Python爬取75条知乎神回复实战:60行代码搞定
63 浏览量
更新于2024-09-02
收藏 266KB PDF 举报
在本文中,作者分享了一种使用Python进行编程的方法,以高效地爬取知乎平台上那些备受关注、言简意赅的“神回复”。文章以75条为例,展示了如何通过60行代码轻松实现这一过程。首先,作者强调了爬取知乎神回复的关键在于筛选出赞同数量多且内容简短的回答,这些通常具备较高的阅读价值。
具体操作分为两步:第一步是爬取知乎的特定话题内容。作者提供了一个名为`get_answers_by_page`的函数,该函数接受话题ID和页面编号作为输入,通过`requests`库发送GET请求获取指定话题的页面数据。为了模拟真实用户,函数设置了自定义的User-Agent,并设置`verify=False`以绕过SSL证书验证。获取到的网页内容被解析成JSON格式,然后存储到MongoDB数据库中,同时记录下已爬取的话题和页面信息。
值得注意的是,在爬取过程中,作者特别提到了几个关键字段,如赞同数(可能影响回复是否被视为“神回复”)、字数等,这些在筛选过程中起到决定性作用。黄框标记的部分可能是代码中的关键变量或数据结构,它们可能包括`items`(存储的回答列表)以及用于后续分析的数据字段。
通过这种方法,读者不仅可以了解到如何运用Python的网络爬虫技术,还能学习到如何有效地处理和存储数据,以及如何根据需求定制筛选规则。这对于希望提升编程技能、掌握爬虫实践的读者来说,是一份具有实用性和趣味性的教程,能够帮助他们在学习过程中提高效率并收获乐趣。无论是对于编程新手还是经验丰富的开发者,这篇文章都提供了有价值的学习材料。
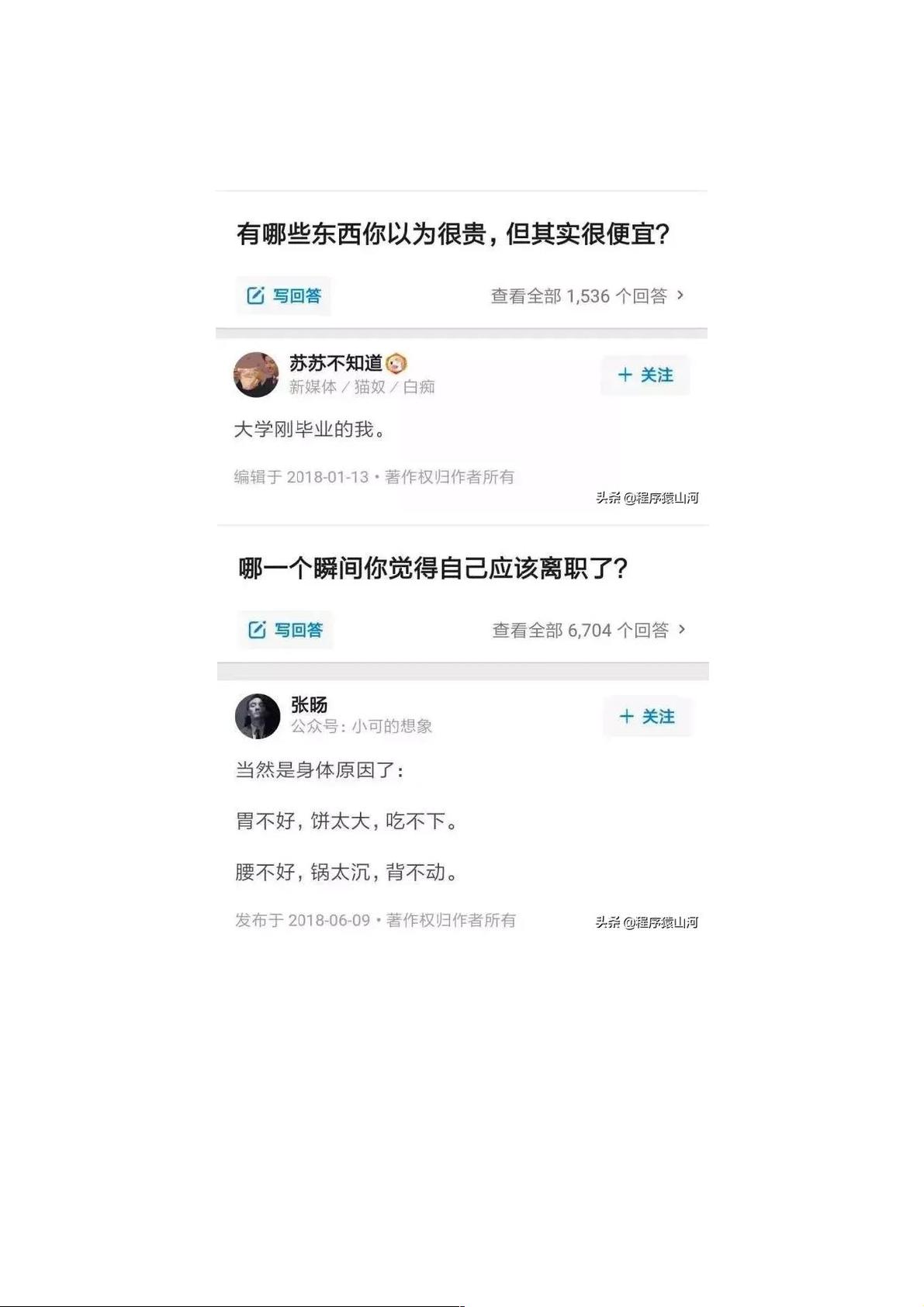
75条笑死人的知乎神回复,用条笑死人的知乎神回复,用60行代码就爬完了行代码就爬完了
主要介绍了python爬取知乎回复,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们
下面随着小编来一起学习学习吧
读:知乎神回复都有些什么特点呢?其实爬取知乎神回复很简单,这篇文章我们就来揭晓一下背后的原理。
我们先来观察一下:
大家看出什么规律了么?短小精辟有没有?赞同很多有没有?所以爬取知乎神回复我们只要爬取那些赞同多又字数少的回答就可以。简单的两个步骤就能
实现,第一步爬取知乎回答,第二部筛选回答。是不是很easy?
01 爬取知乎回答
第一步我们爬取知乎上的回答。知乎上的回答太多了,一下子爬取所有的回答会很费时,我们可以选定几个话题,爬取这几个话题里的内容。
下面的函数用于爬取某一个指定话题的内容:
def get_answers_by_page(topic_id, page_no):
offset = page_no * 10
url = <topic_url> # topic_url是这个话题对应的url
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
}
r = requests.get(url, verify=False, headers=headers)
content = r.content.decode("utf-8")
data = json.loads(content)
is_end = data["paging"]["is_end"]
items = data["data"]
client = pymongo.MongoClient()
db = client["zhihu"]
if len(items) > 0:
db.answers.insert_many(items)
下载后可阅读完整内容,剩余4页未读,立即下载
2021-11-02 上传
2020-12-23 上传
点击了解资源详情
2019-07-31 上传
102 浏览量
点击了解资源详情

weixin_38697471
- 粉丝: 6
- 资源: 980
 我的内容管理
展开
我的内容管理
展开







