"网络数据采集 第五章:RIA网站信息爬取技术与方法详解"
需积分: 0 124 浏览量
更新于2024-01-04
收藏 1004KB PDF 举报
本节课程旨在介绍使用网络爬虫爬取RIA网站信息的具体方法。首先,在引导课前,回顾了前面介绍的爬取RIA网站的一些基础知识。接下来,将重点讲解RIA型网站的技术构成,以及使用Selenium工具来获取ajax驱动网页的页面信息。
RIA网站是指富互联网应用程序,与第一代和第二代Web应用程序相比,其用户界面具有更丰富的功能,更像桌面应用程序。为了实现这些高级用户界面,RIA网站通常使用JavaScript、Flash、Google Web Toolkit、JavaFX或Silverlight等技术在浏览器中执行。
在本节课中,将重点讲解RIA网站的技术构成。首先介绍了RIA的定义和特点,强调了其用户界面更丰富、更高级的特点。然后,重点讲解了RIA网站常用的技术和工具,如JavaScript、Flash、Google Web Toolkit、JavaFX和Silverlight。这些技术和工具可以使RIA网站的用户界面更加动态和交互性。
接着,重点介绍了Selenium工具的使用方法。Selenium是一种自动化测试工具,可以模拟用户在浏览器中的操作行为。通过使用Selenium,可以实现对RIA网站的数据爬取。Selenium可以模拟用户在浏览器中的点击、滚动、输入等操作,并获取网页中通过ajax加载的数据。
在总结课程内容后,给出了本节课的课后练习。课后练习旨在帮助学生进一步巩固和应用所学知识,提高对RIA网站数据爬取技术的掌握程度。
通过本节课的学习,学生可以了解到RIA网站的技术构成,重点掌握了AJAX的技术特点。同时,学生还学会了使用Selenium工具来获取ajax驱动网页的页面信息。这些知识和技能对于学生在实际工作中进行RIA网站数据爬取具有重要意义。
总而言之,本节课程全面介绍了RIA网站数据爬取的相关知识和技术。通过学习本节课,学生可以获得对网络数据采集的全面理解,提升自己在该领域的能力和水平。
AJAX
实
例
解
释
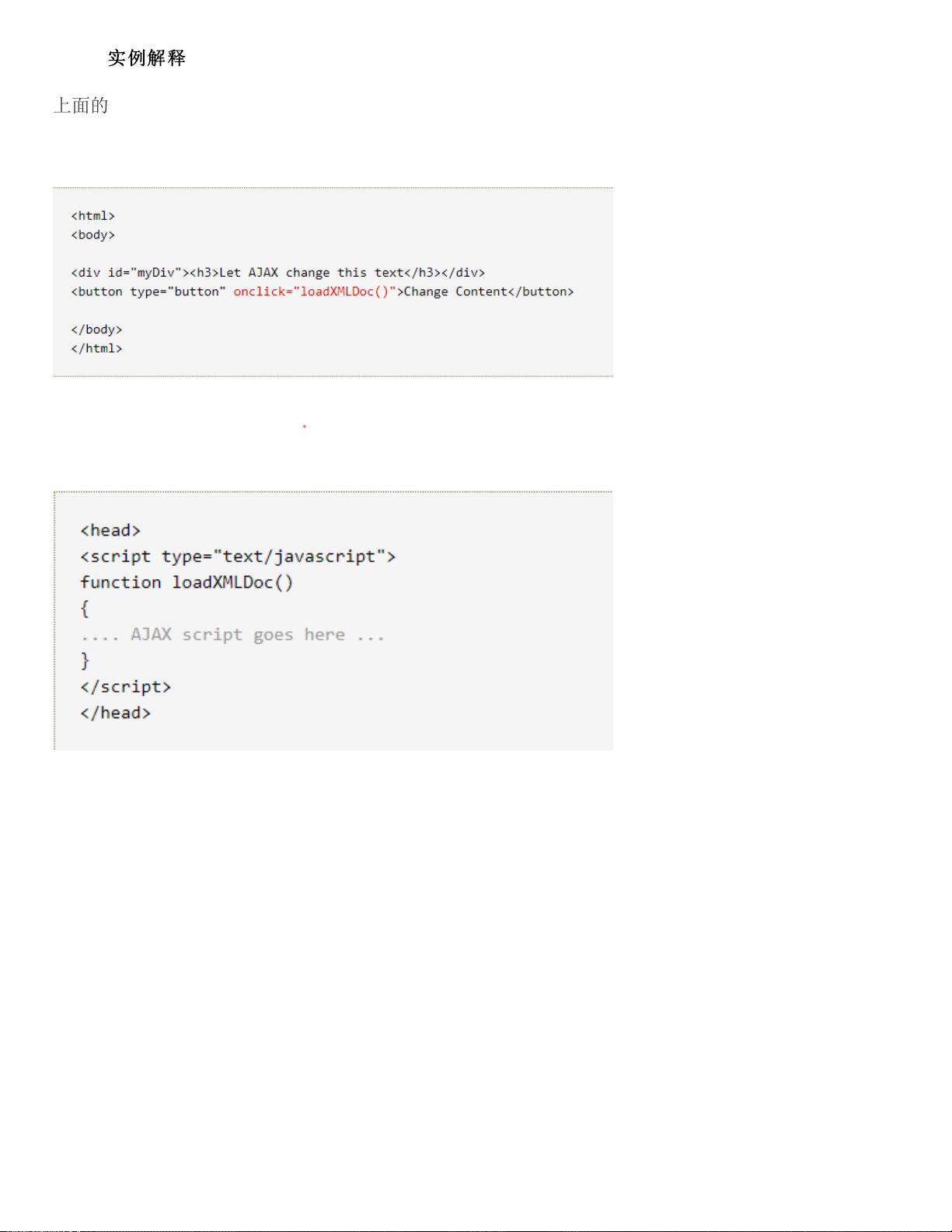
上面的 AJAX 应用程序包含一个 div 和一个按钮。
div 部分用于显示来自服务器的信息。当按钮被点击时,它负责调用名为 loadXMLDoc() 的函数:
接下来,在页面的 head 部分添加一个 script 标签。该标签中包含了这个 loadXMLDoc() 函数:
中间的代码如下:

剩余38页未读,继续阅读
2023-05-31 上传
2023-10-22 上传
2023-06-10 上传
2023-06-11 上传
2023-05-24 上传
2023-05-31 上传
2023-06-03 上传
2023-05-26 上传

我就是月下
- 粉丝: 30
- 资源: 336
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
