CentOS6.5上Hadoop2.2.0与Spark伪分布式的详细部署教程
需积分: 9 129 浏览量
更新于2024-07-20
收藏 771KB DOCX 举报
"这篇文档详细介绍了在Linux环境下部署Hadoop 2.2.0的步骤,包括从安装Linux操作系统开始,一直到配置Hadoop、Spark、Zookeeper和Kafka等组件。主要内容涵盖安装Linux(CentOS 6.5)、配置SSH免登陆、安装基本工具、单机安装Hadoop、伪分布式部署Spark、搭建Zookeeper集群以及Kafka的安装与验证。文档还特别提到了在安装和配置过程中可能遇到的问题及解决方法,如网络配置、磁盘分区、系统分区和VIM命令设置等。"
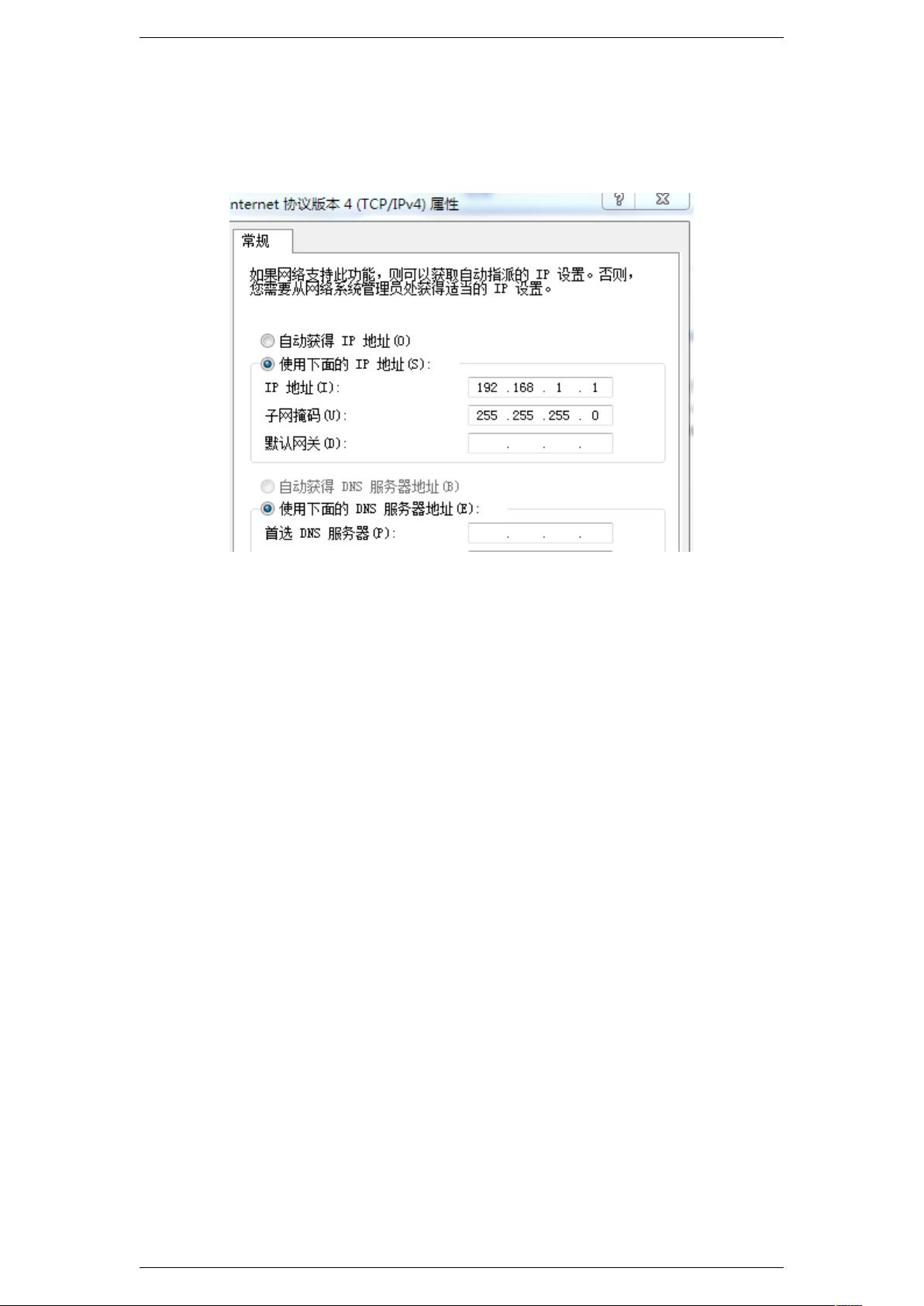
在部署Hadoop之前,首先要确保有合适的Linux环境。这里选择了CentOS 6.5,通过VMware 11进行虚拟化。安装时需注意磁盘大小的设定,通常默认的20GB用于系统分区。选择最小安装桌面版以节省资源。安装完成后,配置VIM命令以方便文本编辑,并设置网络连接,如仅主机模式、桥接模式或NAT模式。对于网络问题,如"DevicenotmanagedbyNetworkManagerorunavailable"的错误,可以通过还原网络设置和重新配置解决。
安装基本工具包括SSH免登陆配置,这便于在不同节点间无密码登录,以及SUDO配置,以提升管理权限。接下来是单机安装Hadoop,包括hdfs和yarn的配置,涉及主机名和防火墙设置。了解并掌握基本的Hadoop shell命令和简单的Java实例对于操作和理解Hadoop至关重要。
进一步,文档讲解了伪分布式部署Spark,包括下载、解压、安装Scala以及配置启动参数。通过启动和验证来确保Spark正确配置。Zookeeper集群的搭建包括下载、解压、参数配置(包括多个配置项)以及启动验证,它是Hadoop生态中的关键组件,用于协调分布式服务。
最后,文档涉及Kafka的安装,包括下载、安装、配置参数、复制到其他环境、启动验证以及基本命令的使用。Kafka是一个高吞吐量的分布式消息系统,常用于大数据实时处理。
这个文档提供了一个全面的Hadoop部署流程,适合初学者和有一定经验的IT从业者参考,通过实践这些步骤,可以深入理解Hadoop及其相关组件的安装和配置过程。

剩余25页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2014-03-10 上传
2020-12-30 上传
2013-11-29 上传
2021-03-24 上传
2015-06-16 上传
2013-11-26 上传

nie_hw
- 粉丝: 3
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C# 开发经验 40种窗体常用代码
- 数据库考纲详解(绝对正确)
- 基于敏捷软件开发方法的基金管理信息系统开发
- 中国移动笔试试题及答案
- ARM嵌入式入门级教程
- 2009年研究生入学考试计算机统考大纲-完整版.pdf
- c#北大青鸟经典教程
- (2009 Wiley)LTE for UMTS:OFDMA and SC-FDMA Based Radio Access
- Proteus元件中英文名对照
- XML开发实务.pdf
- FFT算法的一种FPGA实现
- linux学习资料.pdf
- 有关TCP、Ip的嵌入式知识
- 达内面试笔记,分享(C++、Java).pdf
- DIV+CSS布局大全
- Linux的进程管理.doc
