Hive原理与MapReduce解析
9 浏览量
更新于2024-08-28
收藏 497KB PDF 举报
"本文主要分析了Hive的原理,包括其与MapReduce的关系以及MapReduce的基本编程模型,并通过实例展示了MapReduce如何工作。此外,还简单提及了Hive在系统实现层面的一些要点。"
在深入探讨Hive原理之前,首先要理解MapReduce这一核心概念。MapReduce是由Google提出的分布式编程模型,它的设计思想源于函数式编程中的映射(Map)和化简(Reduce)操作。这一模型简化了分布式计算的复杂性,开发者无需关注底层分布式集群的实现细节,只需专注于编写Map和Reduce函数,即可让程序在大规模分布式系统上高效运行。
Map阶段是数据处理的起点,它接收输入的数据,并将其转化为一系列中间键值对。例如在WordCount的例子中,Map函数读取文本,将每行文本分割成单词,生成形如"(单词, 1)"的键值对。这个阶段的关键在于将原始数据拆分成可处理的小块。
接下来是Reduce阶段,它负责聚合Map阶段产生的中间结果。Reduce函数按照相同的键将中间键值对分组,然后对每个键对应的值进行处理,通常涉及累加或聚合操作。在WordCount示例中,Reduce函数会汇总所有相同单词的计数,最终得出每个单词的总数。
MapReduce模型在实际应用中有着广泛的应用场景。例如,计算URL访问频率,Map函数将日志中的URL与1配对,Reduce函数则将相同URL的值相加。倒转网络链接图、创建倒排索引以及构建每个主机的检索词向量等任务,都是MapReduce模型在不同领域的应用实例。
Hive作为一个基于Hadoop的数据仓库工具,充分利用了MapReduce的分布式计算能力。用户通过HQL(Hive Query Language)编写查询,Hive会将这些查询语句转化为MapReduce作业执行。在系统实现上,Hive会根据用户指定的Map和Reduce函数以及配置参数,如分区数量和哈希函数,来协调整个MapReduce计算流程,包括数据切分、任务调度以及结果收集等步骤。
Hive通过将SQL-like查询语句转化为MapReduce任务,使得非专业分布式编程背景的用户也能方便地在大数据环境中进行数据处理和分析。MapReduce作为Hive的核心计算引擎,提供了可扩展性和容错性,确保了在大规模数据集上的高效运算。理解这两者的关系对于深入掌握Hive的工作原理至关重要。
Hive原理分析原理分析
Front
在开始了解hive之前,需要了解一些知识或者概念,可以更好的理解hive实现原理
MapReduce
Google MapReduce是Google基于函数式编程map(映射),reduce(化简)提出的一种分布式编程模型,在模型中隐藏了
分布式集群的实现细节,交由框架底层进行实现,能够使程序员在不了解分布式并行编程的情况下,将自己书写的程序在分布
式系统上运行
编程模型
Map: 将输入的一对键值对转换为一组中间键值对 (k1,v1) -> list(k2,v2)
Reduce: 将所有键相同的中间键值对合并,得到关于那个键的结果 (k2,list(v2)) -> (k2,v3)
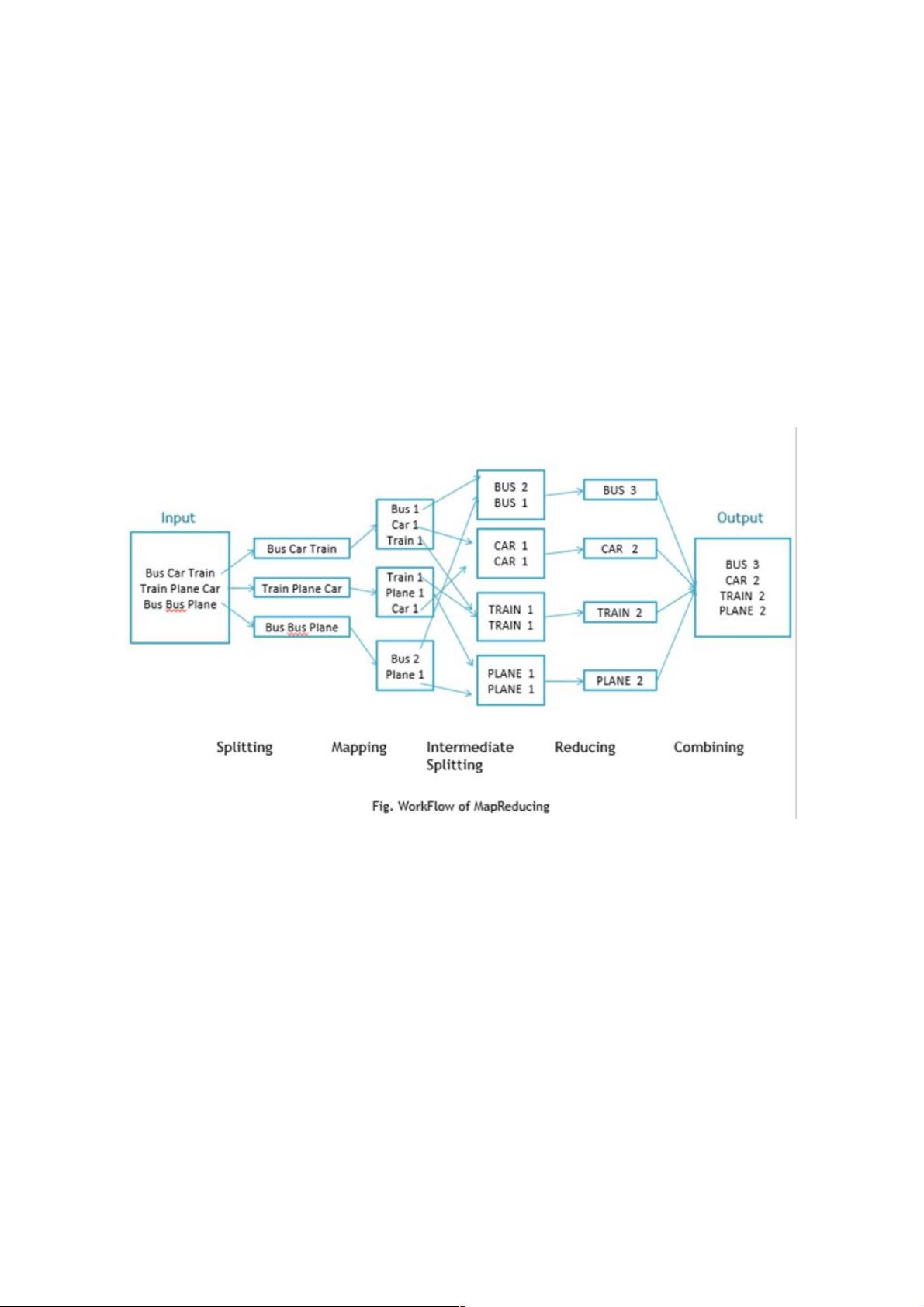
举个栗子
以一个很简单的WordCount为例子,假设给定大量数据的文档,计算其中每个单词出现的次数,下面是伪代码
更多的栗子
计算 URL 访问频率:Map 函数处理日志中 web 页面请求的记录,然后输出(URL,1)。Reduce 函数把相同URL 的 value 值都
累加起来,产生(URL,记录总数)结果。
倒转网络链接图:Map 函数在源页面(source)中搜索所有的链接目标(target)并输出为(target,source)。 Reduce 函数把
给定链接目标(target)的链接组合成一个列表,输出(target,list(source))。
倒排索引:Map 函数分析每个文档输出一个(词,文档号)的列表,Reduce 函数的输入是一个给定词的所有 (词,文档号),
排序所有的文档号,输出(词,list(文档号))。所有的输出集合形成一个简单的倒排索引,它 以一种简单的算法跟踪词在文档
中的位置。
每个主机的检索词向量:检索词向量用一个(词,频率)列表来概述出现在文档或文档集中的最重要的一些 词。Map 函数为每一
个输入文档输出(主机名,检索词向量),其中主机名来自文档的 URL。Reduce 函数接收给 定主机的所有文档的检索词向量,
并把这些检索词向量加在一起,丢弃掉低频的检索词,输出一个最终的(主机名,检索词向量)。
系统实现
下载后可阅读完整内容,剩余7页未读,立即下载
346 浏览量
147 浏览量
875 浏览量
250 浏览量
973 浏览量
150 浏览量
335 浏览量

weixin_38704485
- 粉丝: 8
- 资源: 928
 我的内容管理
展开
我的内容管理
展开







最新资源
- hello world on uClinux&& skyeye
- 09年计算机统考考试大纲
- SQL语言艺术.pdf
- 王能斌-数据库系统原理课件
- C语言笔试大全(来自多位应聘同学的经验)
- 最新JAVA面试大全
- Agilent3070中文介绍
- VC6 MFC类库完全参考手册
- 直流无刷电机的工作原理
- vim 用户手册.pdf
- IBM_SOA框架师资料
- Erlang/OTP中文教程
- PKE主动进入系统中文资料。
- 直面挑战 走近 Visual Studio 2008 和.NET Framework 3.5
- MATLAB编程(第二版)-菜鸟入门教材
- Manning.WPF.in.Action.with.Visual.Studio.2008.Nov.2008.pdf
