Impala:实时大数据查询利器,架构解析与应用优势
163 浏览量
更新于2024-08-28
收藏 321KB PDF 举报
Impala是Cloudera公司主导的一款大数据实时查询分析工具,其设计初衷是为了显著提升基于MapReduce的Hive SQL查询速度,通常能实现3到90倍的性能提升,同时提供高效、灵活且易于整合的特性。以下是关于Impala的详细知识点:
1. **查询速度优化**:
- Impala与Hive的主要区别在于其底层执行机制。Hive依赖MapReduce进行批处理,而Impala采用流式处理方式,避免了中间结果写入磁盘,减少了节点间的I/O开销,从而实现了更快的响应时间。
2. **灵活性**:
- Impala支持直接访问HDFS上的原始数据,也兼容经过优化的存储结构,如与MapReduce、Hive和Pig的格式兼容,使得数据源的选择更加灵活。
3. **易整合性**:
- Impala无缝集成到Hadoop生态系统,用户无需迁移数据即可利用现有的Hadoop资源进行查询分析,提高了工作效率。
4. **可扩展性**:
- Impala的架构设计注重高可用性和容错性,任何一个节点故障都不会影响查询处理。此外,它能与商业智能(BI)应用如Microstrategy、Tableau和Qlikview等协作,满足大规模数据分析需求。
5. **架构详解**:
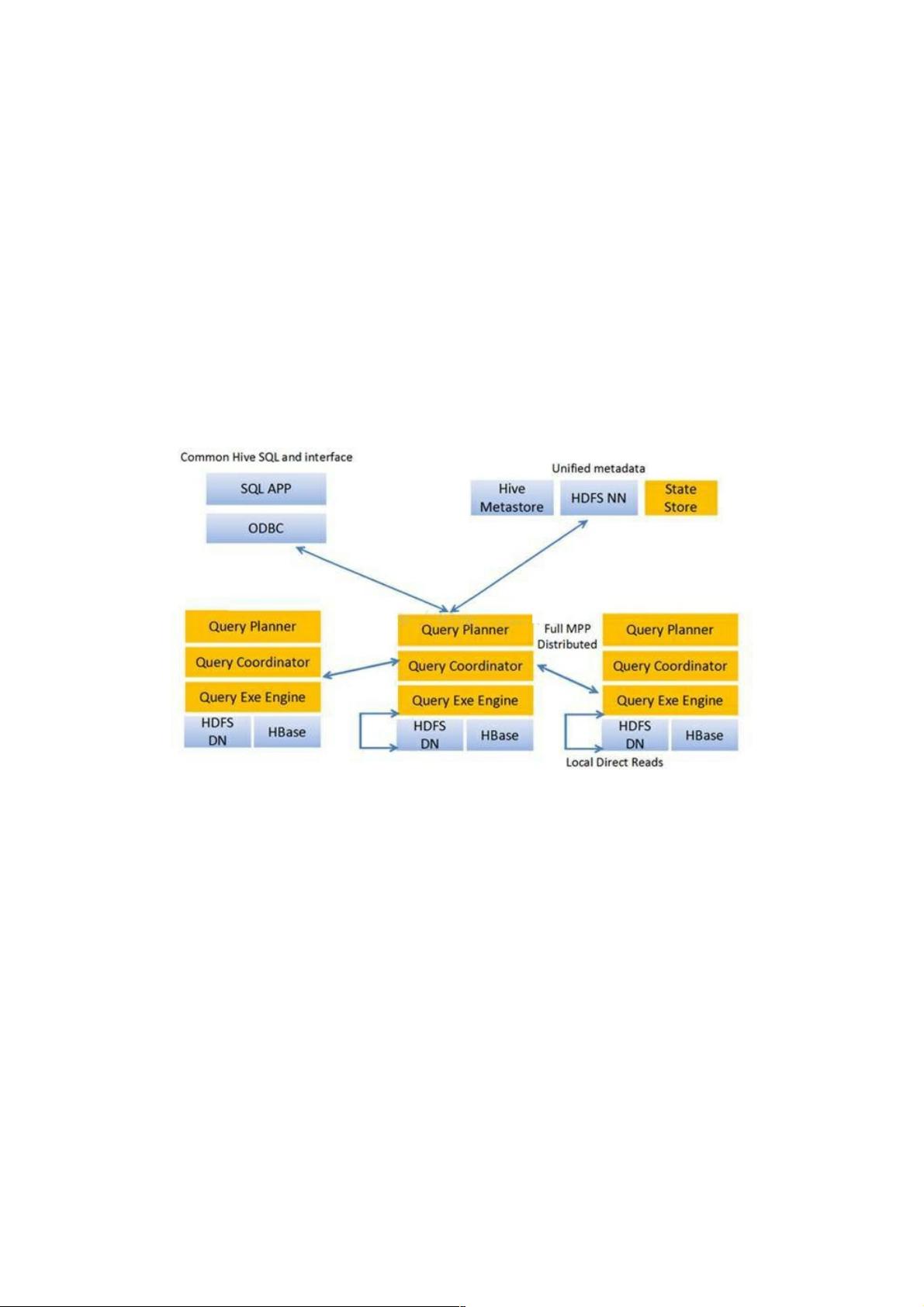
- Impala架构主要包括impalad(核心进程),statestore(用于存储元数据)和CLI(命令行接口)。impalad在Datanode上运行,接收查询请求,协调执行计划并执行查询,通过网络将结果返回给协调器。这些组件的分布和冗余设计确保了系统的高可用性。
6. **组件功能**:
- QueryPlanner负责解析SQL并生成执行计划,QueryCoordinator则负责调度任务,QueryExecutor负责实际的查询执行。这些组件之间紧密协作,形成一个分布式、并行化的查询处理框架。
Impala凭借其快速响应、灵活性和高度可扩展性,成为大数据实时查询分析的理想选择,尤其适用于需要快速分析PB级数据的场景。
impala的原理架构介绍及应用场景的原理架构介绍及应用场景
impala概述
由cloudera公司主导开发的大数据实时查询分析工具,宣称比原来基于MapReduce的HiveSQL查询速度提升3~90倍,且更加
灵活易用。提供类SQL的查询语句,能够查询存储在Hadoop的HDFS和Hbase中的PB级大数据。查询速度快是其最大的卖
点。简言之impala作为大数据实时查询分析工具,具有查询速度快,灵活性高,易整合,可伸缩性强等特点。
1.查询速度快。Impala不同于hive,hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程。不同于hive,impala中
间结果不写入磁盘,即使及时通过网络以流的形式传递,大大降低的节点的IO开销。
2.灵活性高。可以直接查询存储在HDFS上的原生数据,也可以查询经过优化设计而存储的数据,只需要数据的格式能够兼容
MapReduce、hive、Pig等等。
3.易整合。很容易和hadoop系统整合,并使用hadoop生态系统的资源和优势,不需要将数据迁移到特定的存储系统就能满足
查询分析的要求。
4.可伸缩性。可以很好的与一些BI应用系统协同工作,如Microstrategy、Tableau、Qlikview等。
架构介绍
impala架构图:
1.从上图可以看出,位于Datanode上的每个impalad进程,都具有Query Planner,QueryCoordinator,Query ExecEnginer这几
个组件,每个impala节点在功能上是对等的,也就是说,任何一个节点都能接受外部查询请求。当有一个节点发生故障后,其
他节点仍然能够接管,这还得益于HDFS的数据冗余备份机制,即使某个impalad节点挂掉,只要挂掉的节点上的数据在其他
节点上有备份,仍然是可以计算的。
2.Impala由impalad,statestore,CLI组成。下面分别概述各自的功能:
impalad是impala的核心进程,与Datanode在同一个节点上,接受客户端的查询请求(接受查询请求的impalad为
Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器吧执行计划分发给具有相应
数据的其他impalad执行),读写数据,并行执行查询,并把结果通过网络流式传给Coordinator,有Coordinator返回给客户端。
同时impalad也与statestore保持连接,用于确定哪些impalad的健康的是可以执行新任务的。
state store跟踪集群中的impalad的健康状态及位置信息,并不断把健康状况发送给所有的impalad进程节点。一旦某个impala
节点不可用,statestore确保将这一信息及时传达到所有的impalad进程节点,当有新的查询请求时,impalad进程节点不会把
查询请求发送到不可用的节点上。statestore通过创建多个线程来处理impalad的注册订阅和与各个impalad保持心态连接。值
得注意的是,statestore并非关键进程,即使不可用,impalad进程节点间仍然可以相互协调正常对外提供分布式查询。
CLI:用户查询的命令行共组,还提供了Hue、JDBC、ODBC等接口。
与hive的比价:
下载后可阅读完整内容,剩余3页未读,立即下载
2018-09-18 上传
2023-05-29 上传
2023-06-05 上传
2024-08-10 上传
2023-03-30 上传
2023-04-03 上传
2023-09-01 上传

weixin_38713393
- 粉丝: 8
- 资源: 878
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
