Transformer模型解析:Self-Attention与并行计算
113 浏览量
更新于2024-08-29
1
收藏 2.25MB PDF 举报
"NLP课程,Transformer模型,Self-Attention机制,Positional Encoding,Layer Normalization,Transformer Encoder与Decoder"
在自然语言处理(NLP)领域,Transformer模型的出现极大地推动了序列模型的发展,解决了传统RNN(循环神经网络)面临的梯度消失和并行计算难题。Transformer模型的核心在于其Self-Attention机制,它能有效捕捉输入序列中的长距离依赖关系,而不再局限于RNN的顺序计算。
1. Seq2seq模型:Seq2seq(Sequence to Sequence)模型通常由一个编码器(Encoder)和一个解码器(Decoder)组成,用于任务如机器翻译。然而,基于RNN的Seq2seq模型受限于RNN的梯度消失问题和序列计算的串行特性,导致训练效率低下。
2. Transformer:Transformer模型由Vaswani等人在2017年提出,完全放弃了RNN和CNN,采用自注意力(Self-Attention)机制替代,使得模型可以在并行计算中处理整个序列,显著提升了训练速度。Transformer模型包括两个主要部分:Encoder用于理解输入序列,Decoder用于生成输出序列。
3. Self-Attention机制:Self-Attention允许模型在计算每个位置的表示时考虑所有其他位置的信息,形成一个全局上下文的视图。这通过三个矩阵的计算实现:查询(Query)、键(Key)和值(Value),它们分别对应输入序列的不同视角,通过内积计算注意力权重,再加权求和得到上下文丰富的表示。
4. Positional Encoding:由于Transformer模型没有内置的位置感知能力,为了保留序列信息,引入了Positional Encoding。这是一系列正弦和余弦函数的组合,为每个位置赋予一个唯一的向量,使得模型能够识别序列中的相对位置。
5. Layer Normalization:在Transformer的每一层中,都采用了Layer Normalization技术,以稳定训练过程,减少内部协变量转移问题,提高模型的收敛速度和性能。
6. Transformer Encoder与Decoder:Encoder由多个相同的层组成,每个层包含一个Self-Attention子层和一个前馈神经网络(FeedForward)子层。Decoder同样由多层构成,除了Self-Attention外,还包括一个对Encoder输出进行注意力操作的Cross-Attention子层,以确保正确地生成依赖于源序列的输出序列。
7. 总结:Transformer模型因其高效并行计算和强大的上下文捕捉能力,在NLP领域得到广泛应用,如BERT、GPT等预训练模型均基于Transformer架构。它的设计思路对后来的模型产生了深远影响,成为现代深度学习NLP研究的重要基础。
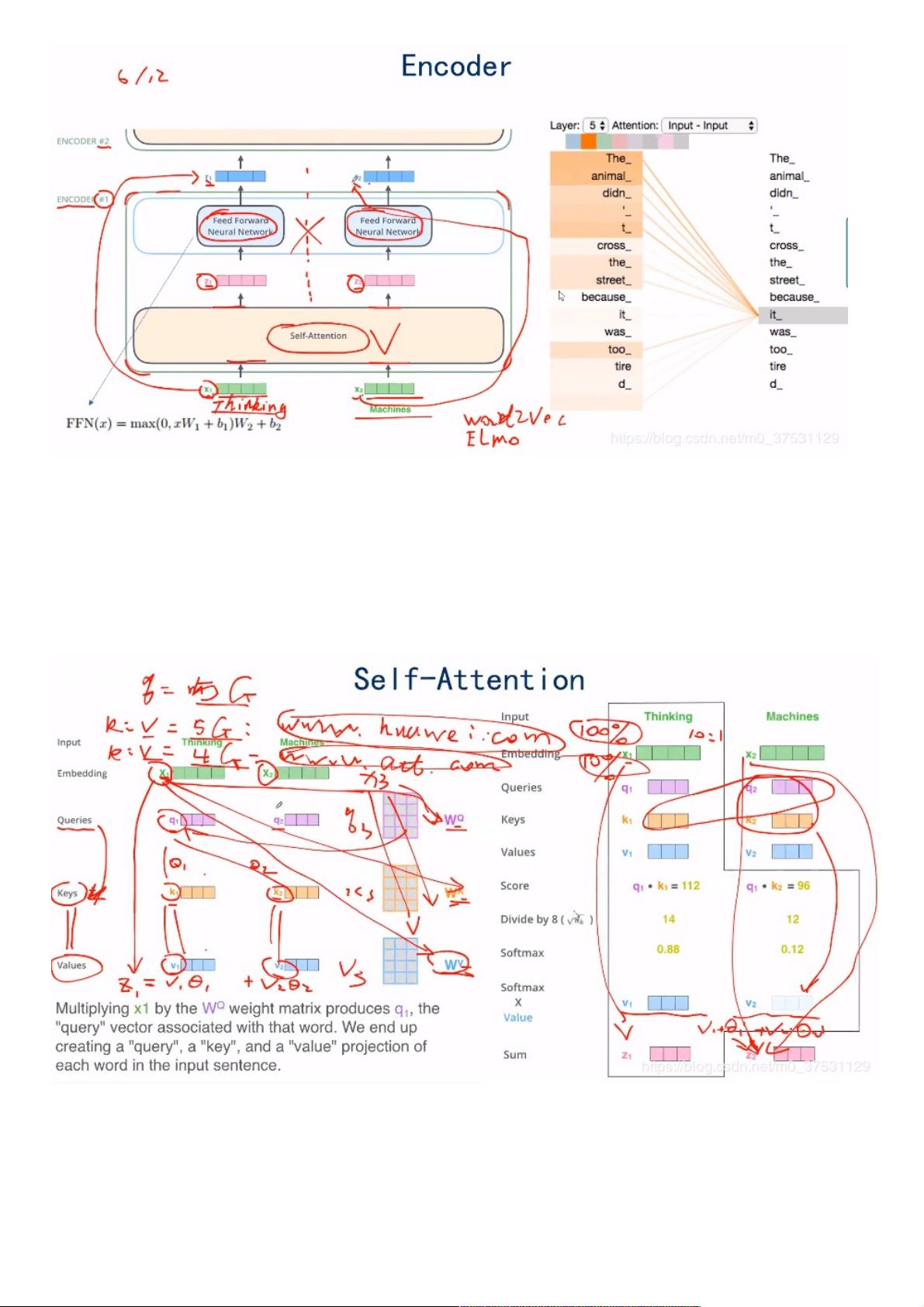
Encoder 里面有 self-attention + FeedForward.
Self-attention 是 把 X(input embedding)转成 Z. 这里的转换是结合所有的输入,通过self-attention 转成Z输出,所以这里Z
对应的每个矩阵都是结合了上下文的矩阵。
FNN 是全连接层:把Z输出成R,这里面是单纯的全连接神经网络。只是将Z转换成R。
3. Self-Attention 机制详解机制详解
我们来看self-attention 是如何工作的?是如何把X 映射成Z?
请注意: self-attention 的目的是 句子内部,一些词之间的 关联性或者说 相关性 的强弱程度。(翻译模型Encode-Decoder 里面
有其他的attention 是输入和输出之间的attention,不是句子内部的self-attention)
X1 和X2 分别同时乘上 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV 得到 q1,q2, k1,k2, v1,v2. 这里所有输入 Xi 都乘上相同的
WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV ,所以在一定程度有一定的关系。
然后x1x_1x1 对应的score 是 q1∗k1,q2∗k2,q1∗k3q_1* k_1, q_2 * k_2 , q_1*k_3q1∗k1,q2∗k2,q1∗k3… —>divide by 8 –>
softmax 得到一系列概率值, 然后将 v1,v2, v3 分别与概率值对应相乘,得到softmax * value 一系列 向量矩阵,最后通过
Sum 得到Z1Z_1Z1.
W(q,k,v) 是随机初始化的,由于X1,X2,X3。。最初的embedding是没有关系的,通过与W(qkv)相乘,得到使得 X1,X2,X3 有关
联的 query,key,value. 在self-attention 时,就是同过Xi 的 query 与 每个输入单词的 key 相乘(除以8),然后softmax得到 Xi
与 所有 输入单词 之间的相关概率,然后将 每个单词的value 与 这个概率相乘 就可以得到 与Xi 相关的向量,最后将所有的向量
相加,就可以得到 Xi 对应的 Zi。这里的Zi 就是self-attention 输出的Zi.
剩余13页未读,继续阅读
2021-10-01 上传
2024-09-10 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38659805
- 粉丝: 6
- 资源: 914
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
