MySQL B-Tree索引详解:原理与优化
42 浏览量
更新于2024-08-29
收藏 171KB PDF 举报
本文将深入浅析MySQL中的B-Tree索引,一种在数据库管理系统中广泛应用的数据结构,特别是在InnoDB存储引擎中。B-Tree索引的核心特性是其有序性和平衡性,确保数据在树状结构中均匀分布,从而实现快速数据访问。
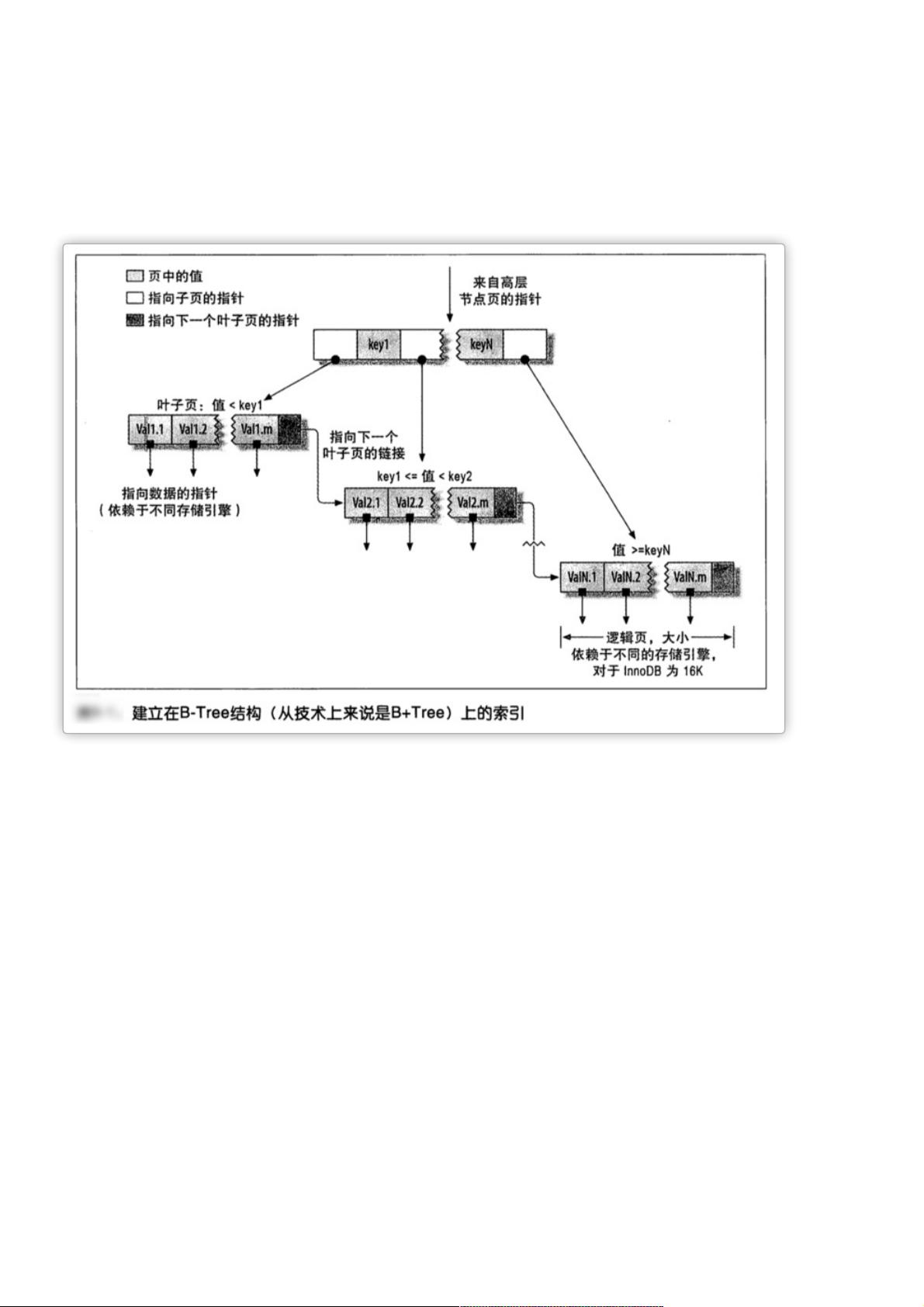
首先,B-Tree(也称为B+Tree)与T-Tree(如NDB集群存储引擎使用的结构)的区别在于存储方式。虽然名称相似,但它们在内部实现上有差异。InnoDB存储引擎采用B+Tree,每个叶子节点包含了所有数据元素,且所有叶子节点到根节点的距离相等。这样的设计使得范围查询效率极高,因为查询时可以直接定位到包含所需数据的叶子节点,避免了全表扫描。
选择B+Tree而非其他数据结构,如B树或红黑树,是因为B+Tree更有利于查询性能。全键值、键值范围或键前缀查找都是B-Tree的优势场景。例如,创建一个名为People的表,其中包含last_name、first_name和dob字段的复合索引,可以有效地支持这些类型的查询。
在优化查询性能时,查询计划中的"possible_keys"列显示了SQL可能使用的索引,而"key"列则表示MySQL实际使用的索引。理想情况下,查询应至少达到"range"级别,甚至"ref"级别,以避免性能瓶颈。全值匹配查询,即完全匹配索引所有列的情况,比如查找特定姓名和日期的记录,正是B-Tree索引的典型应用场景。
总结来说,MySQL中的B-Tree索引是通过其有序、平衡的特性来提升数据库查询效率的关键组成部分,特别是对于范围查询和复合索引的支持。理解并合理利用B+Tree索引的特性和优化策略,对于提高数据库性能和开发效率至关重要。
浅析浅析MysQL B-Tree 索引索引
B-Tree 索引索引
不同的存储引擎也可能使用不同的存储结构,i如,NDB集群存储引擎内部实现使用了T-Tree结构存储这种索引,即使其名字
是BTREE;InnoDB使用的是B+Tree。
B-Tree通常一位这所有的值都是按顺序存储的,并且每一个叶子页道根的距离相同。下图大致反应了InnoDB索引是如何工作
的。
为什么为什么mysql索引要使用索引要使用B+树,而不是树,而不是B树,红黑树树,红黑树
看完上面的文章就可以理解为何B-Tree索引能够快速访问数据了。因为存储引擎不再需要进行全表扫描获取需要的数据,叶
子节点包含了所有元素信息,每一个叶子节点指针都指向下一个节点,所以很适合查找范围数据。
索引对多个值进行排列的依据是CREATE TABLE 语句中定义索引时的顺序。
那么,索引排序的规则就是按照 last_name ,first_name ,dob 的顺序来的。
可以使用 B-Tree 索引的查询类型
B-Tree索引适用于全键值、键值范围或键前缀查找。
键前缀查找只是用于根据最左前缀查找。
举个粒子:
CREATE TABLE People (
last_name VARCHAR ( 50 ) NOT NULL,
first_name VARCHAR ( 50 ) NOT NULL,
dob date NOT NULL,
gender enum ( 'm', 'f' ) NOT NULL,
KEY ( last_name, first_name, dob )
);
这个表的索引如下:
下载后可阅读完整内容,剩余3页未读,立即下载
122 浏览量
169 浏览量
571 浏览量
570 浏览量
194 浏览量
117 浏览量
328 浏览量

weixin_38660108
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- HTC G22刷机教程:掌握底包刷入及第三方ROM安装
- JAVA天天动听1.4版:证书加持的移动音乐播放器
- 掌握Swift开发:实现Keynote魔术移动动画效果
- VB+ACCESS音像管理系统源代码及系统操作教程
- Android Nanodegree项目6:Sunshine-Wear应用开发
- Gson解析json与网络图片加载实践教程
- 虚拟机清理神器vmclean软件:解决安装失败难题
- React打造MyHome-Web:公寓管理Web应用
- LVD 2006/95/EC指令及其应用指南解析
- PHP+MYSQL技术构建的完整门户网站源码
- 轻松编程:12864液晶取模工具使用指南
- 南邮离散数学实验源码分享与学习心得
- qq空间触屏版网站模板:跨平台技术项目源码大全
- Twitter-Contest-Bot:自动化参加推文竞赛的Java机器人
- 快速上手SpringBoot后端开发环境搭建指南
- C#项目中生成Font Awesome Unicode的代码仓库
