Lambda架构:实时数据处理的创新方案
需积分: 0 156 浏览量
更新于2024-06-16
收藏 979KB PDF 举报
"Lambda Architecture - Realtime Data Processing paper"
Lambda架构是一种大数据处理模型,由Nathan Marz提出,旨在解决大数据实时处理的挑战。该架构的主要目标是结合批处理和流处理的优势,提供强一致性和高可用性。Lambda架构的核心思想是将数据处理分为三个独立但相互关联的层:批处理层、流处理层和服务层。
1. 批处理层(Batch Layer):
这一层负责对所有历史数据进行完整的、离线的批量处理。批处理层通常使用Hadoop MapReduce或Apache Spark等工具,它们能够处理大规模的数据集,并且可以确保数据处理的最终一致性。批处理层的优点在于其可扩展性和容错性,它能处理大量数据并生成结果,这些结果用于构建数据的静态视图。
2. 流处理层(Stream Layer):
流处理层专注于实时或近实时的数据处理,它处理新产生的数据流。这一层通常使用Apache Kafka、Apache Flink或Apache Storm等流处理框架,它们能够快速处理数据流并提供低延迟的响应。流处理层确保了数据的实时性和新鲜度,适用于需要即时反馈的应用场景,如实时监控、报警系统等。
3. 服务层(Serving Layer):
服务层是用户查询和应用交互的接口,它结合了批处理层和流处理层的结果,提供一致的视图。服务层通常通过缓存机制(如Redis或Memcached)或者数据库(如Cassandra或HBase)来实现。当用户查询时,服务层会优先返回流处理层的最新结果,如果需要更精确的数据,再回溯到批处理层获取历史数据。
Lambda架构的一个关键特性是它的冗余设计,即使某个部分发生故障,其他部分仍能继续工作,保证了系统的高可用性。此外,由于批处理层和流处理层的结果在服务层合并,用户可以在不牺牲实时性的同时,获取到准确的历史分析结果。
然而,Lambda架构也存在一些挑战和缺点,例如维护三个独立的处理层可能会增加复杂性,需要更多的资源投入。此外,对于数据的存储和处理会有重复,可能导致成本增加。尽管如此,Lambda架构仍然是许多大型企业和组织处理实时大数据问题时的首选方案,特别是在需要强一致性和高可用性的场景下。
Lambda架构在实际应用中,如金融交易监控、社交媒体分析、物联网(IoT)数据处理等领域都展现出了强大的能力。随着技术的发展,Lambda架构也在不断演进,例如Kappa架构提出将流处理层作为唯一的数据处理方式,而Lambda架构则被视为一种过渡形态,帮助组织逐步过渡到全实时的数据处理模式。
A) BATCH LAYER
The crux of the LA is the master dataset. The
master dataset constantly receives new data in an
append-only fashion. This approach is highly
desirable to maintain the immutability of the data.
In the book
[3]
, Marz stresses on the importance of
immutable datasets. The overall purpose is to
prepare for human or system errors and allow
reprocessing. As values are overridden in a
mutable data model, the immutability principle
prevents loss of data. Secondly, the immutable
data model supports simplification due to the
absence of indexing of data. The master dataset
in the batch layer is ever growing and is the
detailed source of data in the architecture. The
master dataset permits random read feature on the
historical data. The batch layer prefers re-
computation algorithms over incremental
algorithms. The problem with incremental
algorithms is the failure to address the challenges
faced by human mistakes. The re-computational
nature of the batch layer creates simple batch
views as the complexity is addressed during
precomputation. Additionally, the responsibility
of the batch layer is to historically process the
data with high accuracy. Machine learning
algorithms take time to train the model and give
better results over time. Such naturally
exhaustive and time-consuming tasks are
processed inside the batch layer. In the Hadoop
framework, the master dataset is persisted in the
Hadoop File System (HDFS)
[6]
. HDFS is
distributed and fault-tolerant and follows an
append only approach to fulfill the needs of the
batch layer of the LA. Batch processing is
performed with the use of MapReduce jobs than
run at constant intervals and calculate batch
views over the entire data spread out in HDFS.
The problem with the batch layer is high-latency.
The batch jobs must be run over the entire master
dataset and are time consuming. For example,
there might be some MapReduce. jobs that are
run after every two hours. These jobs can process
data that can be relatively old as they cannot keep
up with the inflow of stream data. This is a serious
limitation for real-time data processing. To
overcome this limitation, the speed layer is very
significant.
B) SPEED LAYER
[3] and [5] state that real-time data processing is
realized because of the presence of the speed
layer. The data streams are processed in real-time
without the consideration of completeness or fix-
ups. The speed layer achieves up-to-date query
results and compensates for the high-latency of
the batch layer. The purpose of this layer is to fill
in the gap caused by the time-consuming batch
layer. In order to create real-time views of the
most recent data, this layer sacrifices throughput
and decreases latency substantially. The real-
time views are generated immediately after the
data is received but are not as complete or precise
as the batch layer. The idea behind this design is
that the accurate results of the batch layer
override the real-time views, once they arrive.
The separation of roles in the different layers
account for the beauty of the LA. As mentioned
earlier, the batch layer participates in a resource
intensive operation by running over the entire
master dataset. Therefore, the speed layer must
incorporate a different approach to meet the low-
latency requirements. In contrast to the re-
computation approach of batch layer, the speed
layer adopts incremental computation. The
incremental computation is more complex, but
the data handled in the speed layer is vastly
smaller and the views are transient. A random-
read/random-write methodology is used to re-use
and update the previous views. There is a
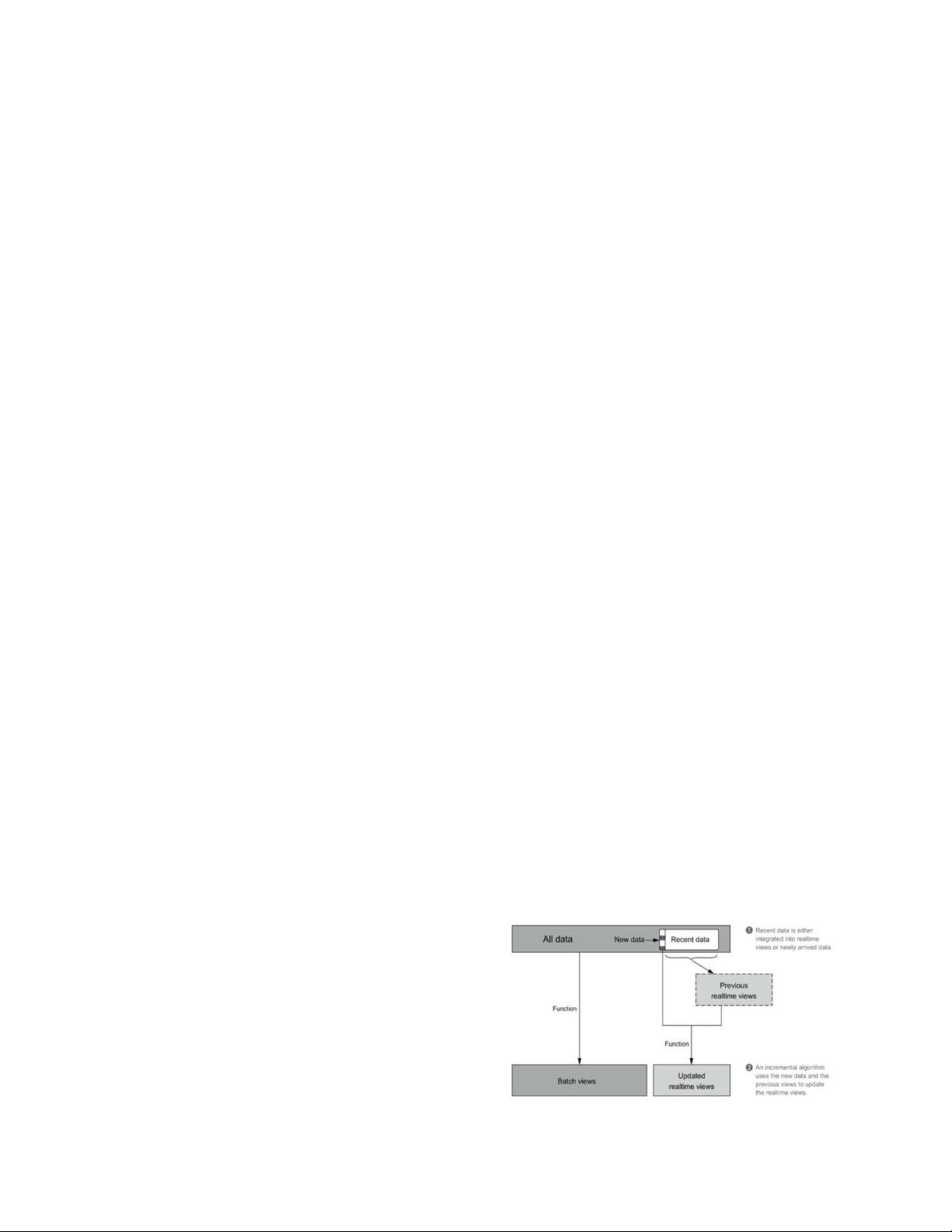
demonstration of the incremental computational
strategy in the Fig. 2.
剩余19页未读,继续阅读
2023-08-26 上传
2023-09-09 上传
2021-03-20 上传
2021-05-10 上传
2023-09-09 上传
2021-03-14 上传
110 浏览量
2023-08-29 上传


roman_日积跬步-终至千里
- 粉丝: 1w+
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- PIC24FGA中文数据手册
- 电子类常用元器件缩略语大全下载
- “TFT LCD使用心得”
- 将来的ORACLE SOA架构
- Clementine完整教程.pdf
- wince 电源管理
- oraclean安装说明
- DWR中文文档.pdf
- 软件开发设计模式C++版
- Struts Spring Hibernate 整合引用2008
- Better J2EEing with Spring
- 网络安全体系-----关于网络安全体系的讲解。
- EJB3[1].0开发手册.pdf
- java 解惑 java书籍中经典中的经典
- Java EE 5 Power and productivity with less complexity.doc
- 08下半年网工上午题.pdf
