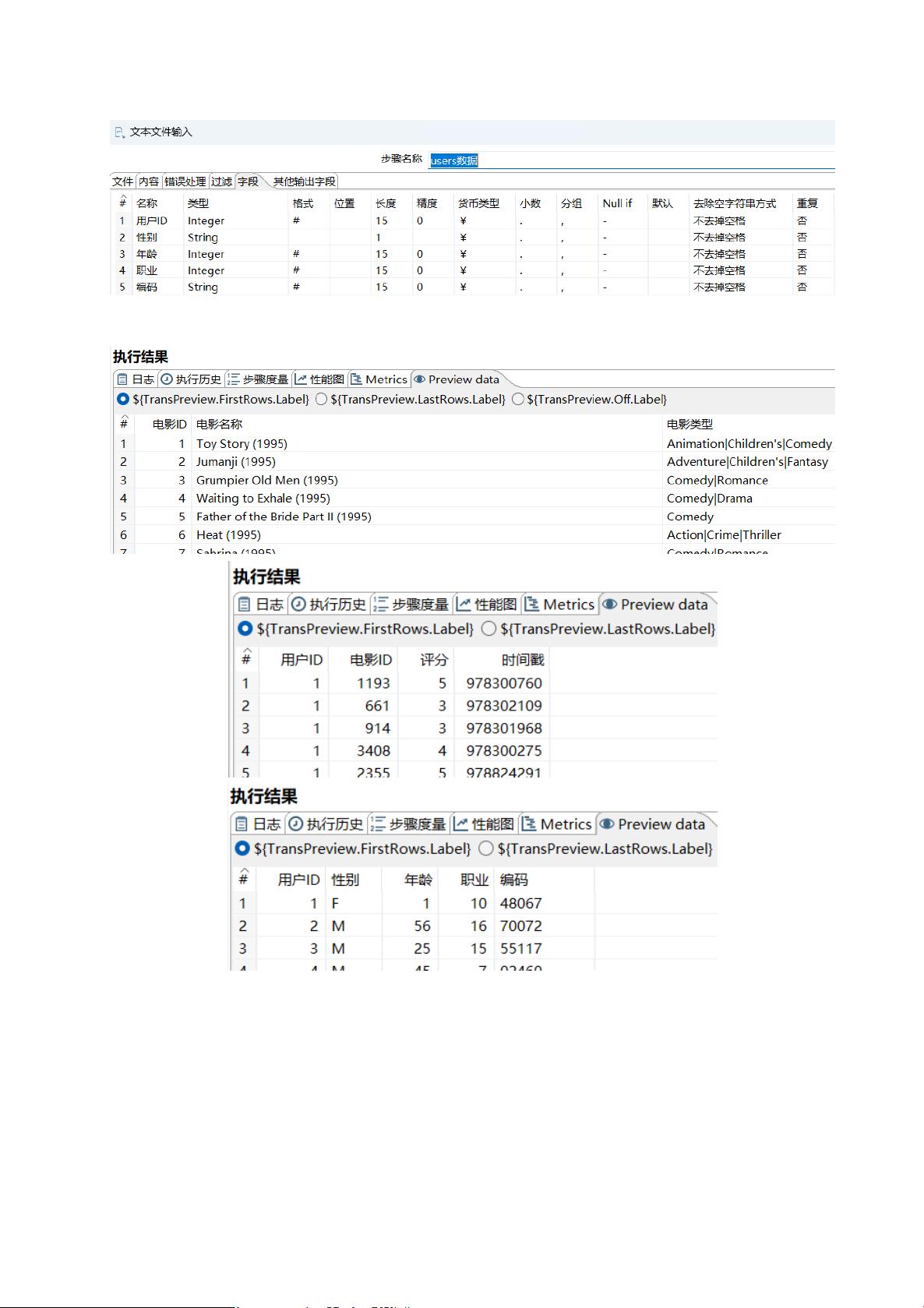
1. 数据预处理:首先,项目涉及到三个主要数据文件——Users.dat、movies.dat和ratings.dat。这些文件包含了用户的基本信息(如用户ID、性别、年龄、职业)、电影信息(电影ID、名称、类别)以及用户评分记录。数据预处理阶段需要对这些文件进行整理,去除冗余信息,确保数据一致性,并将非结构化数据如性别字段转换为数值形式。
2. 用户性别分类:利用Spoon工具,通过JavaScript代码统计用户观看不同电影类型的数量,然后通过值映射组件将用户性别F转换为0,M转换为1,便于后续的分析和模型构建。
3. 评价分类准确性:通过KNN算法实现电影推荐,这涉及到创建Distance()函数来计算欧氏距离,以及KNN函数来确定最接近用户的电影类型。主体代码会根据用户的历史行为和偏好,找出与其最相似的其他用户,从而推荐相似类型的电影。
设计内容具体分为两部分:
- 电影网站用户性别预测:在Scala环境中,使用Spark进行编程,首先导入必要的库,然后执行数据预处理、性别分类、数据库操作和结果展示。整个过程包括数据加载、清洗、转换,以及与MySQL数据库的交互。
- KNN算法应用:在Spark中,构建KNN算法用于电影推荐,通过计算用户间的相似性,基于用户的观影历史和评分,预测他们可能感兴趣的电影类型。预测结果会被写入数据库中的person表,以支持实时的个性化推荐。
此课程设计不仅锻炼了学生的Spark编程技能,还涵盖了数据分析、数据挖掘和机器学习的基础应用,帮助用户更好地理解和发掘用户行为数据的价值,提升用户体验。通过这个项目,学生能够深入理解数据预处理的重要性和个性化推荐算法在实际场景中的实践。
第 3 页
分别查看数据:
2)使用排序记录对 ratings 组件进行排序
剩余12页未读,继续阅读
2219 浏览量
243 浏览量
2024-07-31 上传
221 浏览量
427 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
121 浏览量

司空良
- 粉丝: 1592
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Notebook 基础知识
- JMAIL源码 电子邮件系统 带附件
- Addison.Wesley.xUnit.Test.Patterns.Refactoring.Test.Code.May.2007.pdf
- 3D游戏程序设计入门DirectX9
- 一个树行菜单共享文件
- asp .net完全入门教程 pdf
- 06-07年程序员考试题(1)答案?
- 06-07年程序员考试题(1)答案???
- J-Link用户手册最新版
- linuxas3.0-oracle9204
- 开始嵌入式的学习生涯(触摸屏)
- Allegro 中关于XNet 的等长设置.pdf
- 英文资料日本东芝编写的NAND FLASH与 NOR FLASH的对比
- java面试题及答案(基础题122道, 19道)
- 51MCS——汇编.pdf
- powershell红皮书
