RapidMiner实战:K-Means聚类解析与餐饮业应用
需积分: 50 113 浏览量
更新于2024-07-18
1
收藏 362KB DOC 举报
在《RapidMiner数据分析与挖掘实战》的第9章中,主要探讨了K-Means聚类和辨别分析在实际业务中的应用,特别是针对餐饮企业的场景。K-Means聚类是一种非监督学习方法,用于在没有预先定义类别的情况下,根据样本之间的相似性将其自动分组。其目标是将数据分为K个簇,每个簇内的样本尽可能相似,而不同簇之间的样本尽可能不同,以此实现数据的自然分层。
首先,聚类分析在餐饮业中可以帮助企业评估客户价值和细分市场。例如,通过对客户的消费行为数据进行K-Means聚类,企业可以识别出高价值客户群体和需要重点关注的客户群体,从而制定更精准的营销策略和客户服务。这有助于提升客户满意度和利润。
其次,K-Means聚类可以用于菜品分析,帮助企业识别出畅销且毛利高的菜品以及滞销且毛利低的菜品,帮助管理者优化菜单组合,提高经营效率。比如,算法可能会发现某一类型的菜品经常被一组特定的客户群体购买,从而指导菜品定价、促销活动和库存管理。
在技术层面,K-Means算法是聚类分析中最常用的方法之一,它通过计算样本之间的欧氏距离,将数据点分配到最近的质心(即簇中心),然后更新质心,直到簇不再变化或达到预设的迭代次数。对于容易出现孤立点的问题,K-Medoids算法和K-中心点算法提供了改进,前者使用簇中对象的实际点作为簇中心,后者则选择距离平均值最近的点。
此外,书中还提到了其他几种聚类方法,如层次分析法(如BIRCH、CURE和CHAMELEON)、基于密度的方法(如DBSCAN、DENCLUE和OPTICS)、基于网格的方法(如STING、CLIOUE和WAVE-CLUSTER)以及基于模型的方法,如统计学和神经网络方法。这些方法各有优势,适用于不同的数据类型和规模,企业可以根据具体需求选择合适的聚类算法。
值得注意的是,虽然K-Means等算法在大数据处理上表现良好,但对于大规模数据,层次分析方法可能因为其复杂性而在效率上受限。因此,选择算法时应考虑数据量和性能要求。
第9章详细介绍了K-Means聚类及其在餐饮行业的实际应用,为企业提供了一种有效的方法来理解和利用数据,以优化决策和提升运营效率。
《RapidMiner 数据分析与挖掘实战》第 9 章
文档三
9 6 7 7 3 14 8 … 5
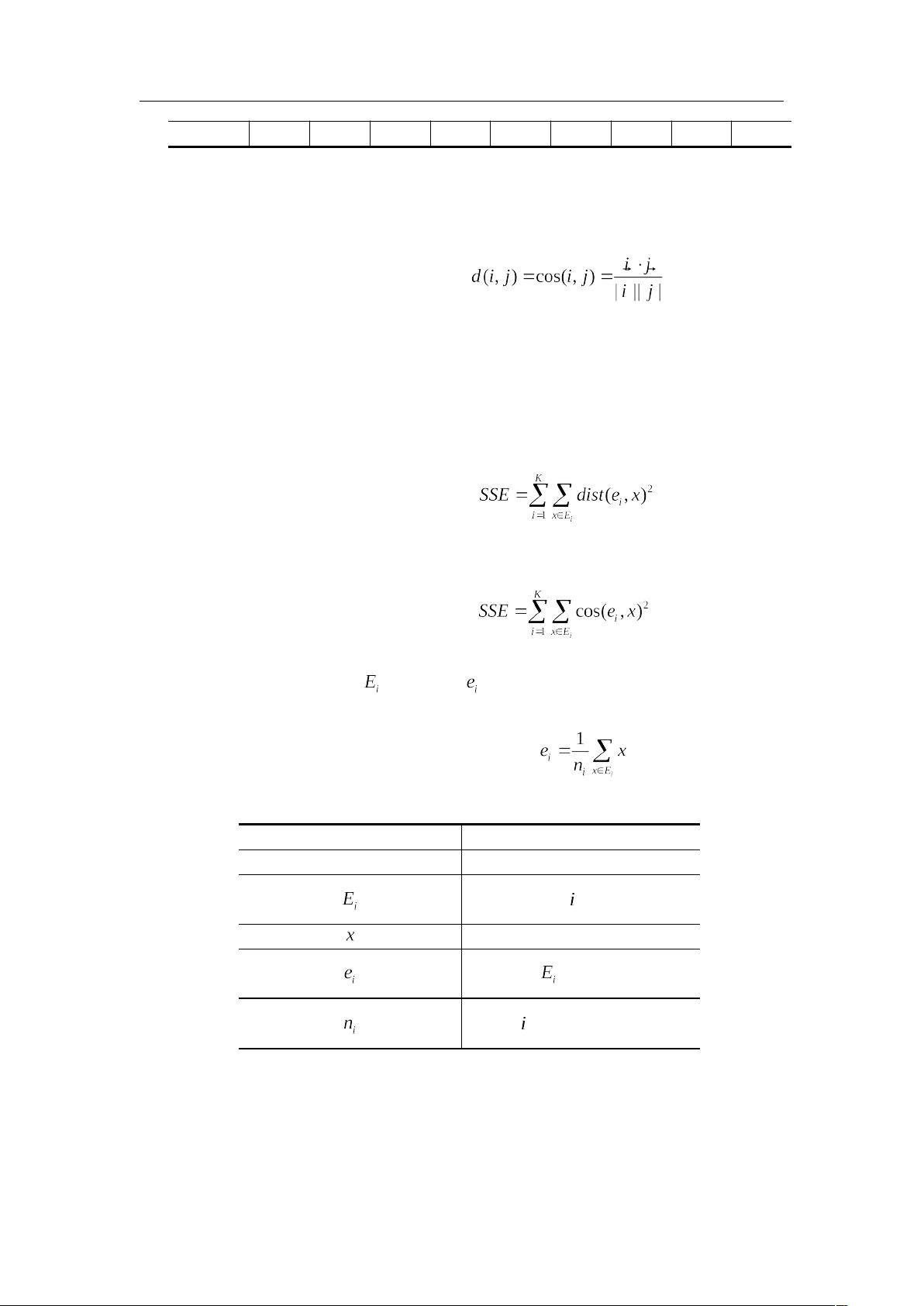
两个文档之间的相似度的计算公式为:
(9-4)
3. 目标函数
使用误差平方和 SSE 作为度量聚类质量的目标函数,对于两种不同的聚类结果,选择
误差平方和较小的分类结果。
连续属性的 SSE 计算公式为:
(9-5)
文档数据的 SSE 计算公式为:
(9-6)
簇 的聚类中心 计算公式为:
(9-7)
表 9-4 符号表
符号 含义
K
聚类簇的个数
第 个簇
对象(样本)
簇 的聚类中心
第 个簇中样本的个数
下面结合具体案例来实现本节开始提出问题。
部分餐饮客户的消费行为特征数据如表 9-5。根据这些数据将客户分类成不同客户群,
并评价这些客户群的价值。
表 9-5消费行为特征数据
198
剩余15页未读,继续阅读
2018-06-30 上传
2021-08-07 上传
2022-11-26 上传
2022-11-26 上传
点击了解资源详情
2022-04-26 上传
点击了解资源详情

海晏
- 粉丝: 5
- 资源: 36
 我的内容管理
展开
我的内容管理
展开







最新资源
- StarModAPI: StarMade 模组开发的Java API工具包
- PHP疫情上报管理系统开发与数据库实现详解
- 中秋节特献:明月祝福Flash动画素材
- Java GUI界面RPi-kee_Pilot:RPi-kee专用控制工具
- 电脑端APK信息提取工具APK Messenger功能介绍
- 探索矩阵连乘算法在C++中的应用
- Airflow教程:入门到工作流程创建
- MIP在Matlab中实现黑白图像处理的开源解决方案
- 图像切割感知分组框架:Matlab中的PG-framework实现
- 计算机科学中的经典算法与应用场景解析
- MiniZinc 编译器:高效解决离散优化问题
- MATLAB工具用于测量静态接触角的开源代码解析
- Python网络服务器项目合作指南
- 使用Matlab实现基础水族馆鱼类跟踪的代码解析
- vagga:基于Rust的用户空间容器化开发工具
- PPAP: 多语言支持的PHP邮政地址解析器项目
