K-Means聚类与辨别分析:解决餐饮业问题的关键
版权申诉
13 浏览量
更新于2024-06-28
收藏 1.48MB PDF 举报
第9章主要探讨了在餐饮行业中如何利用聚类分析技术来解决实际问题,特别是针对客户价值评估和菜品分析两个方面。聚类分析是一种无监督学习方法,旨在根据数据内在的相似性而非预设的类别对样本进行分组,其核心原则是最大化组间差异和最小化组内差异。
首先,聚类分析可以帮助餐饮企业通过客户消费行为数据,对客户群体进行细分,从而发现有价值的客户群和需要重点关注的客户。例如,通过K-Means算法(一种常用的聚类算法,它以预定的类别数量K为基础,将数据分割成紧密且均衡的簇),企业可以识别出忠诚度高、消费频次多的客户群,以及潜在的高价值客户,以便制定更有针对性的营销策略。
此外,K-Means算法也适用于菜品分析,通过对菜品销售数据的聚类,企业能够分辨出哪些菜品热销且利润丰厚,哪些则可能滞销且毛利较低。这有助于优化菜单设计,提升盈利能力。K-Means算法虽然对孤立点较为敏感,但其简单易用的特点使其在大规模数据处理中仍具有优势。
然而,对于大数据集,系统聚类(一种层次聚类方法)虽然能够提供深入的层次结构,但其计算复杂度较高,适合于小型数据集。对于大型数据集,可能需要考虑更高效的算法,如DBSCAN(基于高密度连接区域的聚类)或DENCLUE(基于密度分布函数的聚类),它们能够在保持效率的同时处理大规模数据。
第9章的RaPID控制miner-K-Means聚类分析方法是餐饮企业进行数据驱动决策的强大工具,它不仅帮助企业管理客户和菜品,还能提高运营效率,降低运营成本。通过选择合适的聚类算法,企业可以在竞争激烈的市场环境中更好地定位自己,实现持续的业务增长。
.
本与簇之间的距离可以用样本到簇中心的距离
d
(
e
i
,
x
)
;簇与簇之间的距离可以用簇中心的
距离
d
(
e
i
,
e
j
)
。
用
p
个属性来表示
n
个样本的数据矩阵如下:
x
11
x
n1
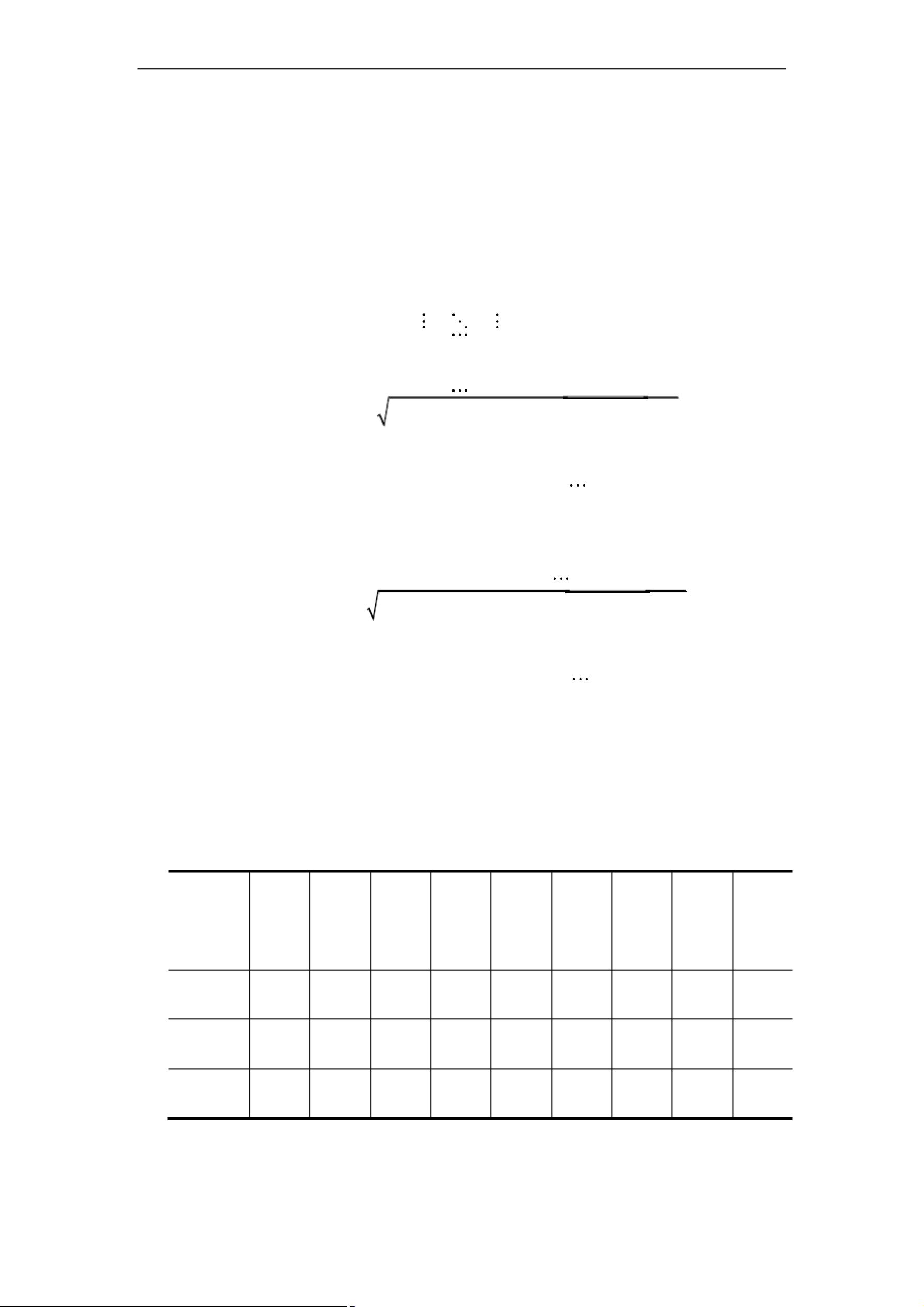
欧几里得距离
x
1 p
x
n p
d (i, j) (x
i1
x
j1
)
2
+(x
i2
x
j 2
)
2
+
曼哈顿距离
+(x
ip
x
jp
)
2
(9-1)
闵可夫斯基距离
d (i, j) |x
i1
x
j1
|+ |x
i 2
x
j 2
|+ +|x
ip
x
jp
|
(9-2)
d (i, j)
q
|(x
i1
x
j1
|)
q
+ (|x
i2
x
j 2
|)
q
+ +(|x
ip
x
jp
|)
q
(9-3)
q
为正整数,
q=1
时即为曼哈顿距离;
q=2
时即为欧几里得距离。
(2) 文档数据
对于文档数据使用余弦相似性度量,先将文档数据整理成文档—词矩阵格式,如表
9-3。
表 9-3 文档—词矩阵
musi
lost win team score
c
文档一
文档二
文档三
14
1
9
2
13
6
8
3
7
0
4
7
8
1
3
happ
sad
y
7
16
14
10
4
8
…
…
…
…
coac
h
6
7
5
剩余19页未读,继续阅读
600 浏览量
203 浏览量
203 浏览量
124 浏览量
1059 浏览量
1059 浏览量

xxpr_ybgg
- 粉丝: 6805
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- swgoh-tw
- pictips:Instagram克隆与生活小贴士
- Bookers2-ver4.0
- 闪烁文本按钮、发光呼吸字体
- HTML和CSS
- CSCE4110:算法
- 超简单图示:建议的 FBMC 调制器的图示-matlab开发
- 基于51单片机智能电子锁多功能菜单栏
- MPMB-v13-content-catchup
- 海威视康扫码读取软件源码C++BuilderSocket通讯.zip
- FinalShell(远程连接工具) V3.0.10 官方版.rar
- portfolio
- (MFC)手机通讯录 (源码和文档)
- mimic_mf_analysis:Python应用程序可运行MIMIC表型的相互信息分析
- sgauss(t,Tfwhm,E,C,m):啁啾超高斯脉冲-matlab开发
- GuitarTabs:绘制吉他谱的工具
