苏宁数据仓库:应对业务增长的数据架构与建模策略
79 浏览量
更新于2024-08-27
收藏 384KB PDF 举报
随着苏宁公司业务的迅速扩张,数据的增长呈现出爆炸性态势,这对数据管理和分析提出了严峻的挑战。数据仓库作为一种关键的信息基础设施,其设计和演进对于支撑业务决策至关重要。本文将深入探讨苏宁数据仓库在应对数据爆发式增长时所采取的关键技术和架构优化。
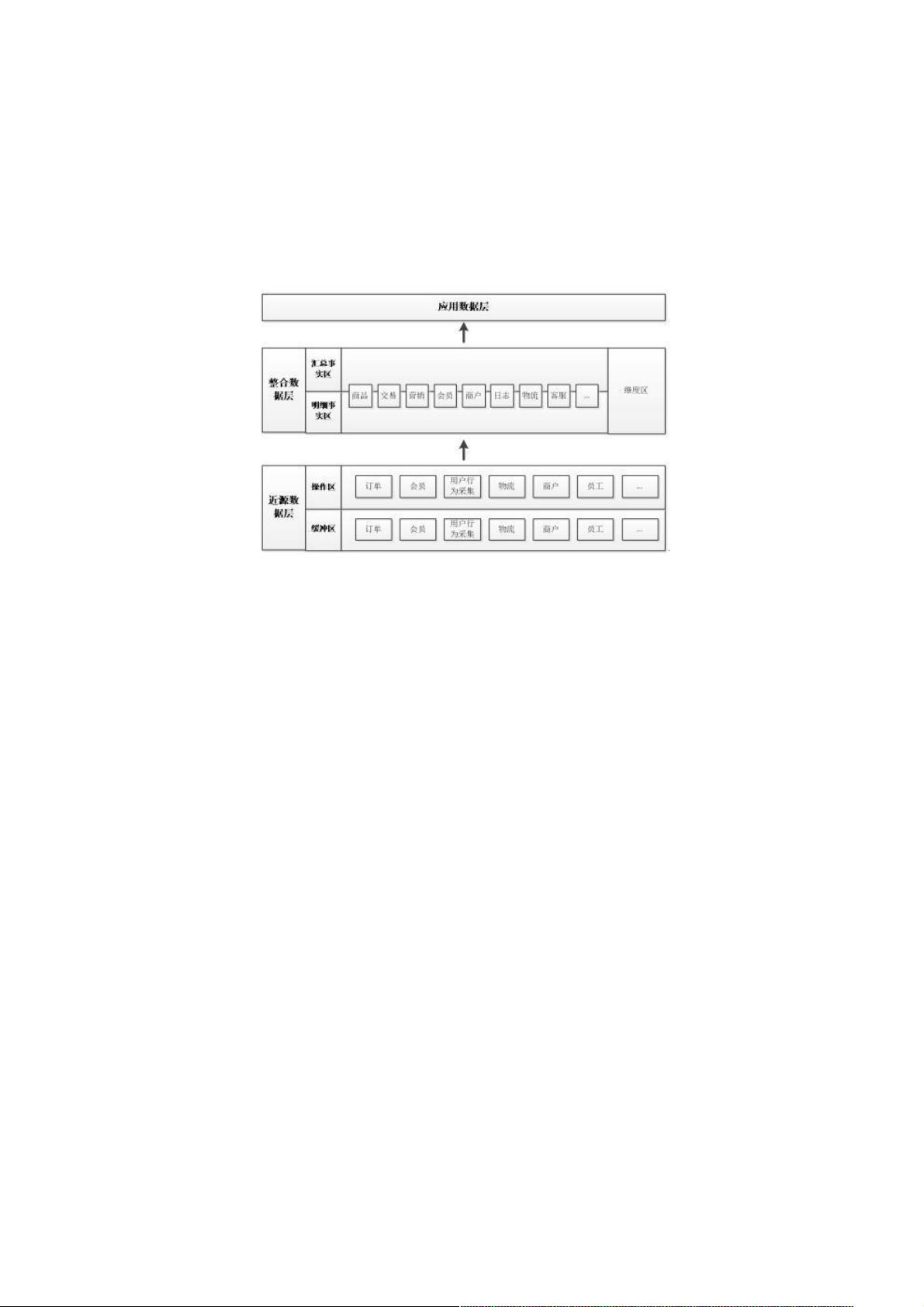
首先,建立数据仓库的必要性在于:海量的业务数据需要有序管理和高效利用,通过数据仓库,可以整合来自各个业务系统的数据,消除不必要的逻辑和数据冗余,提高数据处理效率。通过层次化的架构,数据仓库被划分为三个主要层次:近源数据层、整合数据层和应用数据层。
近源数据层是数据仓库的第一层,它直接复制源数据,并存储每天的增量数据。这个区域通常包含缓冲区,用于临时存储增量数据,保留一定周期的历史数据,但不会长期保留所有操作数据,以节省存储空间。操作区则负责存储详细的底层数据,按照业务源系统分类,确保数据结构化并完整保留所有细节。
整合数据层进一步处理这些原始数据。明细区采用维度建模方法,将数据进行适度的反范式设计,创建明细事实数据表,这有助于提高查询性能。汇总区则是根据应用需求,对明细数据进行汇总,以适应不同业务场景的需求。维度区则集中管理数据仓库中的统一维度数据模型,确保数据的一致性和准确性。
应用数据层是数据仓库的顶层,主要存放个性化汇总的数据,针对特定业务场景和非通用的统计维度和指标。这个层次的计算通常只涉及业务内部的关注点,与其他业务线相对独立。
数据建模是数据仓库的灵魂,苏宁采用Kimball维度建模方法,注重维度表的设计和事实表的设计。维度表作为核心组件,提供数据分析的视角和标准化框架,虽然数据量相对较小,但它们是数据仓库的基石。维度表主键的选择非常重要,可以选择业务含义明确的自然键,或者在必要时使用代理键,如门店代码这类可能随时间变化的标识。
在实际应用中,维度表的主键设计需考虑到时间敏感性和业务变化。例如,门店代码由于组织变动可能更改,这时就需要使用代理键与业务门店代码关联,以便追溯历史记录。苏宁通过这种方式确保了数据仓库在面对数据爆炸式增长时的灵活性和稳定性。
苏宁数据仓库通过层次化架构和精细的数据建模策略,成功地应对了数据爆发式增长带来的挑战,优化了数据处理流程,提高了数据利用效率,为公司的决策支持和业务发展提供了强大的数据基础。
苏宁数据仓库应对数据爆发式增长的技术演进苏宁数据仓库应对数据爆发式增长的技术演进
为什么需要数据仓库
随着公司业务不断发展,数据种类和存储呈现爆发式增长,繁多的业务数据如何被各业务中心分析和使用,如何有效组织和管
理大量业务数据,减少大数据平台相近逻辑重复计算、相近数据重复存储,都将面临巨大挑战。
数据仓库层次架构
数据仓库层次整体划分为三层:近源数据层、整合数据层和应用数据层,如下图:
近源数据层
近源层是数据仓库拷贝源数据提供整合的数据存储区域,粒度、结构和源系统保持相同
缓冲区:保存源系统每天的增量数据,可根据应用需要保留适当历史周期的数据,不长期保存数据
操作区:存储数据仓库最细节数据,按照业务源系统分类划分;对数据做结构化处理,完整保留所有细节数据。
近源层是整个数据仓库中数据量最大的部分。
整合数据层
明细区:采用维度建模方法,整合近源层数据,进行适度的反范式设计明细事实数据表。
汇总区:根据应用层和其他下游系统取数需要,对明细事实数据进行适度汇总,提升取数性能。
维度区:数仓统一维度数据模型。
应用数据层
应用数据层为个性化汇总层,针对不是很通用统计维度、指标存放在此层中,本层计算通常只有自身业务关注的维度和指标,
和其他业务线一般无交集 。
数据建模
数据建模是数据仓库中的核心工作,苏宁数据建模主要采用的kimball维度建模方法,建模主要分两块,维度表设计和事实表
设计。
维度表设计
维度是数据仓库的核心,他提供了数据分析的视角和标准,大部分的维度表数据量都相对较小,但是他是整个数据仓库的核
心,整个的数据建模都是围绕着维度来建设。
维度表主键
维度表在数据仓库中有不可替代的重要地位,因此维度表主键的确认也尤其重要,维度表的主键用于和事实表做关联使用,所
以维度表主键也为事实表的外键,维表主键可由有业务含义的自然键组成;也可由无意义的代理建组成,比如使用流水号、自
然键+日期等方式。
维表相对静态、不随时间变化直接使用自然键作为主键,比如:业务状态码、性别、城市省份等不会随着时间改变而改变主键
对应业务含义,一般直接使用业务自然键作为主键;维表随着时间的变化而产生变化需要考虑使用代理键作为主键。苏宁门店
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
2021-10-14 上传
2022-04-04 上传
2022-06-26 上传
点击了解资源详情

weixin_38698433
- 粉丝: 4
- 资源: 969
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
