评估模型:精度vs AUC - 机器学习实战案例
106 浏览量
更新于2024-08-30
收藏 234KB PDF 举报
在"机器学习实战(六)模型评价标准"中,作者探讨了在评估分类器性能时遇到的传统分类精度与直观感受之间的矛盾。在给出的示例中,分类器C1虽然分类精度达到90%,但将所有样本误判为A类,缺乏区分能力;而分类器C2尽管总体精度只有75%,但在实际分类中表现更好。这表明单纯依赖分类精度并不能全面衡量模型效果。
引入了AUC(Area Under the Curve)作为更客观的评价指标,它通过计算ROC曲线下的面积来量化模型对正负样本的综合预测能力。AUC的取值范围在0.5到1之间,值越大表示模型性能越好,0.5以下的可以取其倒数。AUC解决了样本不平衡问题,不受单个类别数量影响,因此在处理如点击率(PV远大于Click)这类存在样本倾斜问题的场景下更具优势。
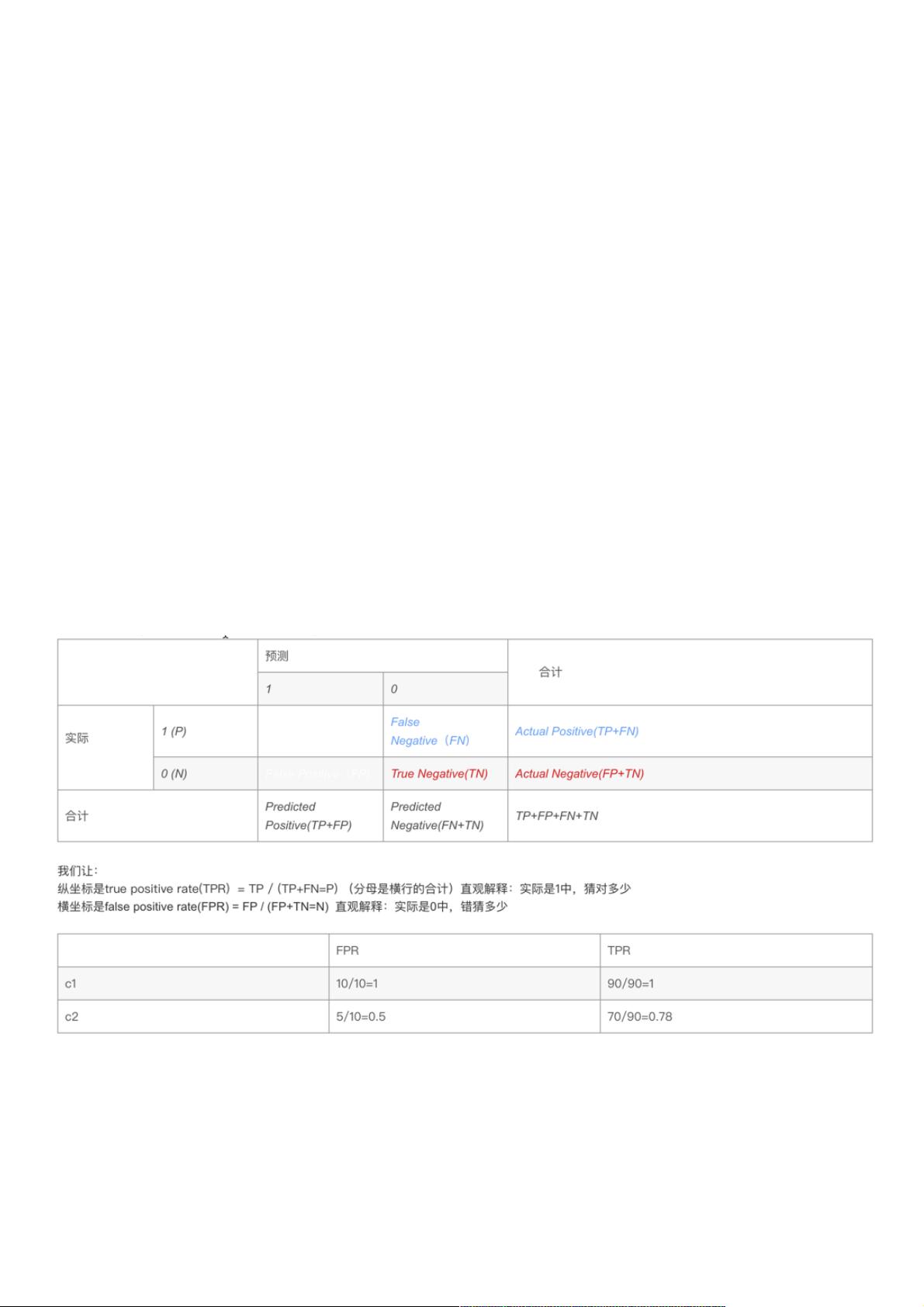
ROC曲线的构建基于二分类问题中的四种可能预测结果,即真正例(TP)、假正例(FP)、真反例(TN)和假反例(FN),ROC曲线由一系列不同的分类阈值下的FPR(False Positive Rate,假阳性率)和TPR(True Positive Rate,真正例率)组成。通过模型的“概率输出”功能,我们可以调整阈值并绘制出ROC曲线,其下的面积就是AUC值。
总结来说,这篇文章强调了在机器学习模型评估中,除了关注分类精度,还需借助AUC和ROC曲线来综合考量模型的性能,特别是在面对样本不平衡时,AUC提供了一个更为公正且全面的评价视角。这对于实际应用中的模型选择和优化至关重要。
机器学习实战(六)模型评价标准机器学习实战(六)模型评价标准
前言前言
本文内容大部分来自于如下两个博客:
http://blog.csdn.net/dinosoft/article/details/43114935
http://my.oschina.net/liangtee/blog/340317
引子引子
假设有下面两个分类器,哪个好?(样本中有A类样本90个,B 类样本10个。)
、、 A类样本类样本 B类样本类样本 分类精度分类精度
分类器C1 A*90(100%) A*10(0%) 90%
分类器C2
A*70 + B*20
(78%)
A*5 + B*5
(50%)
75%
分类器C1把所有的测试样本都分成了A类,分类器C2把A类的90个样本分对了70个,B类的10个样本分对了5个。
则C1的分类精度为 90%,C2的分类精度为75%,但直觉上,我们感觉C2更有用些。但是依照正确率来衡量的话,那么肯定C1的效果好一
点。那么这和我们认为的是不一致的。也就是说,有些时候,仅仅依靠正确率是不妥当的。
我们还需要一个评价指标,能客观反映对正样本、负样本综合预测的能力,还要考虑消除样本倾斜的影响(其实就是归一化之类的思想,
实际中很重要,比如pv总是远远大于click),这就是auc指标能解决的问题。
机器学习实践中分类器常用的评价指标就是auc,不想搞懂,简单用的话,记住一句话就行
auc取值范围[0.5,1],越大表示越好,小于0.5的把结果取反就行。
啥是啥是auc
roc曲线下的面积就是auc,所以要先搞清楚roc。
先看二分类问题,预测值跟实际值有4种组合情况,见下面的列联表
下载后可阅读完整内容,剩余3页未读,立即下载
2021-09-16 上传
点击了解资源详情
点击了解资源详情
2021-03-30 上传
2024-12-23 上传
2021-03-23 上传
2021-01-20 上传
点击了解资源详情
点击了解资源详情

weixin_38610657
- 粉丝: 3
- 资源: 926
 我的内容管理
展开
我的内容管理
展开







最新资源
- emf37.github.io
- 提取均值信号特征的matlab代码-Chall_21_SUB_A5:Chall_21_SUB_A5
- ng-recipe:角度的食谱应用程序
- sift,单片机c语言实例-源码下载,c语言程序
- artoolkit-example-fucheng
- json-tools:前端开发工具
- -:源程序代码,网页源码,-源码程序
- 04_TCPFile.rar
- 凡诺企业网站管理系统PHP
- 事件
- ads-1,c语言中ascii码与源码,c语言程序
- lilURL网址缩短程序 v0.1.1
- module-ballerina-random:Ballerina随机库
- nova-map-marker-field:提供用于编辑纬度和经度坐标的可视界面
- Crawler-NotParallel:C语言非并行爬虫,爬取网页源代码并进行确定性自动机匹配和布隆过滤器去重
- 分析安装在Android上的程序的应用程序
