MapReduce编程模型:简化大规模数据处理
需积分: 10 90 浏览量
更新于2024-07-29
收藏 249KB DOC 举报
"MapReduce是一种编程模型,专为大规模数据集的处理和生成而设计。用户定义map和reduce函数,map函数将输入的key/value对转换为中间key/value对,reduce函数则聚合相同key的值。该模型适用于许多实际任务,并能够在大量普通机器组成的集群上并行执行,自动处理数据分布、调度、故障恢复和通信。Google的MapReduce系统具有高可扩展性,能够处理TB级别的数据。程序员可以轻松地编写MapReduce程序,数百个程序已开发完成,并且每天有数千个作业在Google集群上运行。MapReduce的出现解决了因数据量巨大、分布式计算需求、容错性和负载均衡等问题带来的复杂性,将这些通用功能封装在库中,简化了原本简单的计算任务的实现。"
MapReduce的核心概念包括:
1. Map阶段:这是处理数据的第一步,用户定义的map函数接收键值对作为输入,对它们进行处理,生成一系列中间键值对。map函数通常用于数据的过滤、转换或拆分。中间键值对是无序的,并且可以被并行处理。
2. Shuffle阶段:此阶段是数据排序和分区的过程,中间键值对根据键进行排序,并分配到不同的reduce任务中,确保相同的键将被分发到同一个reduce任务。
3. Reduce阶段:在这个阶段,用户定义的reduce函数接收经过shuffle阶段后的中间键值对,将所有具有相同键的值进行聚合。这可以用于总结数据、计算汇总统计或执行其他聚合操作。reduce函数确保了最终结果的完整性,因为它处理了所有相关的中间值。
4. 错误处理和容错性:MapReduce系统设计时考虑到了机器故障的可能性。如果某个节点失败,系统能够重新调度任务到其他健康的节点,保证作业的完成。此外,数据通常会被复制,以防止数据丢失。
5. 扩展性和效率:MapReduce非常适合处理大规模数据,可以将工作负载分散到成千上万台机器上,以提高处理速度和吞吐量。通过这种方式,即使是TB级的数据也能在合理的时间内完成处理。
6. 应用场景:MapReduce广泛应用于搜索引擎索引构建、日志分析、社交网络分析、机器学习算法的训练等多种大数据处理任务中。
7. 程序员友好:MapReduce通过抽象出底层分布式系统和并发处理的复杂性,使得程序员可以专注于业务逻辑,降低了开发大规模并行应用程序的难度。
MapReduce提供了一种高效、可靠的框架,使得开发者能够处理大规模的数据处理任务,而无需深入理解分布式系统的所有细节。通过map和reduce这两个简单的编程接口,开发者可以快速构建处理大量数据的应用,极大地推动了大数据处理领域的发展。
(4) 存储时使用的便宜的 IDE 硬盘,直接放在每一个机器上。并且有一个分布式的文件系统
来管理这些分布在各个机器上的硬盘。文件系统通过复制的方法来在不可靠的硬件上保
证可用性和可靠性。
(5) 用户向调度系统提交请求。每一个请求都包含一组任务,映射到这个计算机 cluster 里的
一组机器上执行。
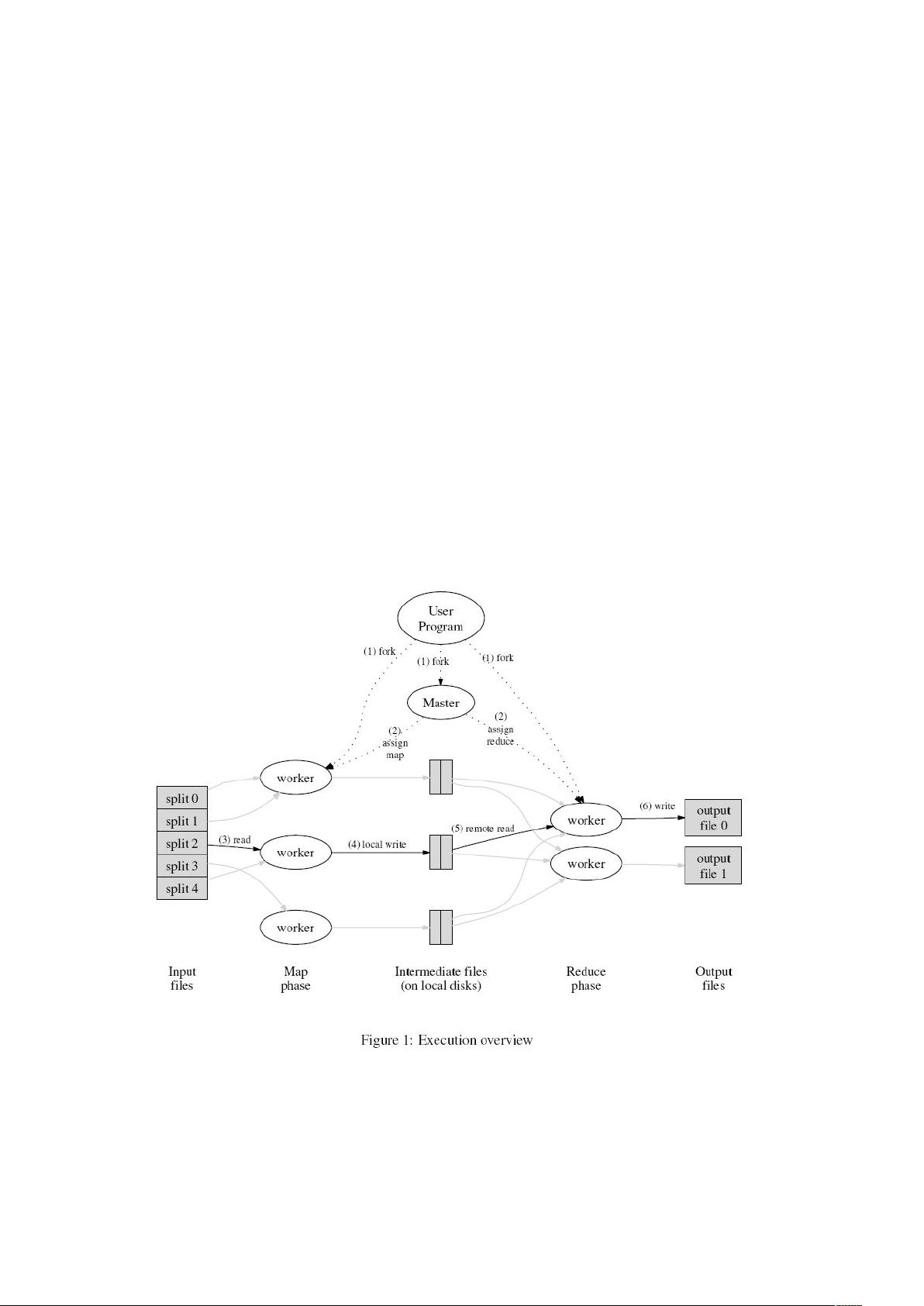
3.1 执行概览
Map 操作通过把输入数据进行分区(partition)(比如分为 M 块),就可以分布到不同的机器上
执行了。输入块的拆成多块,可以并行在不同机器上执行。Reduce 操作是通过对中间产生的 key
的分布来进行分布的,中间产生的 key 可以根据某种分区函数进行分布(比如 hash(key) mod
R),分布成为 R 块。分区(R)的数量和分区函数都是由用户指定的。
图 1 是我们实现的 MapReduce 操作的整体数据流。当用户程序调用 MapReduce 函数,就会引起
如下的操作(图一中的数字标示和下表的数字标示相同)。
第 5 页
剩余24页未读,继续阅读
234 浏览量
172 浏览量
150 浏览量
153 浏览量
184 浏览量
283 浏览量
170 浏览量
123 浏览量
202 浏览量

tycoon1988
- 粉丝: 255
- 资源: 90
 我的内容管理
展开
我的内容管理
展开







