DIX平台(高校版)PySpark特征提取与模型训练教程
需积分: 0 58 浏览量
更新于2024-08-04
收藏 695KB DOCX 举报
"这篇教程是关于dix平台(高校版)的使用,主要涉及如何使用PySpark组件进行特征提取和模型训练。作者分享了在不熟悉Spark的情况下如何配置和运行任务,以及处理训练集和测试集的方法。"
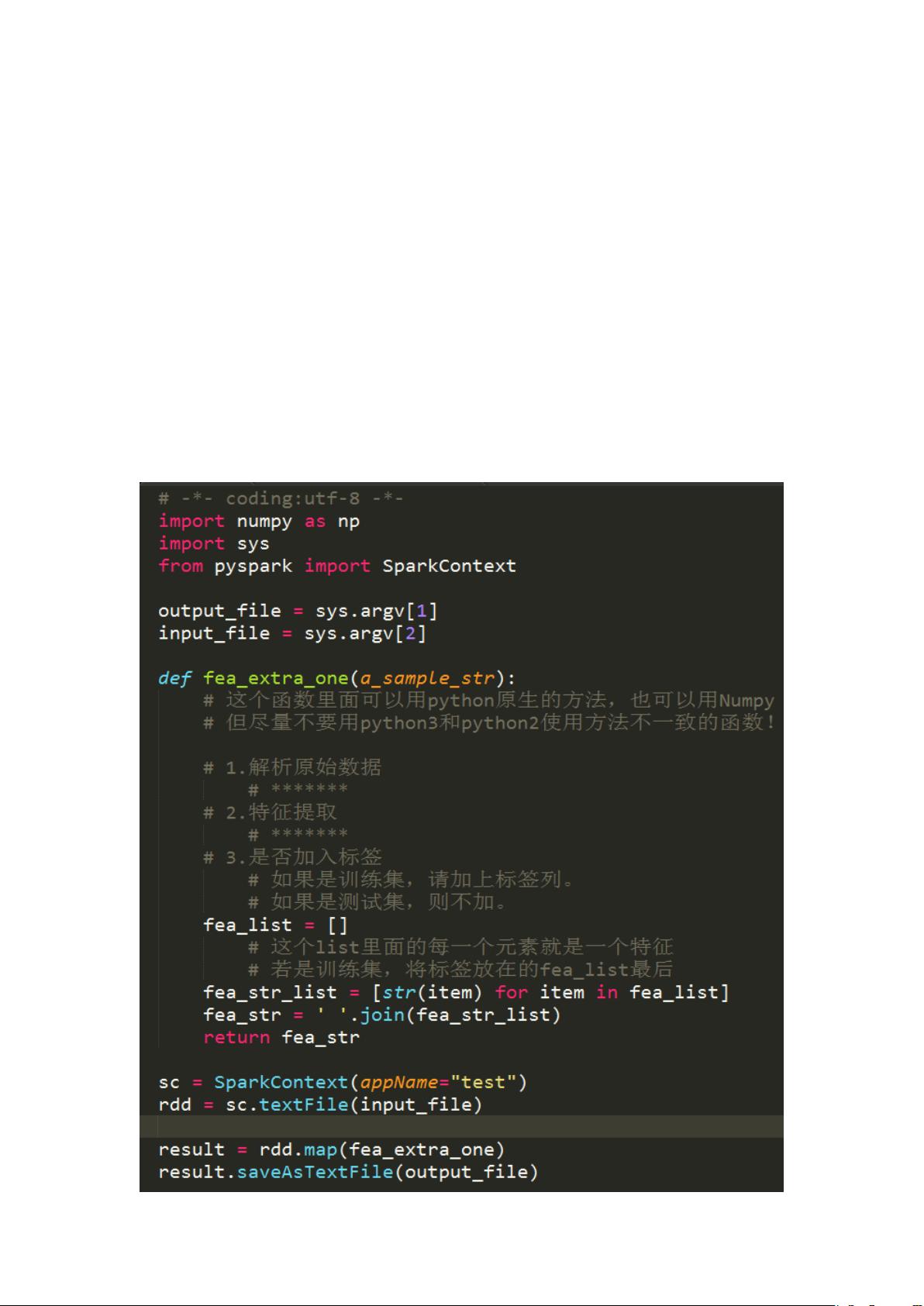
在这个dix平台(高校版)简易教程中,作者介绍了如何在平台上进行数据预处理和模型训练。教程首先提到了特征提取的过程,使用Python的pyspark库结合RandomForest算法。特征提取的代码框架(fea_extra_*.py)被设计成可同时适用于训练集和测试集,其中训练集会额外包含一个标签字段。在处理数据时,确保特征之间使用空格分隔,这是模型输入的要求。不正确的数据格式可能会导致模型运行出错。
接下来,教程演示了在dix平台上运行任务的步骤。首先,需要将"初赛训练集(3k)"从"输入"目录拖入画布,然后将"PySpark"组件从"组件"目录拖入,形成工作流程。配置PySpark组件时,要注意指定训练集特征保存的文件路径,保持`${output_prefix}/`作为前缀。完成配置后,运行组件,如果显示"成功",则特征提取完成。
对于测试集,同样需要修改脚本和输出路径,确保数据源和资源参数正确。平台允许自定义输出路径,但原始数据路径必须严格遵循平台给出的路径。
模型的训练与预测阶段,用户需要按照教程所示的步骤操作PySpark组件。成功运行后,预测结果会被保存在预设的"预测结果路径"中。这里,作者使用了随机森林模型,因此提供了解析预测结果文件的示例代码。
最后,根据模型的输出格式,用户需要编写脚本来处理预测结果,以便按照官方要求提交成绩。在这个例子中,由于使用了全部特征,结果文件只包含"0.0"和"1.0"这样的分类标签。
通过这个教程,初学者能够了解如何在dix平台上使用PySpark进行大数据处理,包括特征提取、模型训练和结果提交的关键步骤。这对于不熟悉Spark的团队来说,是一个很好的实践指南。
dix 平台(高校版)简易教程
作者:自由在高处
时间:2017.7.27
写前语:由于我们队伍的队员在之前并不熟悉 spark,这两天也是瞎弄,侥幸跑通了,若教
程中有错误的地方,还请各位看官谅解。我们使用的是 pyspark+RandomForest。
一、特征提取
1. 代码框架(fea_extra_*.py)
下载后可阅读完整内容,剩余6页未读,立即下载
2017-08-16 上传
2020-09-16 上传
2022-12-03 上传
2022-12-03 上传
2022-12-03 上传
2022-09-14 上传
2021-06-04 上传
2020-11-17 上传
2021-05-24 上传

笨爪
- 粉丝: 1009
- 资源: 333
 我的内容管理
展开
我的内容管理
展开







最新资源
- xdPixelEngine-2
- filter-records:原型制作-DOM中的记录过滤和排序
- 管理系统系列--中医处方管理系统.zip
- LED广告屏控制与显示解决方案(原理图、程序及APK等)-电路方案
- scenic-route:多伦多开放数据绿色路线图应用
- spring-google-openidconnect
- 漏斗面板
- bing-wallpaper
- friendsroom
- 基于M058S的8x8x8 LED 光立方设计(原理图、PCB源文件、程序源码等)-电路方案
- 管理系统系列--综合管理系统.zip
- wisit-slackbot:Slackbot获取有关wisit的信息
- 电子功用-场效应管电容-电压特性测试电路的串联电阻测定方法
- Java-Google-Finance-Api:用于 Google Finance 的 Java API - 使用 Quandl 构建
- test
- 管理系统系列--整合 vue,element,echarts,video,bootstrap(AdminLTE),a.zip
