Google Bigtable:分布式结构化数据存储系统中文解析
"Google的三大论文中文版包含了对Google核心数据存储和处理技术的深度解析,是理解大规模分布式系统的基石。本文主要聚焦于其中的一篇——《Bigtable:一个分布式的结构化数据存储系统》的中文翻译,该论文详细介绍了Bigtable的设计理念、数据模型以及其实现方式。
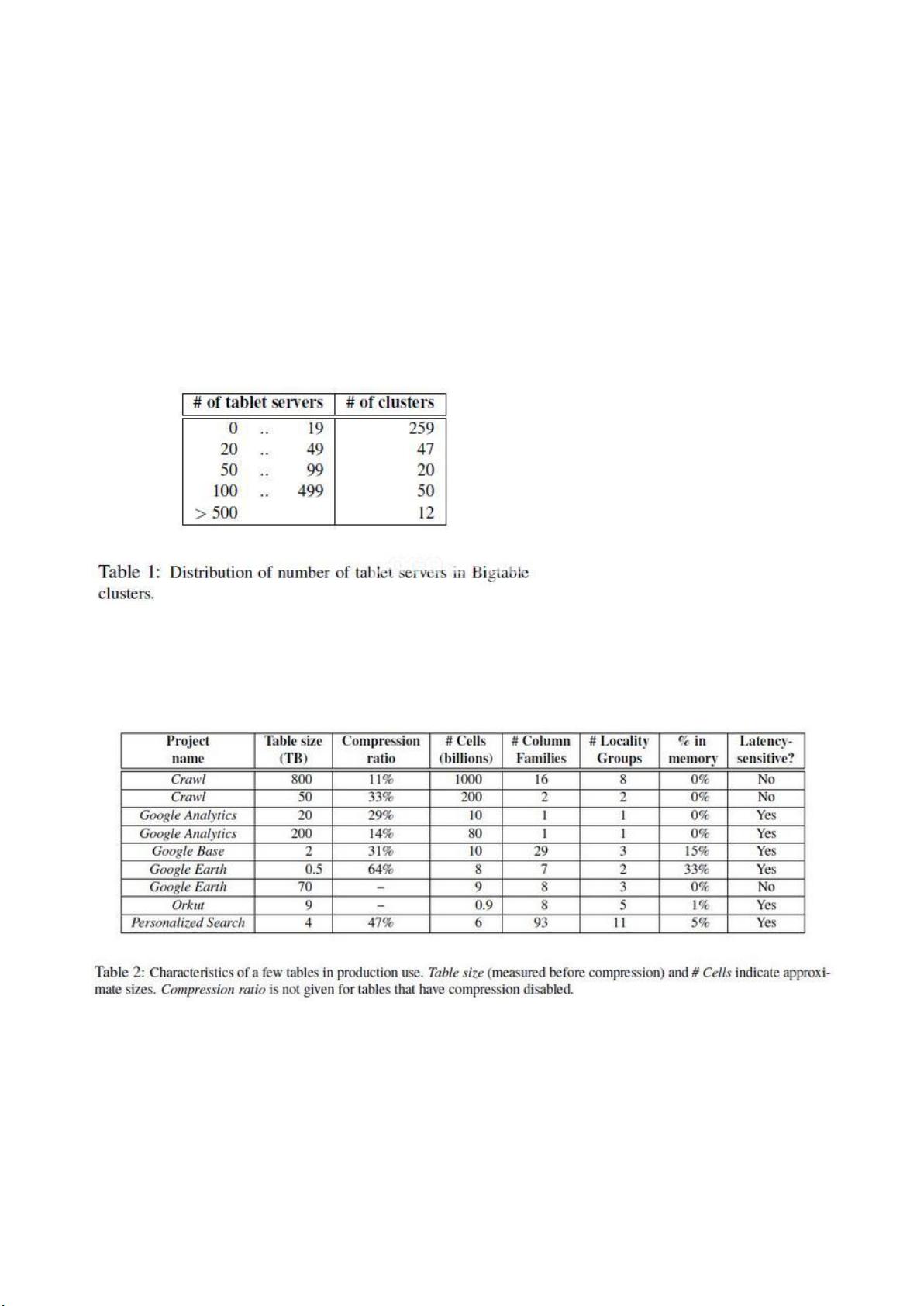
Bigtable是一个高度可扩展、高性能的分布式存储系统,主要用于处理海量的数据,通常在数千台服务器上运行,存储的数据量可达PB级别。它被众多Google服务如Web索引、Google Earth和Google Finance等广泛采用,满足了各种不同需求,从批量处理到实时数据服务。
Bigtable的数据模型并不遵循传统的关系型数据库模型,而是提供了一个更简单、更灵活的结构,允许用户动态地控制数据的分布和格式。它基于一个表格模型,表格由行和列组成,每个单元格都有一个时间戳,这样的设计使得数据的版本管理和时间序列数据处理变得可能。
在设计上,Bigtable采用了分布式架构,通过Chubby锁服务保证分布式一致性,使用GFS(Google File System)作为底层存储,同时运用了Master-Slave复制策略来确保高可用性。表的分区是通过行键的散列实现的,保证了数据的均衡分布。此外,Bigtable还使用了SSTable(Sorted String Table)作为磁盘上的数据格式,提供了高效的读写操作。
Bigtable的核心组件包括客户端库、主服务器(Master)、tablet服务器和GFS。主服务器负责管理表的分区和服务器的元数据,tablet服务器则实际处理数据的读写请求。这种架构使得Bigtable能够轻松应对数据规模的扩大和负载的增长。
论文详细讨论了Bigtable如何通过数据压缩、缓存策略和多线程读写优化性能,以及如何通过故障检测和自动恢复机制保证服务的连续性。它还提到了Bigtable如何处理CAP定理的权衡,特别是在高可用性和分区容忍性之间。
Bigtable是Google解决大规模数据存储和处理问题的一个关键技术创新,它的设计理念和实现技术对后来的分布式数据库系统,如HBase和Cassandra,产生了深远的影响。通过阅读这篇论文,读者可以深入理解大规模分布式存储系统的设计原则和挑战,对于从事云计算、大数据和分布式计算领域的技术人员来说,是一份不可多得的学习资料。"

个日志记录都有一个序列号,因此,在恢复的时候,Tablet服务器能够检测出并忽略掉那些由于线程切换
而导致的重复的记录。
Tablet
恢复提速
当Master服务器将一个Tablet从一个Tablet服务器移到另外一个Tablet服务器时,源Tablet服务器会对这
个Tablet做一次Minor Compaction。这个Compaction操作减少了Tablet服务器的日志文件中没有归并
的记录,从而减少了恢复的时间。Compaction完成之后,该服务器就停止为该Tablet提供服务。在卸载
Tablet之前,源Tablet服务器还会再做一次(通常会很快)Minor Compaction,以消除前面在一次压缩
过程中又产生的未归并的记录。第二次Minor Compaction完成以后,Tablet就可以被装载到新的Tablet
服务器上了,并且不需要从日志中进行恢复。
利用不变性
我们在使用Bigtable时,除了SSTable缓存之外的其它部分产生的SSTable都是不变的,我们可以利用这
一点对系统进行简化。例如,当从SSTable读取数据的时候,我们不必对文件系统访问操作进行同步。这
样一来,就可以非常高效的实现对行的并行操作。memtable是唯一一个能被读和写操作同时访问的可变
数据结构。为了减少在读操作时的竞争,我们对内存表采用COW(Copy-on-write)机制,这样就允许读写
操作并行执行。
因为SSTable是不变的,因此,我们可以把永久删除被标记为“删除”的数据的问题,转换成对废弃的
SSTable进行垃圾收集的问题了。每个Tablet的SSTable都在METADATA表中注册了。Master服务器采用
“标记-删除”的垃圾回收方式删除SSTable集合中废弃的SSTable【25】,METADATA表则保存了Root
SSTable的集合。
最后,SSTable的不变性使得分割Tablet的操作非常快捷。我们不必为每个分割出来的Tablet建立新的
SSTable集合,而是共享原来的Tablet的SSTable集合。
7 性能评估
为了测试Bigtable的性能和可扩展性,我们建立了一个包括N台Tablet服务器的Bigtable集群,这里N是可
变的。每台Tablet服务器配置了1GB的内存,数据写入到一个包括1786台机器、每台机器有2个IDE硬盘
的GFS集群上。我们使用N台客户机生成工作负载测试Bigtable。(我们使用和Tablet服务器相同数目的
客户机以确保客户机不会成为瓶颈。) 每台客户机配置2GZ双核Opteron处理器,配置了足以容纳所有进
程工作数据集的物理内存,以及一张Gigabit的以太网卡。这些机器都连入一个两层的、树状的交换网络
里,在根节点上的带宽加起来有大约100-200Gbps。所有的机器采用相同的设备,因此,任何两台机器
间网络来回一次的时间都小于1ms。
Tablet服务器、Master服务器、测试机、以及GFS服务器都运行在同一组机器上。每台机器都运行一个
GFS的服务器。其它的机器要么运行Tablet服务器、要么运行客户程序、要么运行在测试过程中,使用这
组机器的其它的任务启动的进程。
R是测试过程中,Bigtable包含的不同的列关键字的数量。我们精心选择R的值,保证每次基准测试对每台
Tablet服务器读/写的数据量都在1GB左右。
在序列写的基准测试中,我们使用的列关键字的范围是0到R-1。这个范围又被划分为10N个大小相同的区
间。核心调度程序把这些区间分配给N个客户端,分配方式是:只要客户程序处理完上一个区间的数据,
调度程序就把后续的、尚未处理的区间分配给它。这种动态分配的方式有助于减少客户机上同时运行的其
它进程对性能的影响。我们在每个列关键字下写入一个单独的字符串。每个字符串都是随机生成的、因此
也没有被压缩
(
alex
注:参考第
6
节的压缩小节)
。另外,不同列关键字下的字符串也是不同的,因此也
就不存在跨行的压缩。随机写入基准测试采用类似的方法,除了行关键字在写入前先做Hash,Hash采用
按R取模的方式,这样就保证了在整个基准测试持续的时间内,写入的工作负载均匀的分布在列存储空间
内。
序列读的基准测试生成列关键字的方式与序列写相同,不同于序列写在列关键字下写入字符串的是,序列

剩余59页未读,继续阅读
2014-04-24 上传
2016-12-01 上传
2017-05-03 上传
2023-02-14 上传
2023-05-25 上传
2024-03-11 上传
2023-02-17 上传
2023-03-31 上传
2023-05-11 上传

rode_lw
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
