提升Speculative Multithreading效率:样本相似性清洗策略
162 浏览量
更新于2024-08-26
收藏 618KB PDF 举报
推测性多线程处理(Speculative Multithreading, SpMT)是一种在多核系统上加速顺序程序的自动并行化技术。其核心思想是通过将程序分解为可执行的线程片段,以便在预期的执行路径上实现并发执行。然而,这种技术的效果很大程度上取决于样本的选择,特别是那些能够有效推动线程划分和并行评估的样本。
在SpMT中,"类似样本清洗"(SimilarSamplesCleaning)是一个关键步骤。这里的“样本”通常是指程序执行期间的行为模式或特征,它们被表示为固定长度的特征向量。为了实现这一过程,编译时使用Prophet这样的分析工具,它通过特征提取程序将每个程序映射成一个六元组(N1, N2, N3, N4, N5, N6),其中Ni代表特定特征出现的次数。这六个指标共同刻画了程序执行的特性,如指令集使用、内存访问模式等。
清洗相似样本的重要性主要体现在两个方面:
1. **去除冗余**:冗余样本是指那些在功能或行为上重复度高的部分,它们可能会导致线程划分的无效或者资源浪费。通过识别并消除这些重复的样本,可以提高并行执行的效率和资源利用率。
2. **降低相似度阈值**:在并行线程中,如果存在高度相似的样本,可能导致竞争条件和资源冲突。因此,确保样本之间的差异性有助于减少潜在的竞态问题,保证程序的正确性和性能。
清洗过程涉及以下步骤:
- **特征提取**:在程序运行期间,使用编译时的分析工具(如Prophet)对程序执行进行监控,记录各种特征的出现频率。
- **样本特征向量构建**:根据收集到的特征,为每个样本生成一个特征向量,用于量化其行为特性的表示。
- **相似性检测**:通过设计比较算法,比如基于距离的度量(如欧氏距离、余弦相似度等),检查样本间的相似程度,判断是否需要进一步处理。
- **清洗决策**:根据预设的阈值,决定哪些相似度较高的样本需要合并或替换,以避免并行线程中的问题。
总结来说,推测性多线程处理中的类似样本清洗是优化并行执行效率的关键环节,通过识别并处理冗余和高相似度样本,可以提升程序的并发性能,同时确保并发执行的正确性和资源的有效利用。这项研究对于理解和改进现代多核处理器上的并行编程实践具有重要意义。
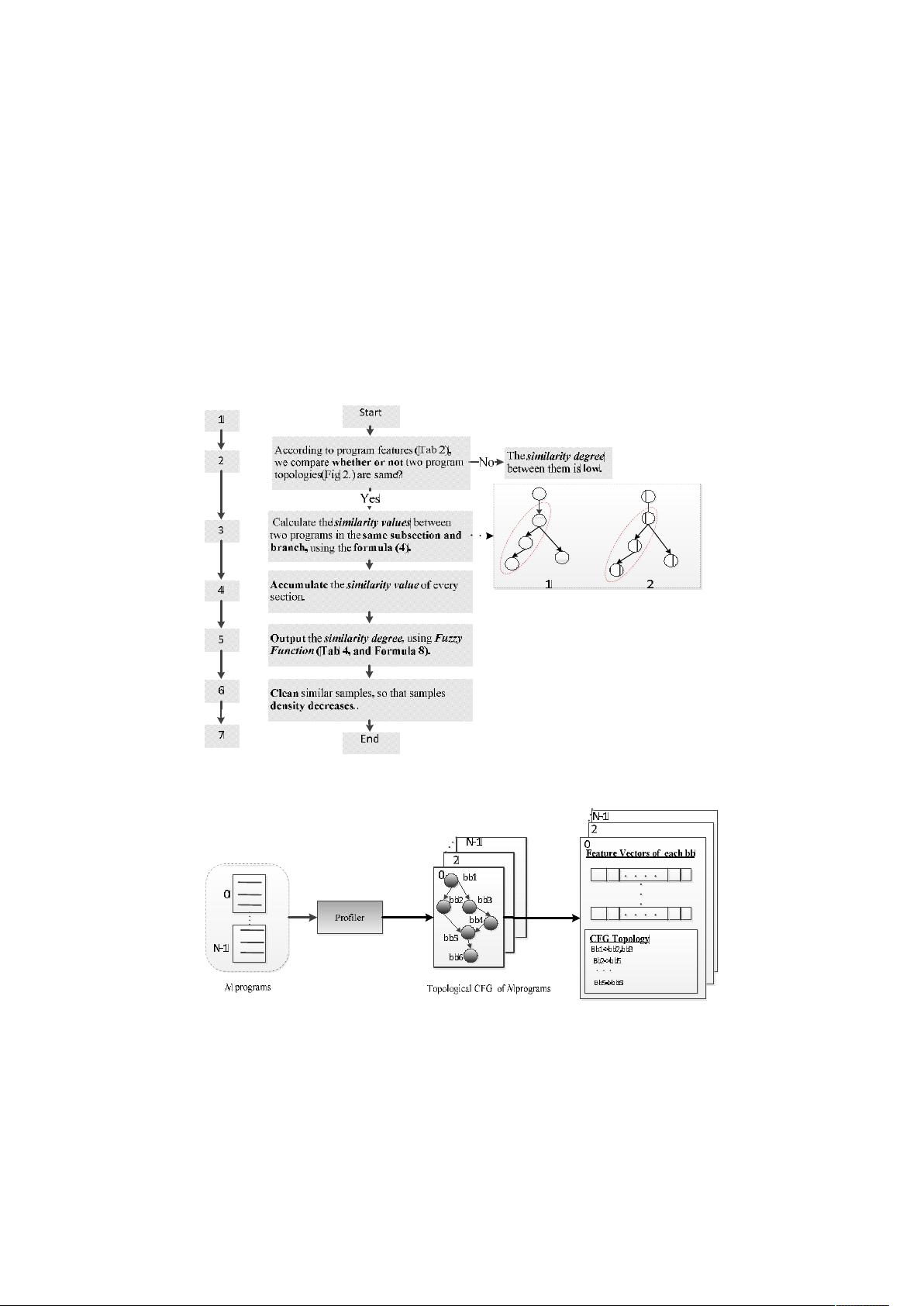
2.1 Extracting Feature Vectors
In this section, we motivate the applicability of using the program’s source code as
input for finding the program features. Table 1 shows an example of source codes.
With regard to a program, we first establish the corresponding structured diagram.
Then, we extract the features from the structured diagram. Figure 2 shows the
associative process of collecting sample features. How can we characterize a program
is to be solved. We need extract features to represent it. As we use the static characters
to stand for a procedure, we use the features shown in Table 2 [7] to form the
vectors.
Fig. 1. Flow chart of similar samples cleaning
Fig. 2. Collecting different program features
剩余13页未读,继续阅读
2021-03-10 上传
2010-10-12 上传
2023-08-30 上传
2023-07-25 上传
2023-11-26 上传
2023-07-16 上传
2023-09-07 上传
2023-08-06 上传
2023-07-25 上传

weixin_38499349
- 粉丝: 2
- 资源: 961
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
