MySQL中嵌套集合模型:高效管理分层数据
需积分: 9 158 浏览量
更新于2024-07-31
收藏 252KB PDF 举报
在《嵌套集合模型》这篇文章中,作者探讨了如何在MySQL中有效地管理分层数据,特别是对于那些具有层级关系的数据,如电子商店的产品分类。通常,人们认为关系数据库不适合处理这种非线性结构的数据,因为它们基于表格的扁平化设计无法自然地体现层次关系。
邻接表模型是处理分层数据的一种常见方法,它将每个节点表示为一个独立的表行,同时通过一个外键链接到它的父节点。在提供的示例中,"category"表定义了一个简单的结构,包含category_id(主键)、name(类别名)和parent(父类别ID)。通过这种方式,像电视(TELEVISIONS)这样的子类别关联到其父类别(ELECTRONICS),形成一个树形结构。
然而,文章接下来将介绍另外两种模型来处理分层数据。第一种可能是路径查询(Path Query Model),它存储了从根节点到每个叶子节点的完整路径,虽然这种方法可以支持复杂查询,但可能会导致存储冗余,尤其是在层级深度较大的情况下。
另一种可能涉及递归查询或者使用扩展的属性来存储额外的信息,比如一个字段用来存储所有祖先类别,这称为深度优先搜索(Depth-First Search,DFS)或广度优先搜索(Breadth-First Search,BFS)模型。这种方法可以减少冗余,但在性能上可能不如邻接表模型,特别是在频繁更新层级结构时。
作者Mike Hillyer旨在提供对比和选择,让读者根据具体应用场景的性能需求和数据规模,决定哪种模型更适合他们的MySQL数据库。在实践中,可能需要权衡存储效率、查询性能和维护复杂性的平衡,以确保分层数据的高效管理和查询。
总结来说,这篇文章不仅涵盖了邻接表模型在MySQL中的应用,还深入讨论了如何通过其他模型来优化处理分层数据,为数据库管理员和开发人员提供了实用的策略来应对复杂的数据结构挑战。
MYSQL 中分层数据的管理
该分类所在的层次。另外,我们在删除节点的时候要特别小心,因为潜在的可能会孤立一棵
子树(当删除 portable electronics 分类时,所有他的子分类都成了孤儿)。部分局限性
可以通过使用客户端代码或者存储过程来解决,我们可以从树的底部开始向上迭代来获得一
颗树或者单一路径,我们也可以在删除节点的时候使其子节点指向一个新的父节点,来防止
孤立子树的产生。
嵌套集合(Nested Set)模型
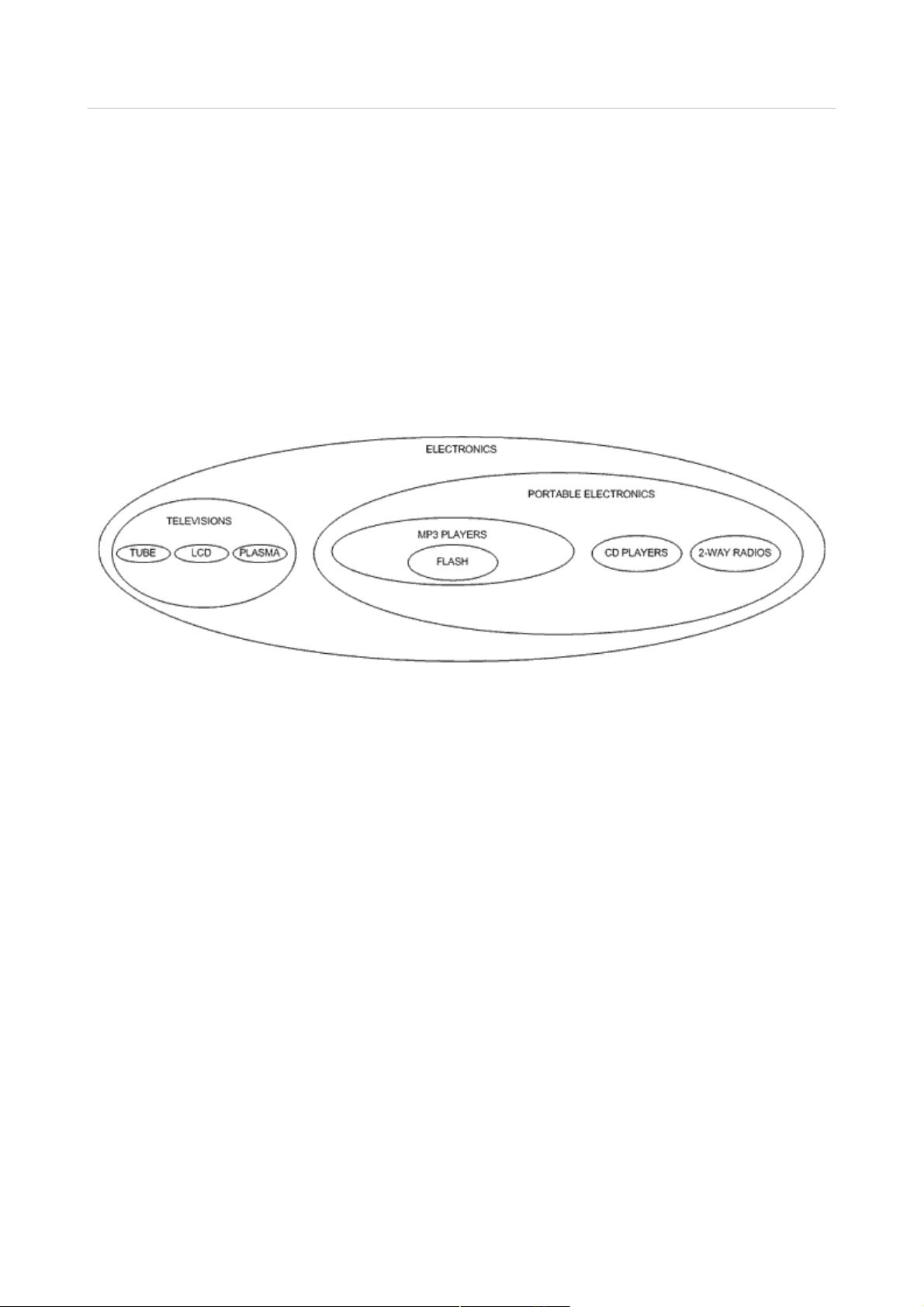
我想在这篇文章中重点阐述一种不同的方法,俗称为嵌套集合模型。在嵌套集合模型中,我
们将以一种新的方式来看待我们的分层数据,不再是线与点了,而是嵌套容器。我试着以嵌
套容器的方式画出了 electronics 分类图:
从上图可以看出我们依旧保持了数据的层次,父分类包围了其子分类。在数据表中,我们通
过使用表示节点的嵌套关系的左值(left value)和右值(right value)来表现嵌套集合模型
中数据的分层特性:
CREATE TABLE nested_category (
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
lft INT NOT NULL,
rgt INT NOT NULL
);
INSERT INTO nested_category
VALUES(1,'ELECTRONICS',1,20),(2,'TELEVISIONS',2,9),(3,'TUBE',3,4),
(4,'LCD',5,6),(5,'PLASMA',7,8),(6,'PORTABLE ELECTRONICS',10,19),
(7,'MP3 PLAYERS',11,14),(8,'FLASH',12,13),
(9,'CD PLAYERS',15,16),(10,'2 WAY RADIOS',17,18);
SELECT * FROM nested_category ORDER BY category_id;
+-------------+----------------------+-----+-----+
| category_id | name | lft | rgt |
+-------------+----------------------+-----+-----+
| 1 | ELECTRONICS | 1 | 20 |
| 2 | TELEVISIONS | 2 | 9 |
| 3 | TUBE | 3 | 4 |
| 4 | LCD | 5 | 6 |
| 5 | PLASMA | 7 | 8 |
| 6 | PORTABLE ELECTRONICS | 10 | 19 |
第 4 页/总 16 页
剩余15页未读,继续阅读
2021-01-07 上传
2019-08-04 上传
2018-10-17 上传
2020-02-27 上传
2009-01-02 上传
2011-05-03 上传
2024-07-05 上传
2009-06-11 上传
760 浏览量

JakcyChen1
- 粉丝: 2
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
