




Transformer架构解析:注意力即一切
需积分: 45 146 浏览量
更新于2024-09-11
3
收藏 1.34MB PDF 举报
"Attention Is All You Need" 是一篇由 Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Łukasz Kaiser 和 Illia Polosukhin 等人合作撰写的深度学习论文,发表于第31届神经网络信息处理系统会议(Neural Information Processing Systems, NIPS 2017)。这篇开创性的文章提出了Transformer架构,这是一种基于自注意力机制(Self-Attention)的序列建模方法,彻底改变了自然语言处理(NLP)领域的处理方式。
在传统的循环神经网络(RNN)中,长期依赖问题一直是限制其性能的重要因素。然而,Transformer通过抛弃RNN中的递归结构,引入了全连接注意力机制,使得模型能够同时考虑输入序列中的所有元素,无需逐个向前或向后传递信息。这一创新不仅提高了模型的计算效率,而且在诸如机器翻译等任务上取得了显著的性能提升。
文中提到的主要贡献包括:
1. **Self-Attention**:由Jakob Uszkoreit提出,作为一种新颖的注意力机制,它允许模型直接对输入序列中的任意位置进行交互,而不仅仅是依赖先前的上下文信息。这使得模型能够捕捉到更全局的上下文关系。
2. **Multi-Head Attention**:Ashish Vaswani和Illia Polosukhin共同设计,将注意力分为多个独立的“头”(heads),每个头专注于不同类型的特征,从而增强了模型的表达能力。
3. **Positional Encoding**:Noam Shazeer提出了一种参数化的位置编码方法,用于在不依赖于循环结构的情况下提供序列的顺序信息,解决了Transformer中缺乏明确顺序信息的问题。
4. **Tensor2Tensor**:Niki Parmar、Llion Jones和Aidan N. Gomez负责设计和优化了Tensor2Tensor库,这是一个用于大规模训练Transformer和其他复杂模型的框架,极大地推动了研究的进展。
5. **高效推理与可视化**:Llion Jones致力于开发更高效的推理算法和模型可视化工具,帮助团队理解模型内部的工作原理。
6. **Google Brain和Google Research背景**:所有作者在Google的研究环境中工作,他们的成果为自然语言处理领域带来了革命性的突破,加速了Transformer模型在业界的应用。
"Attention Is All You Need"这篇论文通过介绍Transformer架构,开启了深度学习中自注意力机制的新篇章,对现代NLP的发展产生了深远影响。其核心思想是将模型的关注点集中于处理序列数据时的全局上下文关联,从而实现了性能上的显著提升。
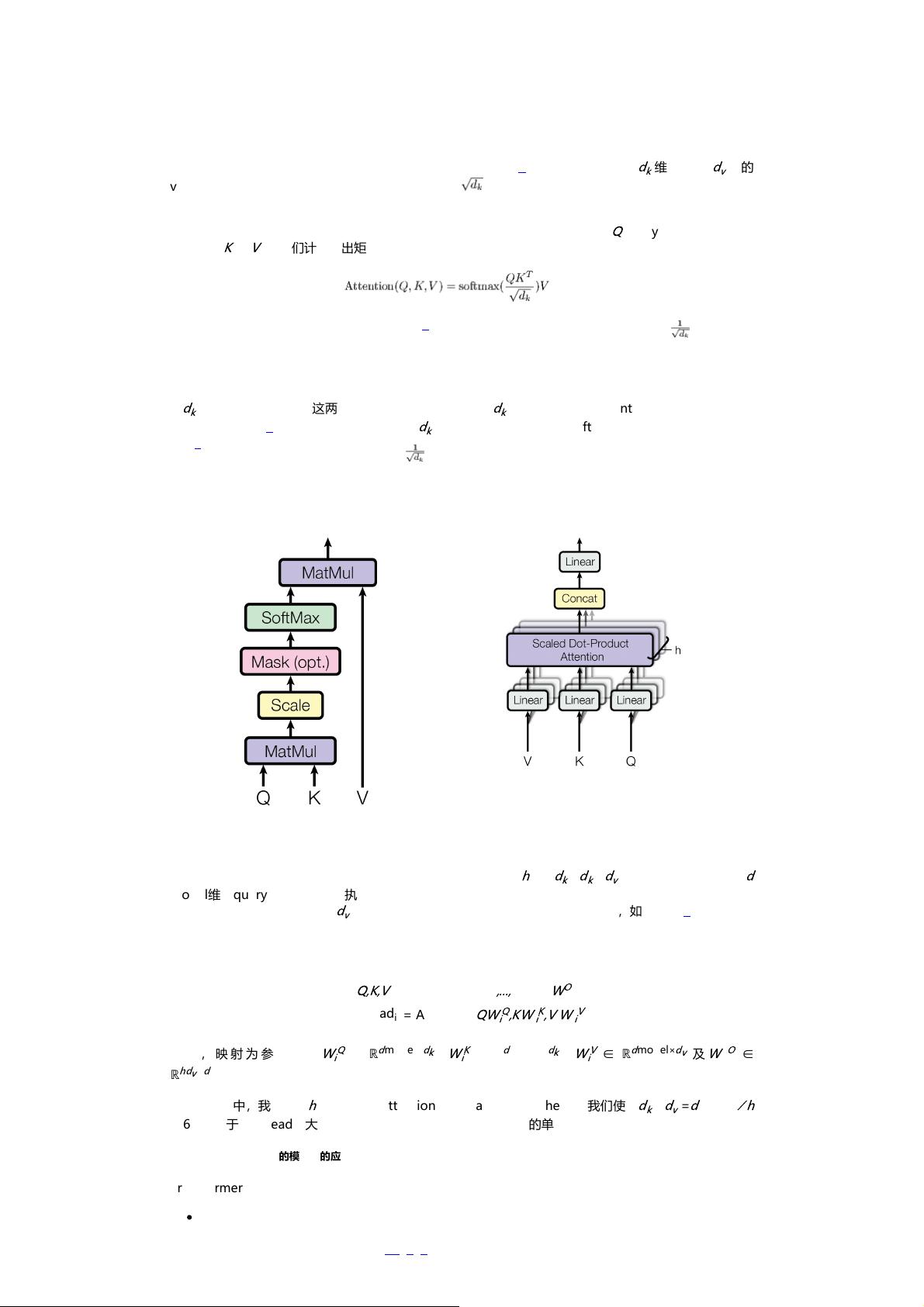
3.2 Attention
Attention函数可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向
量。 输出为value的加权和,其中分配给每个value的权重通过query与相应key的兼容函数来计算。
3.2.1 缩放版的点积attention
我们称我们特殊的attention为“缩放版的点积attention”(图 2)。 输入由query、
d
k
维的key和
d
v
维的
value组成。 我们计算query和所有key的点积、用 相除,然后应用一个softmax函数以获得值的权
重。
在实践中,我们同时计算一组query的attention函数,并将它们组合成一个矩阵
Q
。 key和value也一起打
包成矩阵
K
和
V
。 我们计算输出矩阵为:
(1)
两个最常用的attention函数是加法attention[2]和点积(乘法)attention。 除了缩放因子 之外,点积
attention与我们的算法相同。 加法attention使用具有单个隐藏层的前馈网络计算兼容性函数。 虽然两者
在理论上的复杂性相似,但在实践中点积attention的速度更快、更节省空间,因为它可以使用高度优化的
矩阵乘法代码来实现。
当
d
k
的值比较小的时候,这两个机制的性能相差相近,当
d
k
比较大时,加法attention比不带缩放的点积
attention性能好[3]。 我们怀疑,对于很大的
d
k
值,点积大幅度增长,将softmax函数推向具有极小梯度的
区域
4
。 为了抵消这种影响,我们缩小点积 倍。
3.2.2 Multi-Head Attention
缩放版的点积Attention
Multi-Head Attention
图2: (左)缩放版的点积attention。 (右)Multi-Head Attention,由多个并行运行的
attention层组成。
我们发现将query、key和value分别用不同的、学到的线性映射
h
倍到
d
k
、
d
k
和
d
v
维效果更好,而不是用
d
model维的query、key和value执行单个attention函数。 基于每个映射版本的query、key和value,我们
并行执行attention函数,产生
d
v
维输出值。 将它们连接并再次映射,产生最终值,如图所示 2。
Multi-head attention允许模型的不同表示子空间联合关注不同位置的信息。 如果只有一个attention
head,它的平均值会削弱这个信息。
MultiHead(
Q,K,V
) = Concat(head
1
,...,
head
h
)
W
O
其中
head
i
= Attention(
QW
i
Q
,KW
i
K
,V W
i
V
)
其 中 , 映 射 为 参 数 矩 阵
W
i
Q
∈ ℝ
d
model×
d
k
,
W
i
K
∈ ℝ
d
model×
d
k
,
W
i
V
∈ ℝ
d
model×
d
v
及
W
O
∈
ℝ
hd
v
×
d
model
。
在这项工作中,我们采用
h
= 8 个并行attention层或head。 对每个head,我们使用
d
k
=
d
v
=
d
model
⁄
h
= 64。 由于每个head的大小减小,总的计算成本与具有全部维度的单个head attention相似。
3.2.3 Attention在我们的模型中的应用
Transformer使用以3种方式使用multi-head attention:
在“编码器—解码器attention”层,query来自前一个解码器层,key和value来自编码器的输出。
这允许解码器中的每个位置能关注到输入序列中的所有位置。 这模仿序列到序列模型中典型的编码器
—解码器的attention机制,例如[38, 2, 9]。
下载后可阅读完整内容,剩余10页未读,立即下载
158 浏览量
2025-03-09 上传
975 浏览量
2024-07-04 上传
255 浏览量
395 浏览量

绝不原创的飞龙
- 粉丝: 4w+
 我的内容管理
展开
我的内容管理
展开








最新资源
- Delphi编程实现获取MAC地址教程
- 轻松部署:简单易用的代理服务器软件指南
- 专业U盘数据恢复工具—轻松恢复格式化或误删文件
- 个人网站的设计与JavaScript应用
- Ext JS初学者必备实用教程指南
- DCS-168E集团电话交换机软件V1.6.8更新发布
- 在Windows上安装和配置MongoDB教程
- PopChar输入特殊字符工具v6.2功能体验与安装教程
- 中型企业高性能数据存储方案对比:IBM TSM vs Symantec NBU6.0
- Direct3D游戏编程入门:源码解析与教程
- Holberton School算法面试准备特训
- 全面分享Java程序设计课后答案
- 轻巧华丽的1MB音乐播放器:AirPlayer使用体验
- ASP.NET实现拆线与柱状图展示及代码教程
- 金融公司java工程师不同级别笔试题解析
- Laravel框架精髓与学习资源:实践中的愉悦与创造力






















