Hive原理与MapReduce详解
128 浏览量
更新于2024-08-28
收藏 497KB PDF 举报
"Hive原理分析"
Hive是一个基于Hadoop的数据仓库工具,它允许使用SQL-like查询语言(HQL)来处理存储在Hadoop分布式文件系统(HDFS)中的大数据。在深入理解Hive的工作原理之前,有必要先了解MapReduce这一分布式计算模型,因为Hive在执行查询时依赖于MapReduce。
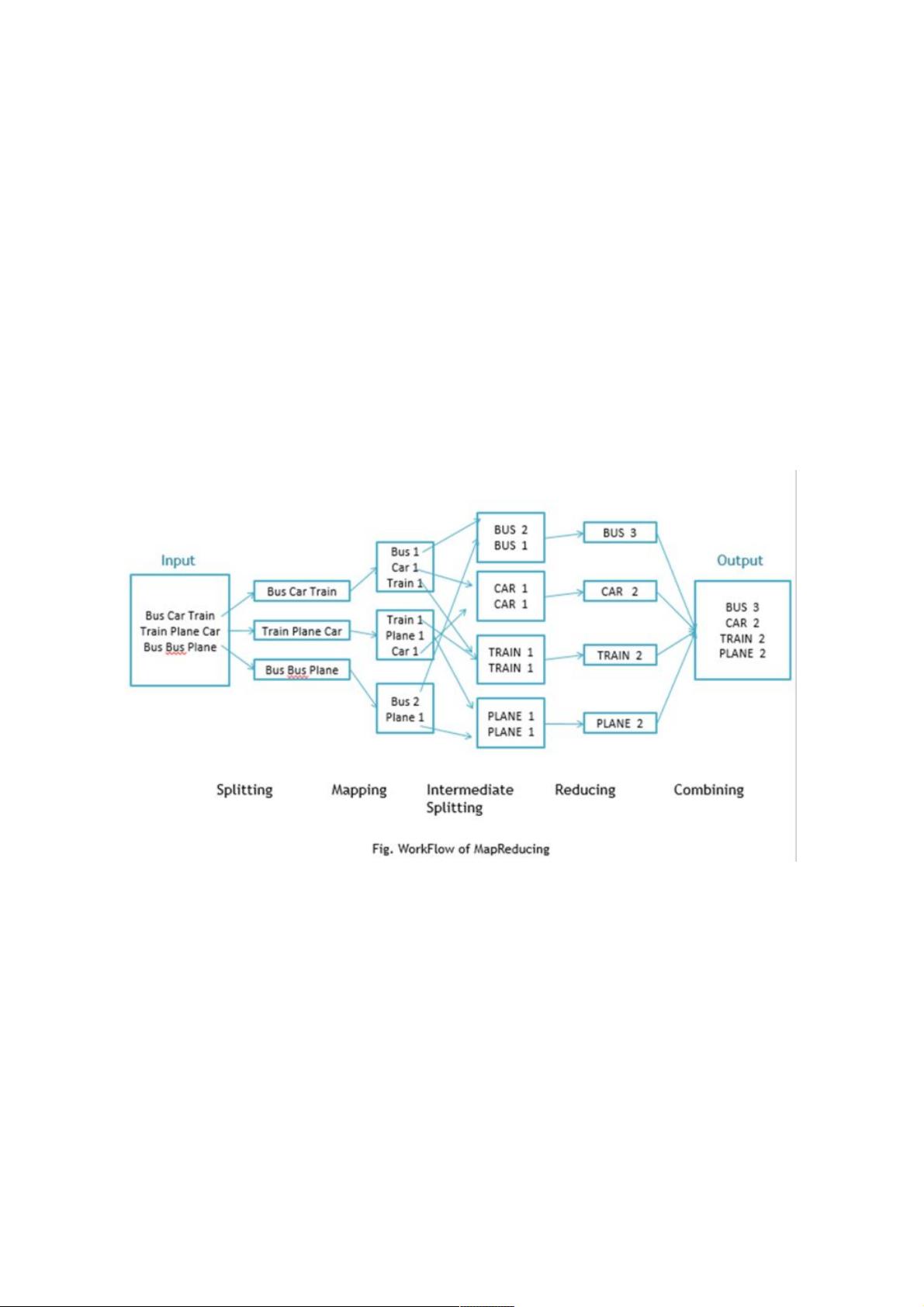
MapReduce是Google提出的一种编程模型,主要用于大规模数据集的并行计算。它的核心思想是将复杂的分布式计算过程简化为两个主要操作:Map和Reduce。
1. Map阶段:
在这个阶段,原始数据被分割成多个块(通常由HDFS完成),然后由多个Map任务并行处理。每个Map任务接收一部分数据,对输入的键值对进行处理,并生成新的中间键值对。例如,对于WordCount任务,Map函数会读取一行文本,将单词拆分并输出(单词,1)的键值对。
2. Shuffle & Sort阶段:
Map任务产生的中间键值对经过分区(Partitioning)和排序,确保具有相同键的值会被发送到同一个Reduce任务。
3. Reduce阶段:
Reduce任务接收到所有相同键的中间键值对,对这些值进行聚合操作。例如,WordCount任务的Reduce函数会将所有相同单词的计数值相加,最终输出(单词,总次数)。
Hive利用MapReduce执行查询的流程如下:
- 用户通过Hive接口提交SQL查询。
- Hive解析查询语句,生成一个执行计划,这个计划可能包含多个MapReduce作业。
- 对于每个MapReduce作业,Hive会生成对应的Mapper和Reducer代码。Mapper代码通常负责数据的预处理,如过滤、投影等操作;Reducer则执行聚合、分组等复杂操作。
- Hadoop调度器根据集群资源分配MapReduce任务到各个节点。
- Map任务在各个节点上运行,处理数据并生成中间结果。
- Shuffle & Sort阶段确保数据按照键进行排序和分区,以便Reducer正确处理。
- Reduce任务将中间结果聚合,输出最终结果。
- 结果存储回HDFS,用户可以通过Hive查询获取结果。
Hive的优势在于它提供了SQL接口,使得非Java背景的分析师也能轻松处理大数据。然而,由于每次查询都需要转化为MapReduce作业,其性能通常比传统的数据库慢。为解决这个问题,后续版本的Hive引入了Tez和Spark等更高效的执行引擎,以提高查询效率。
Hive是大数据分析领域的重要工具,它通过抽象出SQL-like查询语言,降低了处理大规模数据的门槛,而其底层的MapReduce模型则保证了在分布式环境中的可扩展性和容错性。理解这两个概念对于深入掌握Hive的工作原理至关重要。
Hive原理分析原理分析
Front
在开始了解hive之前,需要了解一些知识或者概念,可以更好的理解hive实现原理
MapReduce
Google MapReduce是Google基于函数式编程map(映射),reduce(化简)提出的一种分布式编程模型,在模型中隐藏了
分布式集群的实现细节,交由框架底层进行实现,能够使程序员在不了解分布式并行编程的情况下,将自己书写的程序在分布
式系统上运行
编程模型
Map: 将输入的一对键值对转换为一组中间键值对 (k1,v1) -> list(k2,v2)
Reduce: 将所有键相同的中间键值对合并,得到关于那个键的结果 (k2,list(v2)) -> (k2,v3)
举个栗子
以一个很简单的WordCount为例子,假设给定大量数据的文档,计算其中每个单词出现的次数,下面是伪代码
更多的栗子
计算 URL 访问频率:Map 函数处理日志中 web 页面请求的记录,然后输出(URL,1)。Reduce 函数把相同URL 的 value 值都
累加起来,产生(URL,记录总数)结果。
倒转网络链接图:Map 函数在源页面(source)中搜索所有的链接目标(target)并输出为(target,source)。 Reduce 函数把
给定链接目标(target)的链接组合成一个列表,输出(target,list(source))。
倒排索引:Map 函数分析每个文档输出一个(词,文档号)的列表,Reduce 函数的输入是一个给定词的所有 (词,文档号),
排序所有的文档号,输出(词,list(文档号))。所有的输出集合形成一个简单的倒排索引,它 以一种简单的算法跟踪词在文档
中的位置。
每个主机的检索词向量:检索词向量用一个(词,频率)列表来概述出现在文档或文档集中的最重要的一些 词。Map 函数为每一
个输入文档输出(主机名,检索词向量),其中主机名来自文档的 URL。Reduce 函数接收给 定主机的所有文档的检索词向量,
并把这些检索词向量加在一起,丢弃掉低频的检索词,输出一个最终的(主机名,检索词向量)。
系统实现
下载后可阅读完整内容,剩余7页未读,立即下载
345 浏览量
146 浏览量
873 浏览量
249 浏览量
972 浏览量
149 浏览量
点击了解资源详情

weixin_38589314
- 粉丝: 7
- 资源: 945
 我的内容管理
展开
我的内容管理
展开







最新资源
- 软件水平考试网络工程师英语复习练习题10套
- JAVA面试题目大汇总
- 门禁系统设计 论文 完整版
- soa相关技术介绍与实现
- a Frame Layout Framework
- Thinking in Patterns
- 图书管理信息系统 SIM SQL Server2000数据库管理系统
- Bayesian and Markov chain
- Analysis of a Denial of Service Attack on TCP.
- 802.11英文原版协议 11G 11 N WEP WPA WPA2 BEACON 好东西大家分享
- aix双机配置详细配置
- 中国联通SGIP1.2
- 09数据库系统工程师考试大纲
- DFBlaser窄线宽激光器
- WinSock编程基础原理与C实现代码
- bfin-uclinux内核的CPLB v0.1
