苏宁数据仓库:三层架构应对爆发增长与效率提升
72 浏览量
更新于2024-08-28
收藏 384KB PDF 举报
随着苏宁公司的业务不断扩张,数据的增长速度日益加快,对数据的有效管理和分析提出了严峻的挑战。为了应对这一问题,苏宁采用了数据仓库技术进行数据治理,其核心目标是提高数据处理效率,减少冗余和复杂性,支持业务决策。
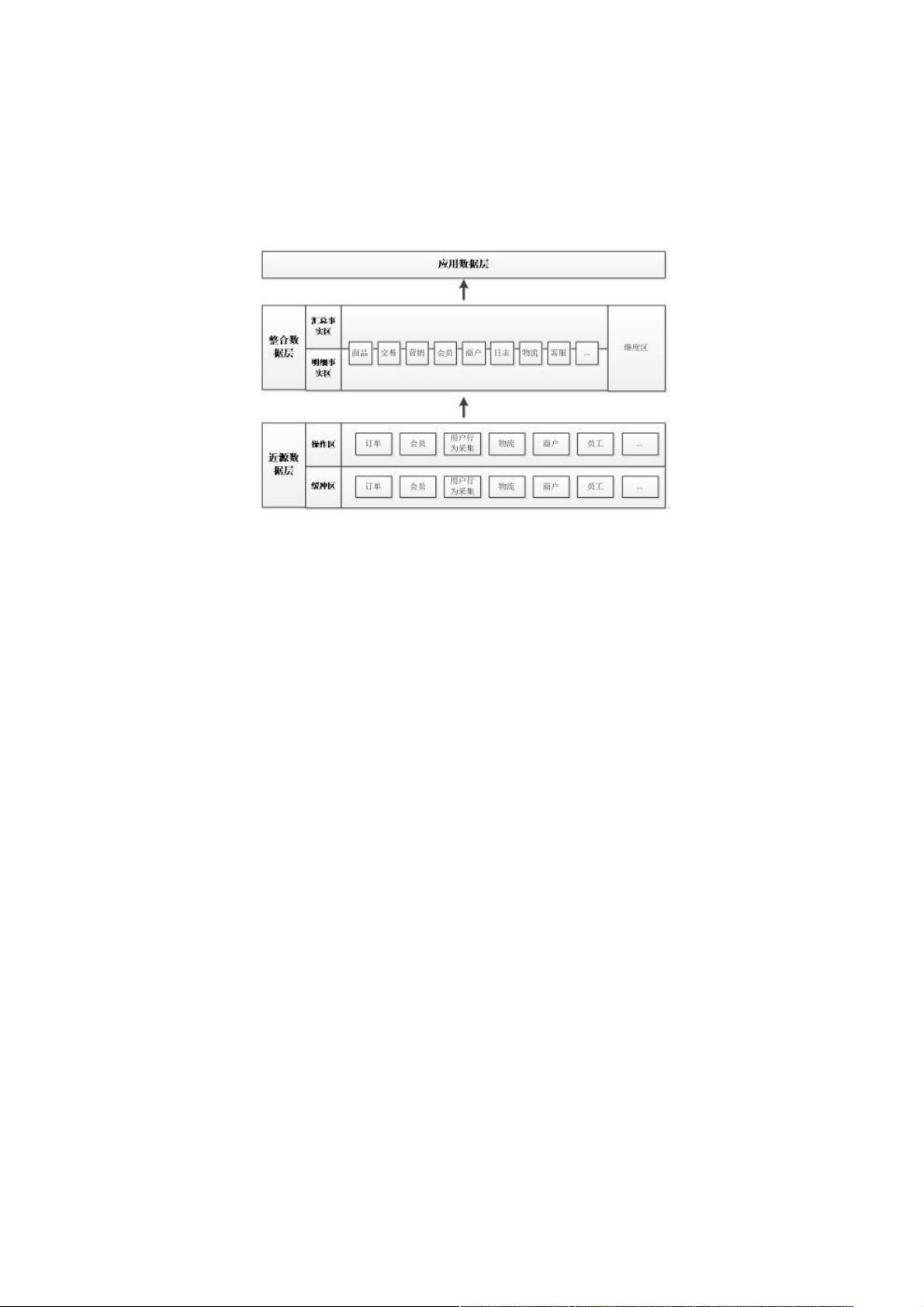
数据仓库的构建分为三个关键层次:近源数据层、整合数据层和应用数据层。
1. **近源数据层**:这个层次负责保存原始系统的增量数据,粒度、结构与源系统保持一致,仅保留必要的历史数据(如最近几天或几个月),以降低存储需求。它包含缓冲区,用于临时存储和处理数据,以及操作区,将数据按照业务源系统进行分类,以便后续处理和查询。
2. **整合数据层**:细分了明细区、汇总区和维度区。明细区采用维度建模方法,通过适度的反规范化设计减少数据冗余,提高查询性能。汇总区则根据应用需求对明细数据进行聚合,进一步提升取数效率。维度区则是统一的维度数据模型,用于整个数据仓库的结构化处理。
3. **应用数据层**:这是面向个性化需求的层次,存储不太通用的统计维度和指标,这些通常是特定业务线关心的内容,与其他业务线的交集较少。此层的计算通常只针对特定业务维度和指标。
在数据建模方面,苏宁主要采用Kimball的维度建模方法。维度建模强调数据仓库的核心在于提供统一的分析视图,维度表是核心,它们定义了分析的角度和标准。维度表的主键设计至关重要,可以选择业务含义明确的自然键,或者使用代理键(如流水号、自然键加上日期)来确保在维度表随业务变化时仍能保持一致性。
例如,对于苏宁门店这类会随组织变动而变更代码的情况,代理键就显得尤为重要,通过与业务门店代码映射,可以追踪历史和当前门店代码背后的真实业务实体。
苏宁数据仓库的技术演进策略是通过优化数据结构、层次化管理以及灵活的数据建模,确保在数据爆发式增长的背景下,有效地组织、管理和分析数据,支撑公司的决策和业务发展。
苏宁数据仓库应对数据爆发式增长的技术演进苏宁数据仓库应对数据爆发式增长的技术演进
为什么需要数据仓库
随着公司业务不断发展,数据种类和存储呈现爆发式增长,繁多的业务数据如何被各业务中心分析和使用,如何有效组织和管
理大量业务数据,减少大数据平台相近逻辑重复计算、相近数据重复存储,都将面临巨大挑战。
数据仓库层次架构
数据仓库层次整体划分为三层:近源数据层、整合数据层和应用数据层,如下图:
近源数据层
近源层是数据仓库拷贝源数据提供整合的数据存储区域,粒度、结构和源系统保持相同
缓冲区:保存源系统每天的增量数据,可根据应用需要保留适当历史周期的数据,不长期保存数据
操作区:存储数据仓库最细节数据,按照业务源系统分类划分;对数据做结构化处理,完整保留所有细节数据。
近源层是整个数据仓库中数据量最大的部分。
整合数据层
明细区:采用维度建模方法,整合近源层数据,进行适度的反范式设计明细事实数据表。
汇总区:根据应用层和其他下游系统取数需要,对明细事实数据进行适度汇总,提升取数性能。
维度区:数仓统一维度数据模型。
应用数据层
应用数据层为个性化汇总层,针对不是很通用统计维度、指标存放在此层中,本层计算通常只有自身业务关注的维度和指标,
和其他业务线一般无交集 。
数据建模
数据建模是数据仓库中的核心工作,苏宁数据建模主要采用的kimball维度建模方法,建模主要分两块,维度表设计和事实表
设计。
维度表设计
维度是数据仓库的核心,他提供了数据分析的视角和标准,大部分的维度表数据量都相对较小,但是他是整个数据仓库的核
心,整个的数据建模都是围绕着维度来建设。
维度表主键
维度表在数据仓库中有不可替代的重要地位,因此维度表主键的确认也尤其重要,维度表的主键用于和事实表做关联使用,所
以维度表主键也为事实表的外键,维表主键可由有业务含义的自然键组成;也可由无意义的代理建组成,比如使用流水号、自
然键+日期等方式。
维表相对静态、不随时间变化直接使用自然键作为主键,比如:业务状态码、性别、城市省份等不会随着时间改变而改变主键
对应业务含义,一般直接使用业务自然键作为主键;维表随着时间的变化而产生变化需要考虑使用代理键作为主键。苏宁门店
代码,会因为组织法人等信息变更,生门店代码会发生变化,对应主键的业务含义会随着时间的变化而改变,使用一个代理键
和业务门店代码映射,可以识别历史和当前不通的门店代码为一个门店。
下载后可阅读完整内容,剩余6页未读,立即下载
188 浏览量
1159 浏览量
214 浏览量
2021-10-14 上传
2022-06-26 上传
121 浏览量
117 浏览量

weixin_38666753
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- FlowReactiveNetwork: Android网络状态监听与Coroutines Flow集成
- 零基础SSH环境搭建教程与测试指南
- Win10下使用hiredis库实现C++操作Redis数据库
- 阿云里Redis集群安装与远程访问配置教程
- 办公电脑限制下高效利用文档资源的方法
- MaxDOS 9.3 版本发布:压缩包文件详细解析
- Stripe Checkout客户端POC实现与订阅滚动测试
- ANTLR 2.7.7源文件与JSTL的整合使用
- WordPress reCAPTCHA插件:轻量级安全防护
- SuperObject 1.25版本更新与XE2支持增强
- Laravel 5存储库模式:抽象和灵活的数据层管理
- 深入浅出CTreeCtrl类的递归技术及其应用
- Linux下的RAR压缩软件新版本发布 - rarlinux-5.9.1
- 系统延迟启动工具StartDelay——优化电脑开机速度
- REDHAT7.4平台下QT5.9.3+OpenGL三维坐标显示程序演示
- 深入理解EventBus总线使用及Demo演示
