PointNet与PointNet++:3D计算机视觉深度学习入门
版权申诉
176 浏览量
更新于2024-07-04
1
收藏 1.75MB PDF 举报
【3D计算机视觉】从PointNet到PointNet++理论及pytorch代码的讲解深入探讨了三维数据表示及其在计算机视觉中的应用。首先,点云作为一种重要的三维数据形式,由一系列N维坐标点构成,通常用于表示物体的空间位置,有时还包括法向量、强度等额外特征。点云因其原始性和简洁性,在自动驾驶领域,特别是在雷达扫描中,有着显著的优势。
点云处理的历史中,早期的方法包括基于3DCNN的体素模型,这种模型将点云转换为体素网格,再进行卷积操作,但受限于计算资源,处理能力有限,且体素网格难以捕捉点云表面的细节。另一种方法是将点云投影到二维空间,然后使用CNN进行处理,但这往往忽视了点云的原始结构。
PointNet作为一种革命性的网络架构,针对点云的特点进行了创新。PointNet的设计初衷是利用每一点的全局信息,不受点的顺序影响,通过非欧氏空间的嵌入网络,如多层感知器(MLP),对每个点进行独立的特征学习,然后聚合所有点的信息,形成一个全局特征向量。这使得PointNet能够直接处理原始点云,无需先进行预处理或降维,极大地简化了模型。
PointNet的主要组成部分包括输入层(接收N×D维度的点云数据)、多层MLP用于特征提取、全局平均池化层(保持全局不变性)以及全连接层用于最终的分类或回归任务。其核心思想在于,通过共享权重和自注意力机制,PointNet能够有效地捕捉点云中的局部和全局特征,这对于识别形状复杂、无规则分布的物体非常关键。
后续的PointNet++是对PointNet的改进,它引入了局部特征学习,通过分层次采样和 grouping操作,将点云划分为局部区域,进一步提取和融合局部特征,增强了模型的细节捕捉能力。这种层次化的策略允许网络更好地理解和分辨不同部分的点云特征,从而提高了模型的精度和鲁棒性。
在实践中,使用PyTorch实现PointNet和PointNet++时,开发者可以结合论文提供的代码示例,理解如何构建网络结构,如何处理输入数据,以及如何调整超参数以优化模型性能。通过实践和实验,可以更好地掌握这两种方法,并将其应用于实际的3D计算机视觉任务,如对象识别、语义分割、姿态估计等。
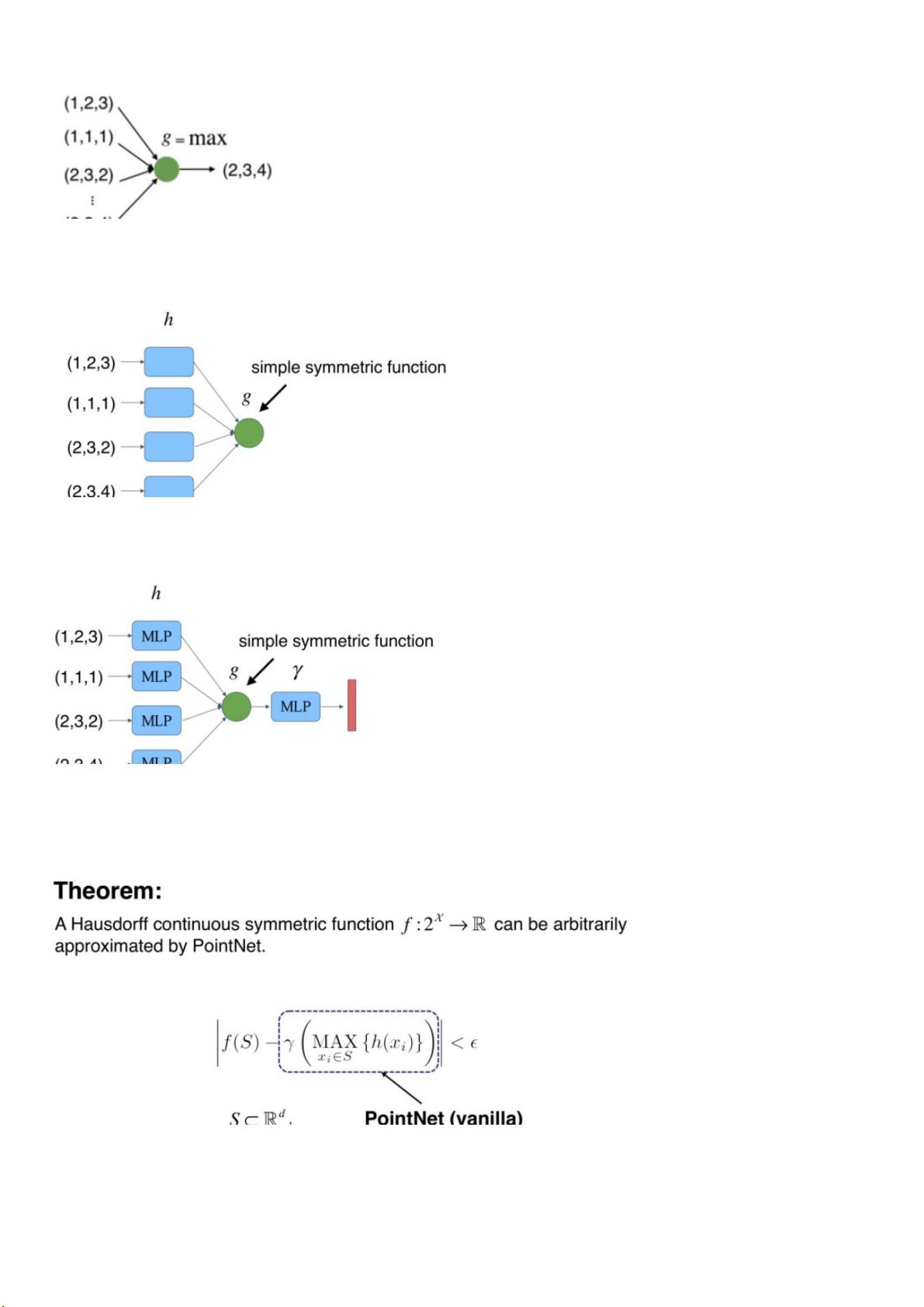
因此我们可以利⽤max函数设计⼀个很简单的点云⽹络,如下:
但是这样的⽹络有⼀个问题,就是每个点损失的特征太多了,输出的全局特征仅仅继承了三个坐标轴上最⼤的那个特征,因此我们不妨先将
点云上的每⼀个点映射到⼀个⾼维的空间(例如1024维),⽬的是使得再次做MAX操作,损失的信息不会那么多。
此时我们发现,当我们将点云的每个点先映射到⼀个冗余的⾼维空间后,再去进⾏max的对称函数操作,损失的特征就没那么多了。由此,
就可以设计出这PointNet的雏形,称之为PointNet(vanilla):
2.1.2 理论证明
论⽂中其实有给出理论的证明,⼤致的意思是:任意⼀个在Hausdorff空间上连续的函数,都可以被这样的PointNet(vanilla)⽆限的逼近。
2.2 基于点云的旋转不变性
剩余17页未读,继续阅读
2021-06-22 上传
2019-09-17 上传
2024-03-29 上传
2023-06-29 上传
点击了解资源详情
2024-09-06 上传
2021-05-14 上传
2021-08-03 上传

_webkit
- 粉丝: 31
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- oracle常用查询代码下载
- Java Portlet 规范-JSR168(英文版)
- 应用程序开发—MVC with Webwork2
- Enterprise-Ajax-Security-with-ICEfaces.pdf
- jsp分页(粘贴就可用)
- sht11源码(基于51单片机的)
- ADO.NET高級編程
- 基于单片机控制的变频调速系统
- playfair.doc
- photoshop cs2 cs3快捷键大全
- Matlab图形图像处理函数
- 综合布线概念详释word
- webservice & uddi 介绍
- asp.net使用技巧大全
- 软件开发者面试百问 不要错过
- CISCO 2500、1600系列路由器使用手册
