深度学习面试必备:计算机视觉与神经网络解析
需积分: 7 198 浏览量
更新于2024-06-29
4
收藏 4.08MB DOC 举报
该资源是一份深度学习计算机视觉面试题目的集合,涵盖了多个互联网公司的常见问题,内容全面,旨在帮助面试者准备相关面试。题目涉及神经网络、激活函数、正则化技术、优化算法、模型调参、数据预处理、GPU的作用、不同类型的神经网络及其应用、损失函数等核心知识点。
1. **神经网络**
- **激活函数**:不同的激活函数(如Sigmoid、ReLU、Leaky ReLU、Tanh)各有优缺点,ReLU因其简单且在大部分情况下避免了梯度消失而被广泛使用。
- **梯度消失与梯度爆炸**:梯度消失可能导致网络学习缓慢,梯度爆炸可能导致权重更新过大。解决方案包括使用残差连接、归一化技术等。
- **正则化技术**:包括L1、L2正则化,Dropout,批量归一化(BN)等,用于防止过拟合。
- **批量归一化**:BN通过规范化每一层的输入,加速训练过程,减少内部协变量漂移。
- **权值共享**:在卷积神经网络中,权值共享降低了模型复杂度,减少了参数数量。
2. **优化算法**
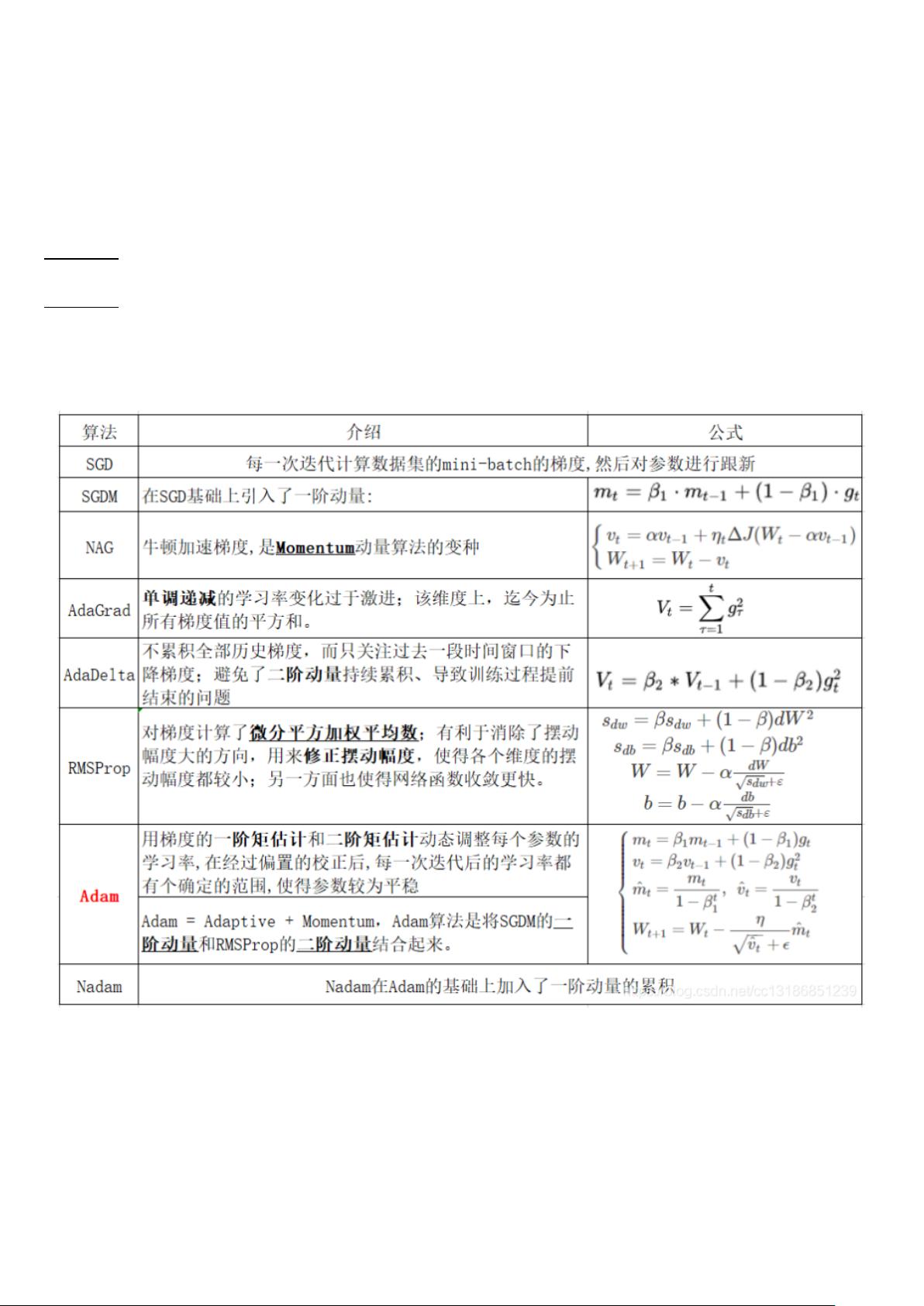
- **Adam**:自适应学习率优化算法,结合了动量和矩估计,适应性地调整每个参数的学习率。
- **Momentum**:通过累积过去的梯度来加速梯度下降,有助于跳出局部最小值。
- **选择优化器**:Adam通常适用于大多数情况,而SGD在某些情况下可能更佳,尤其是在需要快速收敛或资源有限时。
3. **模型训练与调参**
- **Batchsize和Epoch**:平衡这两者关系以达到最佳训练效果,大批次可能更快但可能导致过拟合,小批次可以提供更好的泛化能力。
- **学习率**:太大会导致权重更新剧烈,太小则训练慢。可以通过学习率衰减策略来调整。
- **L1正则化**:可以诱导稀疏解,但在深度学习中,L2正则化更常见,因为它确保权重不全变为0。
4. **数据预处理**
- **中心化/零均值和归一化**:这些预处理方法可以帮助数据具有更好的数值范围,加速收敛并提高模型性能。
- **权重初始化**:合理的初始化可以避免梯度消失或梯度爆炸,如Xavier或He初始化。
5. **硬件需求**
- **GPU**:由于深度学习计算涉及大量矩阵运算,GPU的并行处理能力使得训练深度学习模型更为高效。
6. **网络结构**
- **FNN、RNN和CNN**:FNN适用于结构化的数据,RNN处理序列数据,CNN擅长图像识别。
- **卷积核设计**:奇数大小的卷积核可以保证中心像素有对称的视野,对于图像特征提取更有效。
7. **损失函数**
- **Sigmoid和Softmax**:Sigmoid用于二分类,输出概率在0到1之间;Softmax用于多分类,输出类别的概率分布。
- **损失函数**:常见的有交叉熵损失、均方误差损失等,选择取决于任务类型。
8. **其他**
- **微调模型**:在预训练模型基础上修改部分层以适应特定任务,通常只调整最后一层或几层。
- **鞍点问题**:非凸优化中的难点,不是局部最优解也不是全局最优解,梯度优化方法可能会被困在此处。
这份面试题集不仅涵盖了深度学习的基础概念,还涉及到实践中的技巧和策略,是准备深度学习计算机视觉面试的宝贵资料。
第 6 页
权重衰减; 丢弃法;
批量归一化; 数据增强
早停法
1.6 批量归一化(BN) 如何实现?作用?
实现过程: 计算训练阶段 mini_batch 数量激活函数前结果的均值和方差,然后对其进行归一化,最后
对其进行缩放和平移。
作用: 1.可以使用更高的学习率进行优化;
2.移除或使用较低的 dropout;
3.降低 L2 权重衰减系数;
4.调整了数据的分布,不考虑激活函数,它让每一层的输出归一化到了均值为 0 方差为 1 的分布,这保
证了梯度的有效性,可以解决反向传播过程中的梯度问题。
1.7 神经网络中权值共享的理解?
权值共享这个词是由 LeNet5 模型提出来的。以 CNN 为例,在对一张图偏进行卷积的过程中,使用的是
同一个卷积核的参数。
比如一个 3×3×1 的卷积核,这个卷积核内 9 个的参数被整张图共享,而不会因为图像内位置的不同而
改变卷积核内的权系数。
通俗说:就是用一个卷积核不改变其内权系数的情况下卷积处理整张图片。
1.8 对 fine-tuning(微调模型)的理解?为什么要修改最后几层神经网络权值?
使用预训练模型的好处:在于利用训练好的 SOTA 模型权重去做特征提取,可以节省我们训练模型和调
参的时间。
理由:
1.CNN 中更靠近底部的层(定义模型时先添加到模型中的层)编码的是更加通用的可复用特征,而更靠
近顶部的层(最后添加到模型中的层)编码的是更专业化的特征。微调这些更专业化的特征更加有用,
它更代表了新数据集上的有用特征。
2.训练的参数越多,过拟合的风险越大。很多 SOTA 模型拥有超过千万的参数,在一个不大的数据集上
训练这么多参数是有过拟合风险的,除非你的数据集像 Imagenet 那样大。
1.9 什么是 Dropout?为什么有用?它是如何工作的?
背景:如果模型的参数太多,数据量又太小,则容易产生过拟合。为了解决过拟合,就同时训练多个网
络。然后多个网络取均值。费时!
介绍:Dropout 可以防止过拟合,在前向传播的时候,让某个神经元的激活值以一定的概率 P 停止工作,
这样可以使模型的泛化性更强。
Dropout 效果跟 bagging 效果类似(bagging 是减少方差 variance,而 boosting 是减少偏差 bias)。
加入 dropout 会使神经网络训练时间长,模型预测时不需要 dropout,记得关掉。
具体流程:
i.随机删除(临时)网络中一定的隐藏神经元,输入输出保持不变,
ii.让输入通过修改后的网络。然后把得到的损失同时修改后的网络进行反向传播。在未删除的神经元上
面进行参数更新
iii.重复该过程(恢复之前删除掉的神经元,以一定概率删除其他神经元。前向传播、反向传播更新参数)
1.10 如何选择 dropout 的概率?
input 的 dropout 概率推荐是 0.8, hidden layer 推荐是 0.5
为什么 dropout 可以解决过拟合?
1.取平均的作用:
Dropout 产生了许多子结构之后的操作,父神经网络有 N 个节点,加入 Dropout 之后可以看做在权值不
剩余31页未读,继续阅读
2321 浏览量
238 浏览量
1102 浏览量
428 浏览量
272 浏览量
134 浏览量
165 浏览量
107 浏览量
2024-10-17 上传

Carry陈
- 粉丝: 779
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网狐工具:核心DLL和程序文件解析
- PortfolioCVphp - 展示JavaScript技能的个人作品集
- 手机归属地查询网站完整项目:HTML+PHP源码及数据集
- 昆仑通态MCGS通用版S7400父设备驱动包下载
- 手机QQ登录工具的压缩包内容解析
- Git基础学习仓库:掌握版本控制要点
- 3322动态域名更新器使用教程与下载
- iOS源码开发:温度转换应用简易教程
- 定制化用户登录页面模板设计指南
- SMAC电机在包装生产线应用的技术案例分析
- Silverlight 5实现COM组件调用无需OOB技术
- C#实现多功能画图板:画直线、矩形、圆等
- 深入探讨C#语言在WPF项目开发中的应用
- 新版2012109通用权限系统源码发布:多角色用户支持
- 计算机科学与工程系网站开发技术源码合集
- Java实现简易导出Excel工具的开发教程
