加密重复数据删除中的信息泄漏:频率分析攻击与防御策略
44 浏览量
更新于2024-07-15
收藏 1.22MB PDF 举报
"这篇研究论文探讨了在加密重复数据删除过程中通过频率分析导致的信息泄漏问题,提出了攻击策略以及相应的防御措施。加密重复数据删除技术旨在同时确保数据安全性和存储效率,但采用确定性加密方法可能会暴露原始明文块的频率分布,从而使攻击者能够对密文块进行频率分析,推测出原始明文块的内容。作者们深入研究了频率分析如何影响信息安全性,并提出了可能的解决方案。"
在现代信息技术中,数据的安全性和存储效率是两个至关重要的方面。加密重复数据删除(Encrypted Deduplication)技术应运而生,它结合了加密和重复数据删除的功能,以保护数据的机密性,同时优化存储空间。然而,这项技术并非没有缺陷。本文的焦点在于揭示了一种特定的威胁——通过频率分析(Frequency Analysis)来利用确定性加密(Deterministic Encryption)的弱点。
确定性加密是一种在加密过程中始终产生相同密文的加密算法,这对于保留数据的可重复性非常有用,因为相同的明文会映射到相同的密文,从而实现数据去重。但是,这种特性也为潜在的攻击者打开了大门。攻击者可以利用频率分析,即通过对出现频率高的字符或数据块进行统计,来推断出加密数据的潜在模式,进一步可能还原出原始明文。
论文中,作者们详细阐述了如何执行这种针对加密数据的频率分析攻击,展示了在实际场景下,攻击者如何通过收集和分析加密数据的频率分布来揭示敏感信息。此外,他们还讨论了这些攻击可能带来的具体风险,例如隐私泄露、数据篡改等。
为了应对这种威胁,作者提出了防御策略。这些策略可能包括使用概率加密(Probabilistic Encryption),这种方法在加密相同明文时会产生不同的密文,使得频率分析变得更加困难。同时,他们可能还建议采用混淆技术,如添加随机数据,以干扰频率分布,增加攻击者的解密难度。
这篇研究论文揭示了加密重复数据删除系统中的一个潜在安全隐患,并提供了对抗频率分析攻击的思路。对于设计和实施加密系统的专业人员来说,理解并应用这些防御策略对于提升数据安全性和保护用户隐私至关重要。
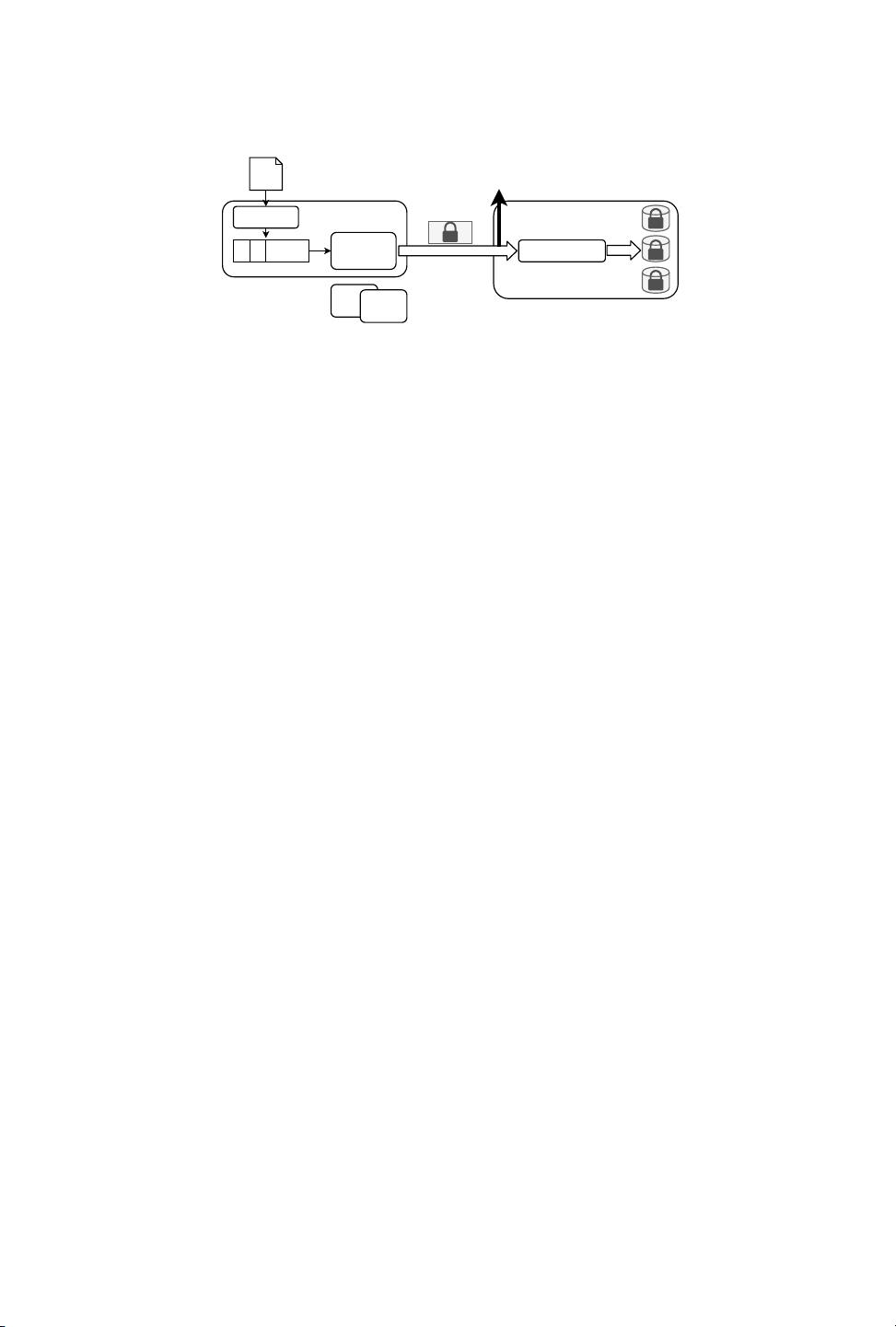
1:6 Li et al.
ChunkChunk
File
Chunking
MLE
Protection
Chunk
Chunk
Deduplication
......
Tappedbyadversary
MultipleClients
DeduplicatedStorage
Disks
Client
Client
Client
Fig. 2. Architecture of encrypted deduplication.
file, a client divides file data into plaintext chunks that will be encrypted via MLE. It then uploads
the ciphertext chunks to deduplicated storage. An adversary can eavesdrop the ciphertext chunks
before deduplication and launch frequency analysis. We assume that the adversary is honest-but-
curious, meaning that it does not change the prescribed storage system protocols or modify any
stored data.
3.2 Auxiliary Information
To launch frequency analysis, the adversary should have access to the auxiliary information that
provides ground truths about the backups being stored. Prior studies have proposed different
approaches to obtain the auxiliary information to launch inference attacks. We briefly discuss
several representative ones that inspire our work.
•
Naveed et al. [
50
] examine inference attacks against the encrypted databases for electronic
medical records, some of which are protected by deterministic encryption. To evaluate the
feasibility of launching inference attacks, the authors obtain the auxiliary information from a
public user dataset released by the government health services.
•
Grubbs et al. [
28
] infer the plaintexts of the attributes of customer records (e.g., first name, last
name, ZIP codes, birth dates, etc.) stored in an encrypted database. They obtain the auxiliary
information regarding the plaintext distribution via the public census and survey datasets.
•
Bindschaedler et al. [
15
] also infer the plaintexts of the attributes of encrypted customer records
like Grubbs et al. [
28
], but use the public and purchased U.S. voter registration lists as the auxiliary
information. The authors also use the older versions of purchased hospital-discharge data and
public censor data to infer the newer versions of respective data.
•
Grubbs et al. [
27
] focus on Ubuntu Internet Relay Chat (IRC) logs [
2
,
61
] and extract the log
keywords. They generate the keyword query distribution from one year’s Ubuntu IRC logs as
the auxiliary information to infer the encrypted keywords in the logs of a later year.
•
Pouliot et al. [
52
] consider the inference attacks against the keywords in the Enron email dataset
[
37
]. They first partition each user’s emails into two non-overlapping sets (i.e., training and
testing sets). They then generate the necessary auxiliary information from the training set, and
infer the content of the testing set that is encrypted.
•
Other studies [
19
,
33
,
66
] also leverage the Enron email dataset. They create a Zipfian synthetic
keyword query distribution from the keyword list of the whole Enron dataset as the auxiliary
information, and use it to infer the keywords in the original dataset that is encrypted.
We observe that previous studies mainly obtain the auxiliary information from private [
15
,
19
,
27
,
33
,
52
,
66
] or public [
15
,
28
,
50
] sources. By private, we mean that the auxiliary information is
originally protected but is obtained through unintended data releases [
10
], data breaches [
29
], or
ACM Trans. Storage, Vol. 1, No. 1, Article 1. Publication date: January 2019.
剩余29页未读,继续阅读
点击了解资源详情
点击了解资源详情
102 浏览量
2021-04-07 上传
2024-10-25 上传
2024-10-25 上传
2024-10-25 上传
点击了解资源详情
点击了解资源详情

weixin_38662327
- 粉丝: 5
- 资源: 922
 我的内容管理
展开
我的内容管理
展开







