时序交叉验证在人工智能中的应用:防止过拟合
需积分: 0 75 浏览量
更新于2024-06-22
1
收藏 1.38MB PDF 举报
"对抗过拟合,从时序交叉验证谈起"
本文主要探讨了在金融量化领域,特别是在使用人工智能和机器学习技术时,如何有效对抗过拟合问题,重点关注时序交叉验证这一方法。过拟合是机器学习模型训练中常见的问题,它指的是模型在训练数据上表现优秀,但在未见过的数据(测试集)上表现较差,这通常是因为模型过于复杂,过度学习了训练数据中的噪声和特有模式。
传统的交叉验证方法,如简单交叉验证、K折交叉验证、留一法和留P法,是通过随机分割数据集来评估模型性能。然而,对于时间序列数据,这种方法可能导致“未来信息预测历史”的问题,因为时间序列数据具有时间依赖性,前后数据间存在关联。这种情况下,传统交叉验证可能会利用未来的数据来优化对历史数据的预测,从而产生不真实的模型性能估计。
时序交叉验证则解决了这个问题,它保持了数据的时间顺序,避免了将未来的数据用于训练,只使用过去的数据进行模型训练和验证。这种方法在训练集上的表现可能不如传统交叉验证,但在测试集上的表现往往更好,因为它能更好地反映出模型在新数据上的泛化能力,有效防止过拟合。因此,对于时间序列数据分析,如金融市场的股票预测或交易策略,时序交叉验证是更合适的选择。
通过对比实验,文章展示了在机器学习公共数据集和全A股选股数据集上,时序交叉验证相对于传统交叉验证的优势。使用时序交叉验证的机器学习选股策略可以带来更高的稳定收益,这表明了这种方法在实际应用中的价值。研究人员建议投资者和策略开发者在选择模型超参数时,应优先考虑使用时序交叉验证。
此外,时序交叉验证还有助于选择更简单的模型,因为它倾向于选择过拟合程度较低的超参数。这种倾向性使得模型更具备泛化能力,减少了对特定训练数据的依赖。从不同基学习器的角度来看,时序交叉验证的这一特性有助于构建更为稳健的模型。
时序交叉验证是处理时间序列数据的关键工具,它在金融量化投资中的应用能够帮助我们构建更准确、更抗过拟合的预测模型,提高投资决策的质量和可靠性。投资者和从业者应重视这种方法,将其融入到模型开发和优化的过程中。
金工研究/深度研究 | 2018 年 11 月 28 日
谨请参阅尾页重要声明及华泰证券股票和行业评级标准 6
过拟合问题与交叉验证
人们在使用机器学习模型时,普遍担心的一个问题是过拟合:模型在样本内数据集的表现
优异,但是在样本外数据集的表现出现大幅下降。导致过拟合现象的可能原因在于模型超
参数的选取不当。交叉验证是一种常用的模型评价方法,广泛应用于模型超参数的选择。
传统交叉验证方法包括简单交叉验证、K 折交叉验证、留一法和留 P 法,其基本假设是样
本服从独立同分布。时间序列样本往往不满足独立同分布假设,此时时序交叉验证是更好
的选择。下面我们将围绕和时序交叉验证相关的几个重要概念进行介绍。
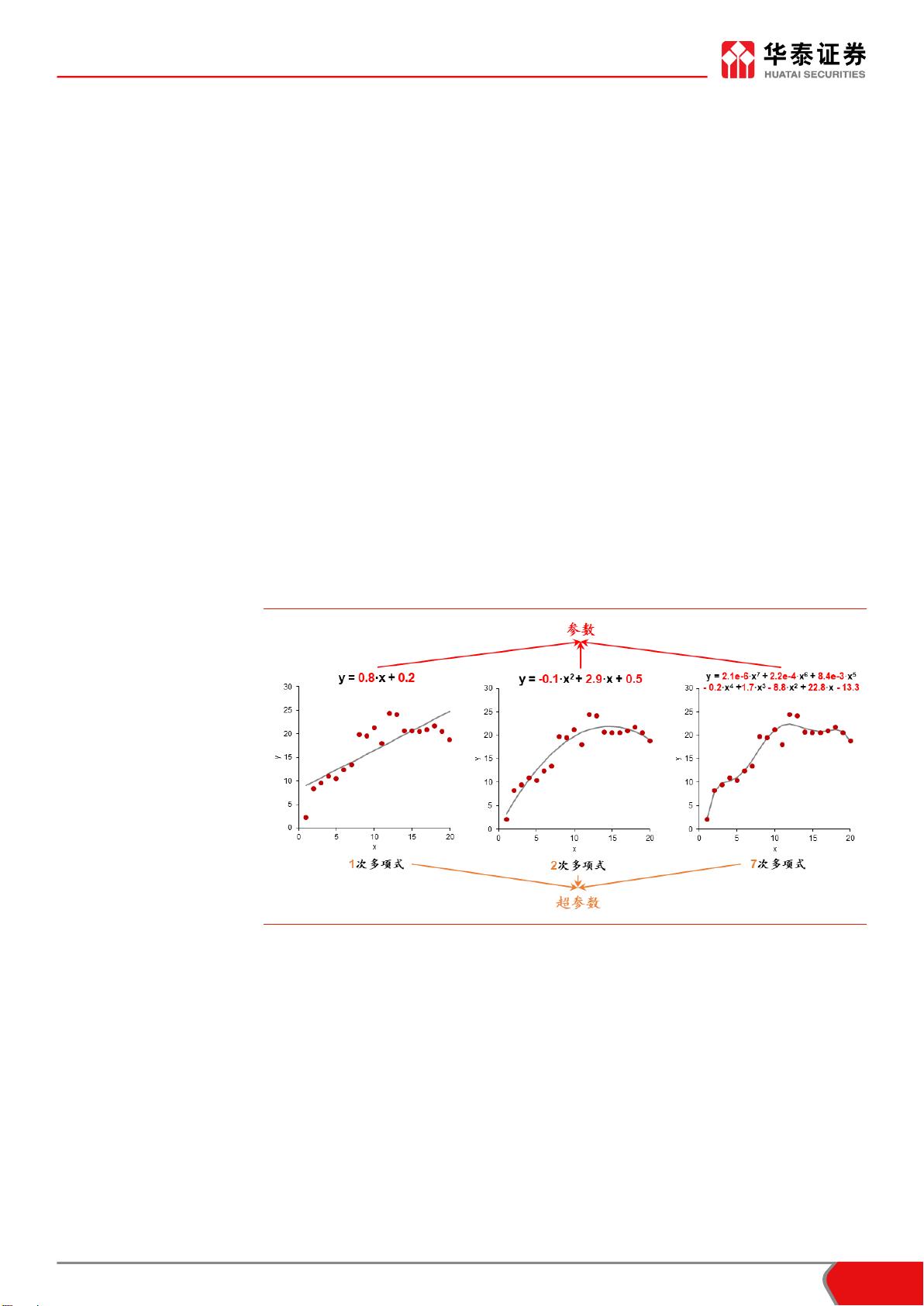
模型的参数和超参数
参数(parameter)和超参数(hyperparameter)在文献中常被混为一谈。研究者经常提
到的“调参”,实际上是调整超参数。为了防止语言上的混淆,我们首先对两者进行界定。
参数是模型的内部变量,是模型通过学习可以确定的参数。以简单的一元线性回归模型
为例,斜率 k 和截距 b 是该模型的参数。支持向量机模型的支持向量,神经网络模
型的神经元连接权值都是模型的参数。对于决策树类的模型而言,每一步分裂的规则也属
于模型参数的范畴。
超参数是模型的外部变量,是使用者用来确定模型的参数。假设我们希望采用回归模型对
一组自变量 x 和因变量 y 进行拟合,究竟使用线性(一次)模型 、二次模型
、三次模型
或者更高次的回归模型,这里的多项
式次数就是模型的超参数。下图展示了对回归模型中参数和超参数的辨析。
图表1: 模型的参数和超参数辨析
资料来源:华泰证券研究所
支持向量机模型中核函数类型、惩罚系数等,随机森林模型的树棵数、最大特征数、剪枝
参数等,XGBoost 模型的学习率、最大树深度、行采样比例等、神经网络模型的网络层数、
神经元个数、激活函数类型等,这些都属于模型的超参数。
模型的参数可以从训练集学习到,模型的超参数无法从训练集中直接学习到。模型的超参
数应如何学习?在解答这一问题之前,首先要介绍模型超参数选择不当导致的问题——欠
拟合和过拟合。
剩余28页未读,继续阅读
2021-09-03 上传
2023-07-27 上传
2022-01-30 上传
2023-09-20 上传
2023-05-16 上传
2023-05-19 上传
2023-06-05 上传
2023-07-04 上传
2024-11-01 上传


xox_761617
- 粉丝: 29
- 资源: 7802
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
