HDFS深入解析:写读流程与NameNode关键机制
167 浏览量
更新于2024-08-30
收藏 248KB PDF 举报
HDFS详解②深入探讨了Apache Hadoop分布式文件系统(Hadoop Distributed File System, HDFS)的数据流管理和关键组件的工作原理。本篇文章着重讲解了HDFS的写数据和读数据流程,以及NameNode和SecondaryNameNode的角色及其功能。
**4.1 HDFS写数据流程**
HDFS写数据涉及多个步骤:
1. 客户端通过DistributedFileSystem模块向NameNode发起文件上传请求,NameNode负责检查文件路径的有效性和资源可用性。
2. 如果允许,NameNode分配存储Block的DataNode,并返回这些节点的地址。
3. 客户端与DataNode建立多级通信,首先连接最接近的DataNode,如dn1,然后dn1再将数据分发给其他副本节点。
4. 数据块在上传过程中,每个节点以Packet为单位传输,同时保持应答机制,确保数据完整性。
5. 当一个Block上传完成后,客户端会继续上传下一个Block,直至所有Block复制完成。
**4.1.2 网络拓扑-节点距离计算**
在数据写入时,为了优化性能,NameNode会基于节点之间的网络拓扑,选择距离目标DataNode最近的节点开始数据传输。节点间的距离是通过计算它们到达最近共同祖先节点的路径长度之和来确定的。
**4.1.3 机架感知(副本存储节点选择)**
HDFS采用机架感知策略,目的是将数据副本存储在不同机架上,以减少单个故障对系统的影响。NameNode在选择DataNode时优先考虑同一机架内的节点,以实现跨机架的负载均衡和高可用性。
**5. NameNode和SecondaryNameNode**
NameNode是HDFS的核心组件,负责管理元数据,包括文件系统的命名空间和文件块分布。而SecondaryNameNode作为辅助,定期与主NameNode同步元数据,执行Checkpoint操作,以及在主NameNode失效时接管其职责。
- **5.1 NN和2NN工作机制**
- NameNode启动后,开始接受客户端的写入请求和维护元数据。
- SecondaryNameNode在NameNode运行一段时间后开始工作,它会周期性地下载NameNode的元数据,进行校验并保存到本地的Fsimage文件中,同时记录修改操作到Edits日志文件。
- **5.2 Fsimage和Edits解析**
- Fsimage是HDFS元数据的持久化表示,包含了完整的文件系统状态。
- Edits文件记录了Fsimage变化的历史,用于在NameNode故障恢复时重建元数据。
- 学习如何使用`oiv`和`oev`命令分别查看Fsimage和Edits文件内容,了解元数据管理的细节。
- **5.3 CheckPoint时间设置**
- 正确设置Checkpoint时间有助于防止元数据过大导致的NameNode性能下降,通过定期将元数据写入Fsimage文件,减小内存压力。
- **5.4 NameNode故障处理**
- NameNode的故障恢复过程涉及到SecondaryNameNode的辅助,如果主NameNode发生故障,SecondaryNameNode会接替为主,利用已有的Fsimage和Edits文件进行元数据恢复。
本文深入剖析了HDFS的内部工作原理,对于理解分布式文件系统设计、数据写入和读取的优化策略,以及NameNode和SecondaryNameNode在系统中的关键作用至关重要。这对于Hadoop开发者和运维人员来说,是理解和应对HDFS复杂性的重要知识点。
HDFS详解详解②
HDFS
文章目录文章目录HDFS4 HDFS的数据流4.1 HDFS写数据流程4.1.1 剖析文件写入4.1.2 网络拓扑-节点距离计算4.1.3 机架感知(副本
存储节点选择)4.2 HDFS读数据流程5 NameNode和SecondaryNameNode(面试开发重点)5.1 NN和2NN工作机制1. 第一
阶段:NameNode启动2. 第二阶段:Secondary NameNode工作5.2 Fsimage和Edits解析5.2.1. 概念5.2.2 oiv查看Fsimage文
件5.2.3 oev查看Edits文件5.3 CheckPoint时间设置5.4 NameNode故障处理
4 HDFS的数据流的数据流
4.1 HDFS写数据流程写数据流程
4.1.1 剖析文件写入剖析文件写入
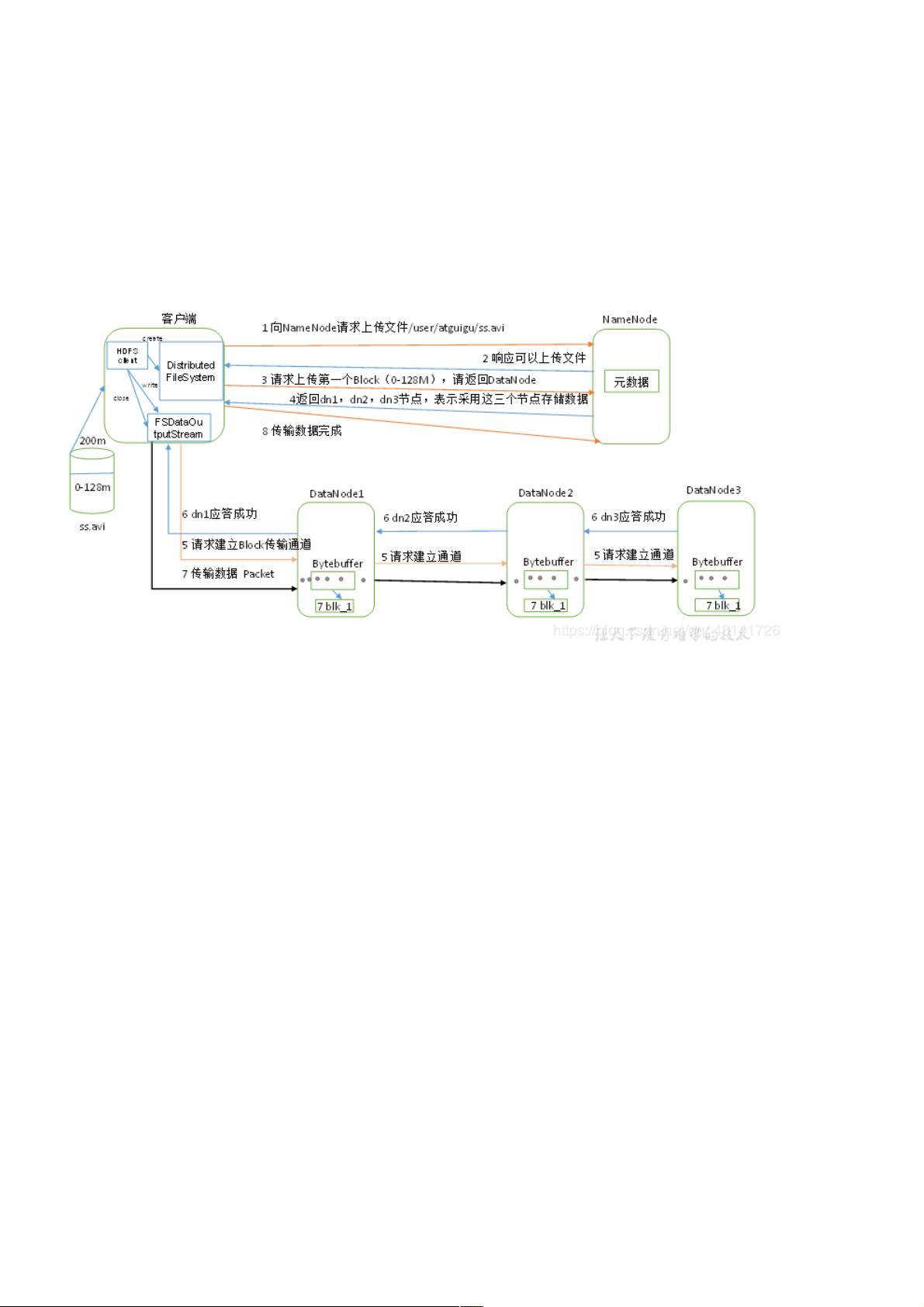
HDFS写数据流程写数据流程
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存
在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管
道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet
就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
4.1.2 网络拓扑网络拓扑-节点距离计算节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算
呢?
节点距离节点距离:两个节点到达最近的共同祖先的距离总和。
下载后可阅读完整内容,剩余6页未读,立即下载
2022-08-04 上传
227 浏览量
319 浏览量
点击了解资源详情
点击了解资源详情
194 浏览量
点击了解资源详情
107 浏览量
点击了解资源详情

weixin_38638647
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- UltralSO工具:制作及刻录ISO系统启动盘
- iOS Swift 弹出视图:自定义提示框与加载框教程
- 易语言实现BWSQL数据库处理的源码分享
- NGR转ISO工具:NERO专用格式转换成ISO文件
- 掌握JavaScript项目的网络化测试与部署流程
- 深入理解mui框架及其示例应用文档
- iOS原生录音功能实现教程及示例代码下载
- Jumper:Twitch 平台上的 C++ 游戏开发
- 企业微信推送消息实现及媒体文件上传教程
- 易语言实现10进制与2进制互转源码解析
- 江苏计算机二级C语言TC软件使用指南
- GTPS_Hostmaker:打造Growtopia专业服务器平台
- C#实现的串口读写程序详解
- 探索PlexHaxx: 将万源媒体一网打尽
- 打造个性化iOS分段选择器YTSegmentDemo
- 深入探索SP2框架:Studio Studio 2的C语言实现
