Hadoop在大数据处理中的应用
需积分: 0 77 浏览量
更新于2024-07-17
收藏 5.85MB PDF 举报
《大数据处理与Hadoop》是一篇深入探讨在大数据时代利用Hadoop进行数据处理的重要论文,由T. Revathi、K. Muneeswaran和M. Blessa Binolin Pepsi三位来自印度Mepco Schlenk工程学院的作者共同撰写。该文章收录于"Advances in Data Mining and Database Management" (ADMDM)系列书籍,该系列由美国的IGI Global出版,地址位于701 E. Chocolate Avenue, Hershey, PA, USA 17033。联系信息包括电话717-533-8845,传真717-533-8661,以及电子邮箱cust@igi-global.com,访问网站http://www.igi-global.com以获取更多信息。
版权方面,本出版物受2019年IGI Global所有权利保护,未经书面许可,任何形式的复制、存储或分发,无论是电子还是机械,包括复印,都必须得到出版社的明确授权。文章中提到的产品或公司名称仅为识别用途,并不表示IGI Global对其商标或注册商标的所有权声明。
Hadoop是一个开源的分布式计算框架,最初由Apache软件基金会开发,专为大规模数据集提供容错处理能力。它主要由Hadoop Distributed File System (HDFS)和MapReduce编程模型组成。HDFS负责存储和管理大量数据,通过冗余副本和分布式架构提供高可用性和可靠性。MapReduce则是一种并行处理模型,将复杂的数据处理任务分解成一系列简单的Map和Reduce操作,使得即便在集群环境下,也能高效地执行海量数据处理。
在《大数据处理与Hadoop》一文中,作者可能探讨了以下几个关键知识点:
1. **Hadoop体系结构**:介绍Hadoop的组成部分,如YARN(Yet Another Resource Negotiator)作为资源调度器,以及Hive、Pig等数据处理工具的角色。
2. **数据存储与管理**:阐述HDFS如何通过块存储、数据复制和数据压缩技术优化大规模数据的存储和检索性能。
3. **MapReduce编程模型详解**:讨论如何编写MapReduce程序,包括Mapper、Reducer和Shuffle阶段的工作原理。
4. **大数据分析与处理案例**:可能提供了实际应用Hadoop处理社交媒体数据、日志分析或推荐系统等领域的案例研究。
5. **性能优化与故障恢复**:讨论如何通过优化Hadoop配置、调整工作负载和使用实时流处理技术提高处理效率,以及在面对节点故障时的容错机制。
6. **大数据安全与隐私保护**:可能涵盖了Hadoop的数据加密、访问控制和隐私策略等相关话题。
7. **未来趋势与挑战**:作者可能会展望Hadoop在云计算、AI和物联网时代的大数据处理潜力,以及面临的诸如数据治理、数据质量管理和实时处理等挑战。
这篇论文为读者提供了深入了解Hadoop在大数据处理中的核心技术和实践应用的宝贵资源,适合对大数据处理有兴趣的专业人士和研究人员参考。
5
Big Data Overview
the locations of friends and to receive offers from nearby stores and
restaurants.
• Image, audio data can be analyzed for applications such as facial
recognition systems in security systems.
• Microsoft Azure Marketplace, World Bank, Wikipedia etc. provides
data which is publicly available on the web. This data can be taken for
any analysis.
BIG DATA ANALYTICS
Stored data does not generate any business value which is of traditional
databases, data warehouses, and the new technologies for storing big data.
So, once the data is available, it is to be processed further using some data
analytics technologies.
Data analysis is the process of extracting some useful information out of
available data and hence making some conclusions. It uses statistical methods,
questioning, selecting or discarding some subsets, examining, comparing
and confirming, etc.
One step further to analysis is data analytics. Data analytics is the
process of building predictive models and discovering patterns from data.
The evolution of data analytics proceeded from Decision support systems
(DSS) to Business Intelligence (BI) and the data analytics. DSS was used
as a description for an application and an academic discipline. Over time,
decision support applications included online analytical processing (OLAP),
and dashboards which became popular. Then, Business Intelligence, broad
category for analyzing and processing the gathered data to help business
users to make better decisions. Data analytics combines BI and DSS along
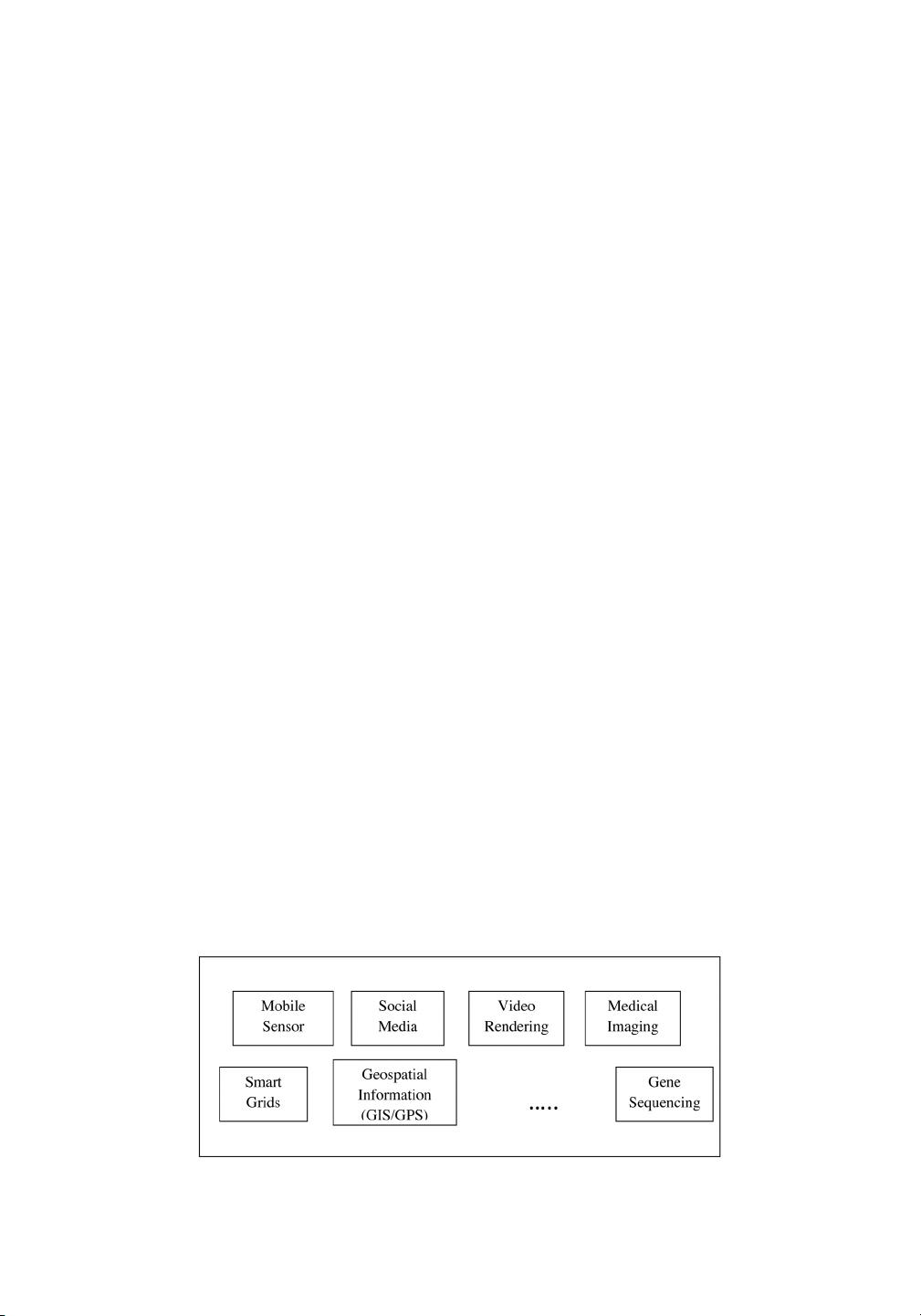
Figure 2. Sources of Data Deluge




剩余254页未读,继续阅读
2018-06-02 上传
2018-04-29 上传
2018-05-26 上传
2018-08-30 上传
2018-09-01 上传
2021-02-09 上传
2018-07-30 上传
141 浏览量
2021-05-26 上传

caofeng891102
- 粉丝: 172
- 资源: 1244
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
