改进时序交叉验证:对抗人工智能模型过拟合
需积分: 0 17 浏览量
更新于2024-06-22
收藏 1.15MB PDF 举报
"该文档是华泰证券发布的关于人工智能系列的研究报告,重点关注了时序交叉验证在对抗过拟合中的应用。报告由林晓明、陈烨等研究员撰写,探讨了如何改进时序交叉验证方法以优化模型性能,特别是对于时间序列数据的处理。"
在人工智能领域,特别是在时间序列数据分析中,过拟合是一个常见的问题,它会导致模型在训练数据上表现优秀,但在未知数据上表现糟糕。传统的K折交叉验证可能无法有效应对这个问题,因为它忽视了时间序列数据的顺序特性。时序交叉验证则是一种解决策略,它保持了数据的时间顺序,从而降低了过拟合的风险。
报告提出,从基线模型的设定和样本精确切分两个方面改进时序交叉验证。基线模型的选择至关重要,因为它影响模型的泛化能力。通过对比时序交叉验证、分组时序交叉验证以及四种不同的基线模型,研究人员发现分组时序交叉验证在防止过拟合方面表现更优,且优于时序交叉验证和其他基线模型。
模型性能的评估显示,尽管时序交叉验证在样本内表现不如其他方法,但在测试集上的表现却优于K折交叉验证,这表明它在一定程度上缓解了过拟合。而分组时序交叉验证在测试集上的表现最佳,进一步证明了保留时间顺序信息对于模型性能的重要性。
报告还引入了新的基线模型,通过减少样本数量来对比,发现即使样本减少,模型性能仍可优于K折,这说明模型复杂度的降低有助于减少过拟合。同时,时序和分组时序交叉验证由于保留了时间顺序信息,其性能优于这些新基线模型,强调了时间序列数据的顺序性在模型训练中的关键作用。
分组时序交叉验证的优势在于,它确保验证集在时间序列上的连续性,这有助于模型更好地理解和预测序列模式,从而提高泛化能力。因此,在处理时间序列数据的机器学习模型调参过程中,推荐使用分组时序交叉验证来有效对抗过拟合,提升模型的稳定性和预测准确性。
这篇报告深入探讨了时序数据的特性以及如何利用时序交叉验证和分组时序交叉验证来优化模型,对于从事金融、人工智能、云计算等相关领域的研究人员来说,具有很高的参考价值。
金工研究/深度研究 | 2019 年 02 月 18 日
谨请参阅尾页重要声明及华泰证券股票和行业评级标准 5
时序交叉验证的改进
关于模型调参和交叉验证的基本概念,本文不再赘述,感兴趣的读者请参考华泰金工人工
智能系列之十四《对抗过拟合:从时序交叉验证谈起》(20181128)。
本研究共测试六种交叉验证方法,分为三组:
1. “K 折交叉验证”和“时序交叉验证”是上篇报告测试比较的两种原始交叉验证方法。
其中前者为基线模型作对照之用,后者是上篇报告推荐使用的方法。
2. “训练集折半的 K 折交叉验证”和“乱序递进式交叉验证”是基于改进思路 1 提出的
两种新的基线模型。基线模型仍作对照之用,不是原始方法的提升,目的是探索时序
交叉验证带来提升的真实原因。
3. “分组时序交叉验证”和“乱序分组递进式交叉验证”是基于改进思路 2 提出的两种
新方法。其中前者是本篇报告推荐使用的方法,后者是针对前者单独设计的新基线模
型。
下面我们将逐一介绍六种交叉验证方法。
K 折和时序交叉验证
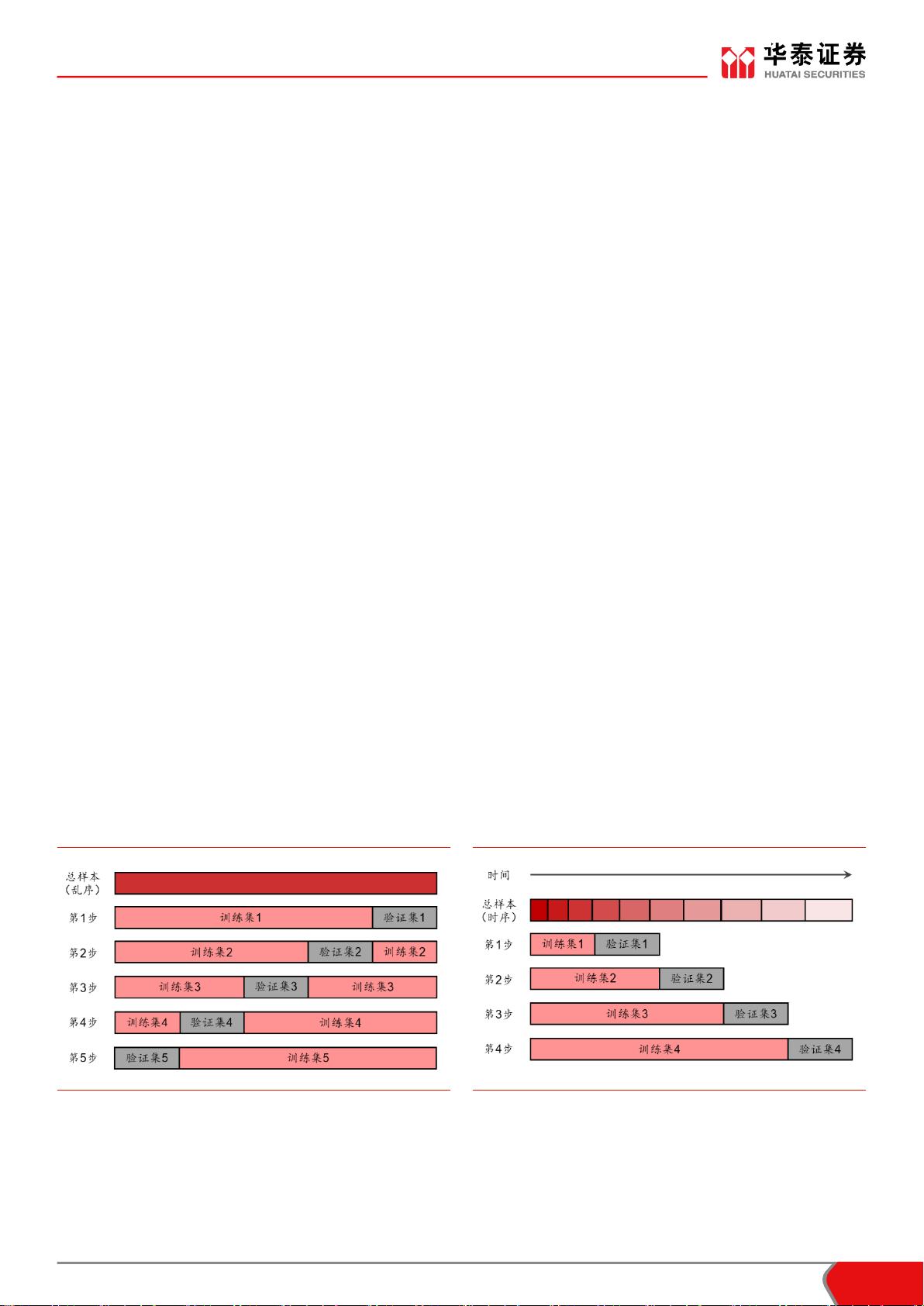
K 折交叉验证(k-fold cross-validation)是最经典和最常用的交叉验证方法之一。如图表
1 所示,将全体样本等分为 K 份(通常需要事先随机打乱,K 在 3~20 之间),每次用其中
的 1 份作为验证集,其余 K-1 份作为训练集。重复 K 次,直到所有部分都被验证过。取 K
个验证集的平均正确率(或 F1 分数、AUC、平方损失、对数损失等其它模型评价指标)
用以衡量该模型(或该组超参数)的整体表现。
时序交叉验证(time series cross-validation)如图表 2 所示,适用于时间序列数据。将保
留时序信息的数据等分(或依据其它标准切分)成 K+1 份,第 i 次验证时取第 i+1 份作为
验证集,第 1 至 i 份作为训练集,重复 K 次。同样取 K 个验证集的平均表现作为模型间比
较的依据。
K 折交叉验证广泛应用于图像识别、语音识别、自然语言处理等机器学习技术最为活跃的
领域。K 折交叉验证的使用前提是样本服从独立同分布。图像、语音、自然语言等领域的
数据通常满足独立同分布原则,而金融领域的时间序列数据往往存在较强的时序相关性。
理论上,K 折交叉验证不适用于时序数据;实际上,在金融领域 K 折交叉验证仍被大量地、
错误地使用。
图表1: K 折交叉验证示意图(K=5)
图表2: 时序交叉验证示意图(折数=5)
资料来源:华泰证券研究所
资料来源:华泰证券研究所
在华泰金工人工智能系列之十四《对抗过拟合:从时序交叉验证谈起》(20181128)的研
究中,我们采用机器学习公共数据集以及全 A 选股数据集,比较 K 折和时序这两种交叉验
证方法的表现。从实践结果来看,对于非时序数据,两种交叉验证方法表现接近。对于时
序数据,相比于 K 折交叉验证,时序交叉验证在样本内数据集上的表现相对较差,但是在
测试集上表现更好,表现出更低的过拟合程度;时序交叉验证倾向于选择超参数“简单”
剩余21页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-03 上传
2023-07-28 上传
2022-08-03 上传
2022-08-03 上传
2021-04-08 上传
2021-06-19 上传


qw_6918966011
- 粉丝: 27
- 资源: 6165
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
