雅虎大规模应用Hadoop:海量数据处理与生态系统
Hadoop在雅虎的应用是一个深度解析的主题,它涵盖了Hadoop技术在这家全球知名互联网巨头中的大规模部署和成功案例。由Milind Bhandarkar担任Hadoop解决方案架构师,他在1989年开始从事并行编程,尤其在高性能科学计算领域有着丰富的经验,自2005年起专注于数据密集型计算。在雅虎,Hadoop的故事始于2004年,当时在Apache Lucene项目中进行了原型开发,随后在2006年正式成为Lucene的子项目,并于2008年提升为顶级Apache项目。
Hadoop生态系统包括了一系列的重要组件,如HBase(用于存储大规模数据的列式数据库)、Hive(SQL查询语言接口)、Pig(数据流编程语言)、Howl(分布式搜索系统)、Oozie(工作流管理系统)、Zookeeper(分布式协调服务)、Chukwa(日志收集系统)、Mahout(机器学习库)、Cascading(数据流水线框架)、Scribe(日志聚合系统)、Cassandra(NoSQL数据库)、Hypertable(谷歌Bigtable的开源版本)、Voldemort(分布式内存存储系统)、Azkaban(工作流管理工具)、Sqoop(数据迁移工具)、Flume(数据收集系统)、Avro(数据序列化系统)等,这些工具共同构建了一个强大的数据处理和分析平台。
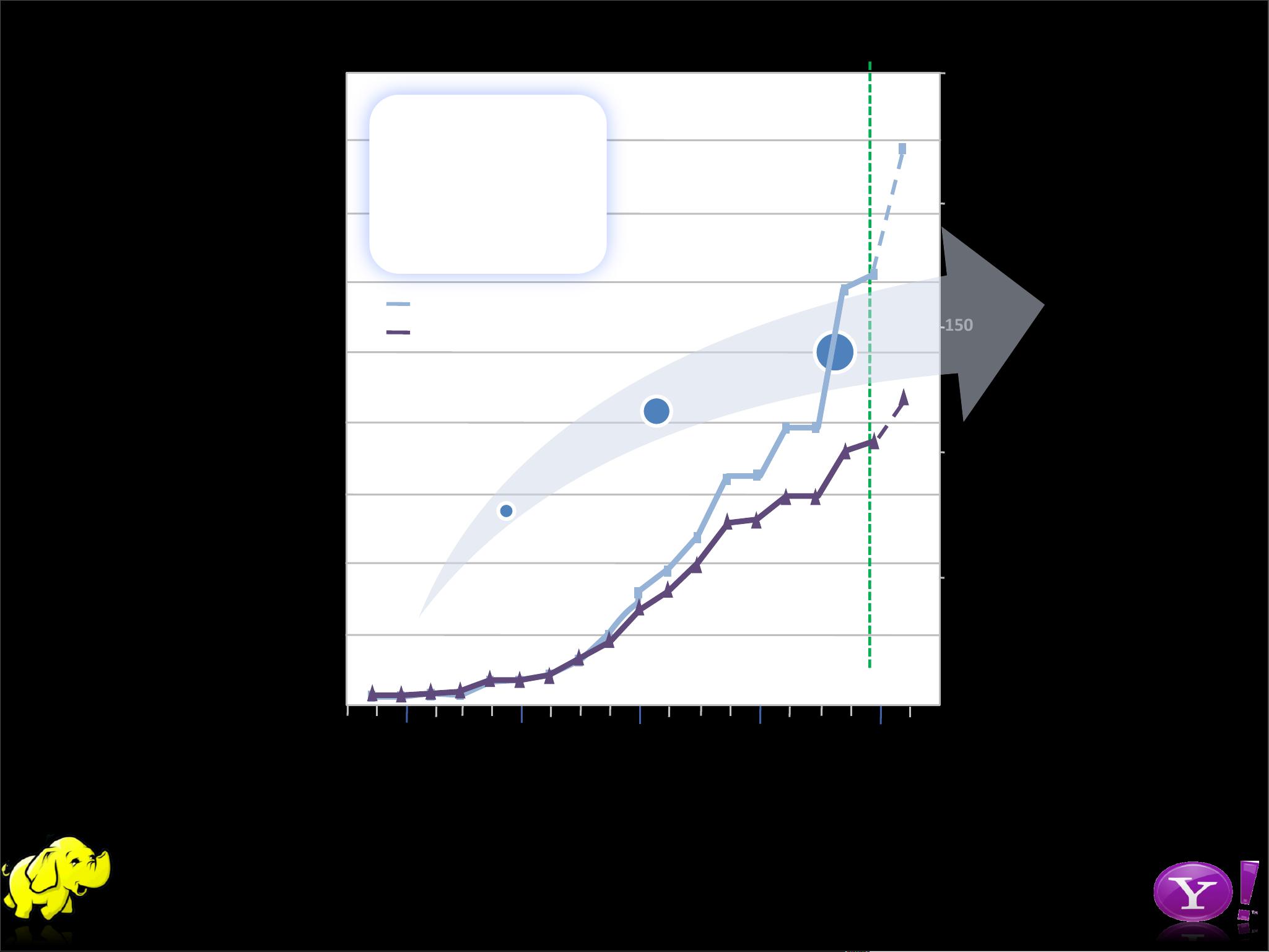
在雅虎内部,Hadoop的应用非常广泛且深入。据透露,Hadoop在支撑雅虎的各项业务中扮演着关键角色,几乎每一下用户点击的背后都有其身影。雅虎的Hadoop集群规模庞大,最大的集群拥有超过4000台服务器,每月处理超过100万个工作任务,存储容量达到170多PB,每天还会增加10TB以上的压缩数据。这些数据的处理能力使得雅虎能够高效地处理和分析海量数据,从而驱动其广告定向、个性化推荐和其他核心业务决策。
Hadoop团队由超过1000名用户组成,他们负责日常的运维、培训、咨询以及容量规划等工作,确保整个Hadoop生态系统的稳定运行和持续优化。这一系列的数字和事实证明了Hadoop在雅虎的战略地位,以及其在处理复杂数据挑战时的显著效益。
总结来说,Hadoop在雅虎的应用不仅仅是一个技术部署,更是一个业务转型和效能提升的关键驱动力,它展示了大数据处理在现代企业中的核心作用,特别是对于那些依赖于海量数据进行决策和创新的公司。通过Hadoop及其生态系统,雅虎得以实现对海量数据的高效利用,推动了业务的持续增长和发展。
!"#
$"#
%"#
&"#
'"#
("#
)"#
*"#
+"#
"#
*'"#
*""#
+'"#
+""#
'"#
"#
*""&#
*""%# *""$# *""!#
*"+"#
,-./0#
)$1#2345346#
+%"#78#29-4/:3#
+;<#;-=9>?0#@-A6#
!"#$%&'(%)#*)+,-.,-%)
/,0&120,%)
3,%,&-4")
+45,'4,)
678&40)
9&5:2)
/-#($4;#')
B/.--C#2345346#
B/.--C#29-4/:3#D78E#
Hadoop Growth
剩余29页未读,继续阅读
2014-05-25 上传
2017-04-14 上传
2020-06-05 上传
2011-07-29 上传
点击了解资源详情
点击了解资源详情

Lizhi1114
- 粉丝: 4
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- 明日知道社区问答系统设计与实现-SSM框架java源码分享
- Unity3D粒子特效包:闪电效果体验报告
- Windows64位Python3.7安装Twisted库指南
- HTMLJS应用程序:多词典阿拉伯语词根检索
- 光纤通信课后习题答案解析及文件资源
- swdogen: 自动扫描源码生成 Swagger 文档的工具
- GD32F10系列芯片Keil IDE下载算法配置指南
- C++实现Emscripten版本的3D俄罗斯方块游戏
- 期末复习必备:全面数据结构课件资料
- WordPress媒体占位符插件:优化开发中的图像占位体验
- 完整扑克牌资源集-55张图片压缩包下载
- 开发轻量级时事通讯活动管理RESTful应用程序
- 长城特固618对讲机写频软件使用指南
- Memry粤语学习工具:开源应用助力记忆提升
- JMC 8.0.0版本发布,支持JDK 1.8及64位系统
- Python看图猜成语游戏源码发布
