数据挖掘实战:Python实现算法总结
需积分: 9 90 浏览量
更新于2024-07-18
收藏 5.08MB PDF 举报
"该资源是一份关于数据挖掘算法的详细指南,主要针对使用Python实现的机器学习和数据挖掘技术。内容涵盖了从统计基础到实际应用的各个层面,包括监督学习中的分类与回归算法(如KNN、决策树、朴素贝叶斯、逻辑回归和SVM),非监督学习中的聚类(如K-means)和关联分析,以及数据预处理、数据结构与算法和SQL知识。此外,还提供了多个案例分析,如泰坦尼克号生存率分析、飞机事故分析、贷款预测以及葡萄酒价格模型预测等,旨在帮助读者通过实践加深对数据挖掘的理解。"
在数据挖掘和机器学习领域,统计基础是理解各种算法的核心。概率论是这一领域的基石,它描述了事件发生的可能性。样本空间是所有可能结果的集合,事件是样本空间的子集,可以分为空事件、原子事件、混合事件和样本空间本身。概率的定义基于对大量重复实验的观察,例如投硬币,正面朝上的概率可以通过长期试验来估计。
在监督学习中,KNN是一种基于实例的学习,通过找到训练集中与新样本最近的k个邻居来预测其类别。决策树利用树状结构进行决策,每个内部节点代表一个特征,每个分支代表一个特征值,而叶节点则代表一个类别。朴素贝叶斯分类器假设特征之间相互独立,并基于贝叶斯定理进行分类。逻辑回归用于二分类问题,SVM(支持向量机)通过构造最大边距超平面来划分数据,尤其适用于高维数据。
非监督学习中的K-means聚类是一种常见的无监督算法,用于将数据集划分为k个不重叠的簇。关联规则学习如Apriori算法,常用于市场篮子分析,寻找商品之间的频繁购买模式。
在实际应用中,Python是数据科学家的首选语言,其强大的数据分析库如Pandas、Numpy和Scikit-learn使得数据预处理和模型构建变得简单。数据清洗是预处理的关键步骤,涉及处理缺失值、异常值和重复值。了解基本的数据结构和算法(如二叉树和排序)有助于提升数据处理效率。SQL语言用于数据库操作,对于获取和管理大量数据至关重要。
案例分析部分提供了实际问题的解决思路,帮助读者将理论知识应用于实际场景,如泰坦尼克号乘客生存预测,分析飞机事故数据,预测贷款违约风险,以及使用KNN预测葡萄酒价格等。这些案例展示了如何整合所学知识,解决复杂问题。
这份文档是学习数据挖掘和机器学习的全面资源,不仅讲解了理论知识,还提供了丰富的实践内容,有助于提升读者在数据科学领域的技能。
第三部分 监督学习---分类与回归
有监督就是给的样本都有标签,分类的训练样本必须有标签,所以分类算法都是有监督算法。监
督机器学习无非就是“minimize your error while regularizing your parameters”,也就是在规则化参数的
同时最小化误差。最小化误差是为了让我们的训练数据,而规则化参数是防止我们的模型过分拟合我
们的训练数据,提高泛化能力
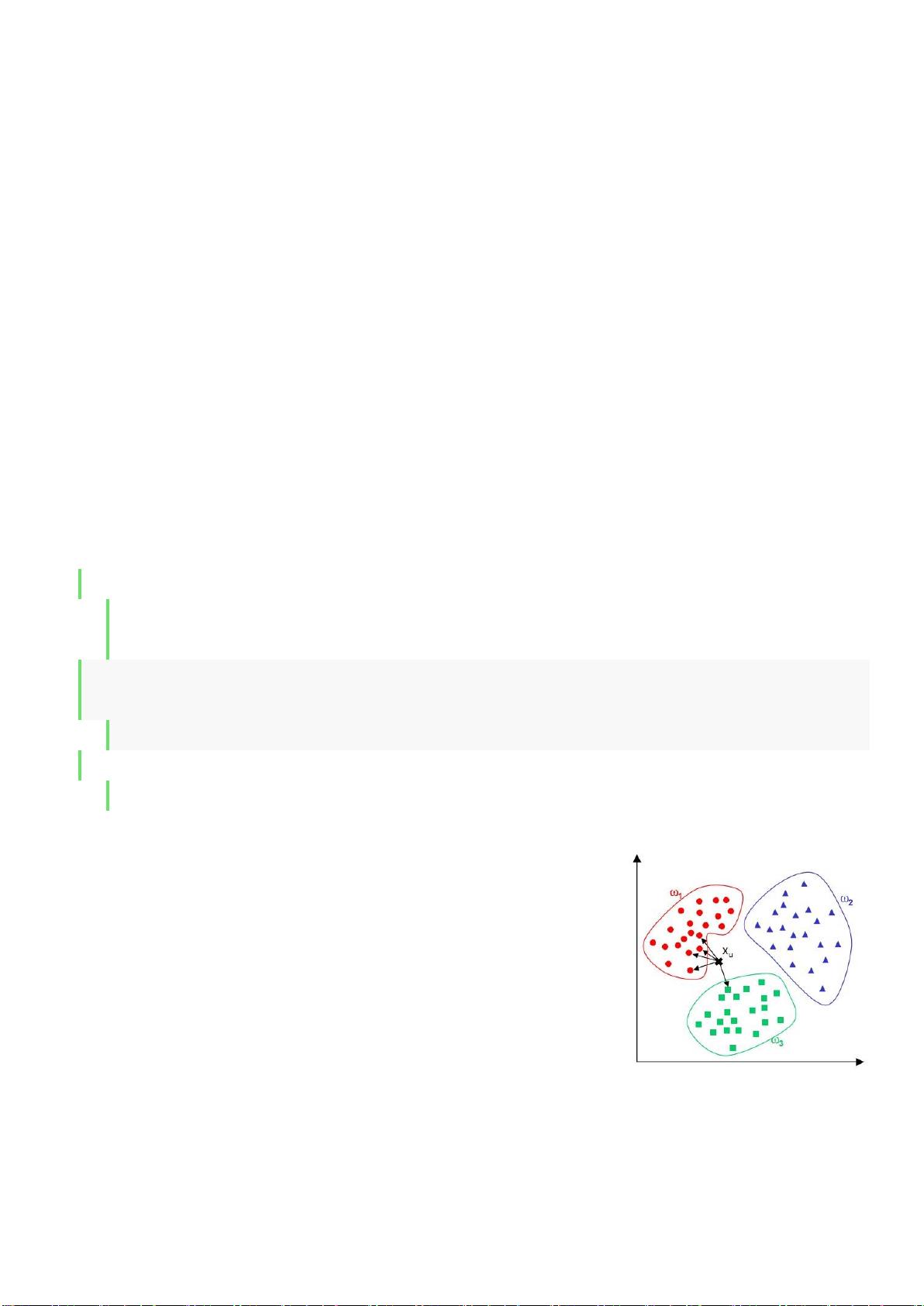
第四章 KNN(k 最邻近分类算法)
1.算法思路
通过计算每个训练样例到待分类样品的距离,取和待分类样品距离最近的 K 个训练样例,K 个
样品中哪个类别的训练样例占多数,则待分类样品就属于哪个类别
核心思想:如果一个样本在特征空间中的 k 个最相邻的样本中的大多数属于某一个类别,则该样本
也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或
者几个样本的类别来决定待分样本所属的类别。 kNN 方法在类别决策时,只与极少量的相邻样本
有关。由于 kNN 方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,
因此对于类域的交叉或重叠较多的待分样本集来说,kNN 方法较其他方法更为适合。
2.算法描述
1. 算距离:给定测试对象,计算它与训练集中的每个对象的距离
依公式计算 Item 与 D1、D2 … …、Dj 之相似度。得到 Sim(Item, D1)、Sim(Item, D2)… …、
Sim(Item, Dj)。
2. 将 Sim(Item, D1)、Sim(Item, D2)… …、Sim(Item, Dj)排序,若是超过相似度阈值 t 则放入邻居
案例集合 NN。
找邻居:圈定距离最近的 k 个训练对象,作为测试对象的近邻
3. 自邻居案例集合 NN 中取出前 k 名,依多数决,得到 Item 可能类别。
做分类:根据这 k 个近邻归属的主要类别,来对测试对象分类
3.算法步骤
• step.1---初始化距离为最大值
• step.2---计算未知样本和每个训练样本的距离 dist
• step.3---得到目前 K 个最临近样本中的最大距离 maxdist
• step.4---如果 dist 小于 maxdist,则将该训练样本作为 K-最近邻样本
• step.5---重复步骤 2、3、4,直到未知样本和所有训练样本的距离都算完
• step.6---统计 K-最近邻样本中每个类标号出现的次数
• step.7---选择出现频率最大的类标号作为未知样本的类标号
该算法涉及 3 个主要因素:训练集、距离或相似的衡量、k 的大小。
4. k 邻近模型三个基本要素
三个基本要素为
距离度量、
k
值的选择和分类决策规则
距离度量:
设特征空间是 n 维实数向量空间
,
,
,
欢迎加入非盈利Python编程学习交流QQ群783462347,群里免费提供500+本Python书籍!




剩余111页未读,继续阅读
2014-03-17 上传
2021-07-14 上传
2023-11-19 上传
2023-12-04 上传
2023-05-20 上传
2024-03-31 上传
2023-06-07 上传
2023-06-01 上传
2023-05-19 上传

weixin_42271300
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
