JDK1.7 HashMap循环链表问题解析与1.8优化
"本文主要探讨了Java开发工具包(JDK)1.7版本中HashMap的一个严重问题,即循环链表的产生,以及它如何影响性能。在JDK 1.7中,HashMap的实现是基于数组和链表的,这可能导致在多线程环境下出现循环链表,从而在get操作时造成死循环。文章还提到了JDK 1.8对此问题的优化措施,包括使用尾插法避免循环链表的生成以及在链表过长时转换为红黑树来提升查询效率。"
在JDK 1.7的HashMap实现中,当多个线程同时执行put操作并且触发数组扩容(resize)时,有可能产生循环链表。这是因为resize过程中使用了头插法,这种方法在并发情况下容易引发问题。扩容时,HashMap会创建一个新数组,并通过`transfer`函数将旧数组的元素移动到新数组中。在这个过程中,每个元素会被插入到新数组的对应位置,但使用头插法会导致元素顺序发生改变,如果多个线程在不同阶段插入同一个链表节点,就可能形成循环。
`transfer`函数的逻辑如下:
1. 遍历旧数组的每个元素,如果元素不为空,则开始处理。
2. 保存当前元素的下一个元素,然后将当前元素插入到新数组的相应位置,设置其next指针指向新位置。
3. 更新当前元素为保存的下一个元素,直到遍历完链表。
这种操作在无并发环境下是安全的,但在多线程环境中,如果两个线程同时对同一链表节点进行迁移,就可能导致节点顺序错乱,从而形成循环链表。
为了解决这个问题,JDK 1.8对HashMap进行了重大改进。首先,它改用了尾插法,这样即使在并发环境下,也不会轻易产生循环链表。其次,当链表长度达到一定阈值(8个元素)时,HashMap会将链表转换为红黑树,以降低查找、插入和删除的时间复杂度,从而显著提高整体性能。
JDK 1.7的HashMap存在的循环链表问题在1.8版本中得到了优化,这体现了Java在并发安全和性能方面的持续改进。对于开发者来说,理解这些底层机制有助于更好地理解和使用HashMap,特别是在设计高并发场景下的数据结构时。
jdk1.7 HashMap中的致命错误:循环链表中的致命错误:循环链表
jdk1.7 HashMap中的中的”致命错误致命错误”:循环链表:循环链表
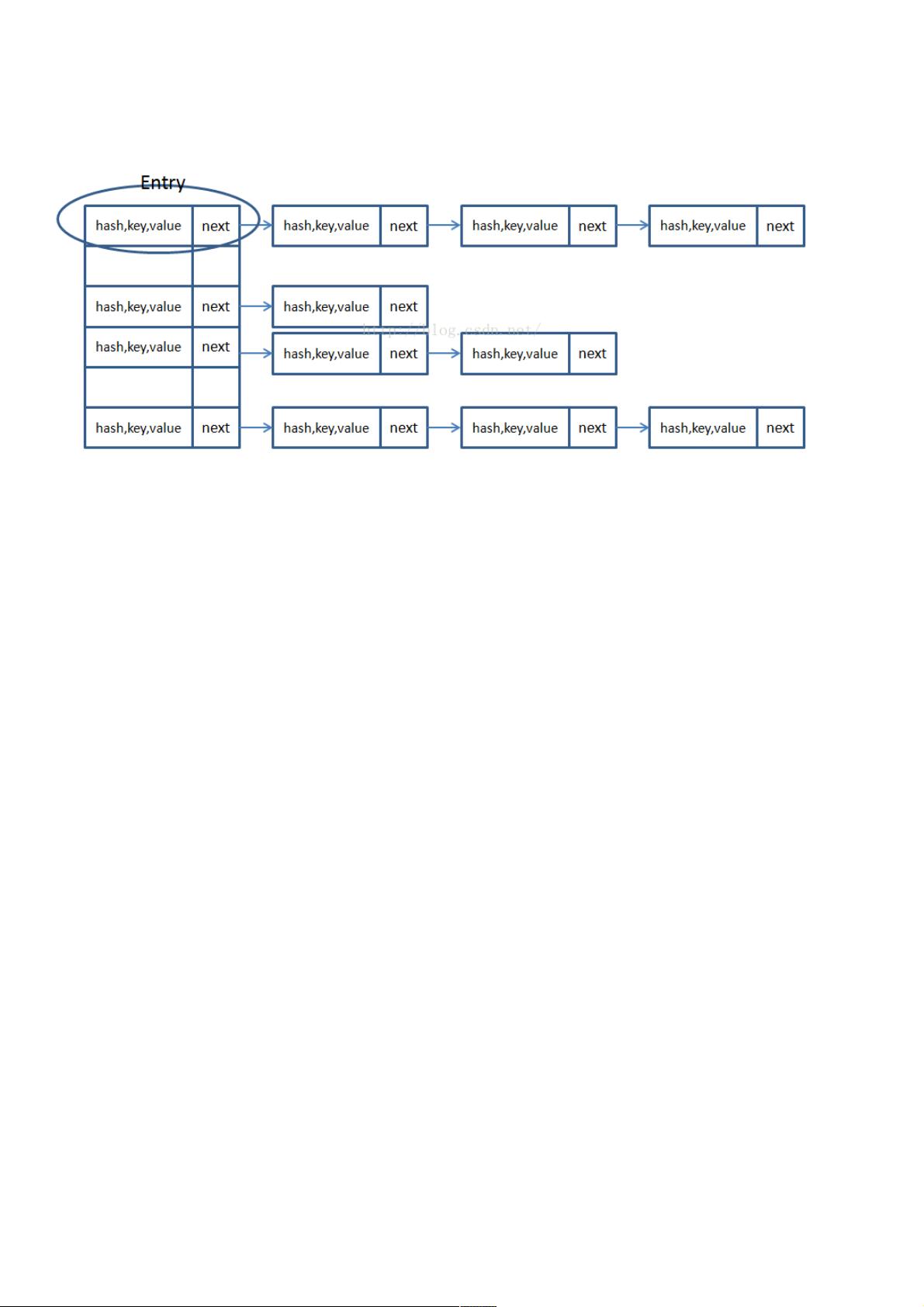
jdk1.7 HashMap结构图结构图
jdk1.7是数组是数组+链表的结构链表的结构
jdk1.7版本中主要存在两个问题版本中主要存在两个问题
头插法会造成循环链表的情况
链表过长,会导致查询效率下降
jdk1.8版本针对版本针对jdk1.8进行优化进行优化
使用尾插法,消除出现循环链表的情况
链表过长后,转化为红黑树,提高查询效率
具体可以参考我的另一篇博客你真的懂大厂面试题:HashMap吗?
循环链表的产生循环链表的产生
多线程同时put时,如果同时调用了resize操作,可能会导致循环链表产生,进而使得后面get的时候,会死循环。下面详细阐述循环链表如
何形成的。
resize函数函数
数组扩容函数,主要的功能就是创建扩容后的新数组,并且将调用transfer函数将旧数组中的元素迁移到新的数组
void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
transfer函数函数
transfer逻辑其实也简单,遍历旧数组,将旧数组元素通过头插法头插法的方式,迁移到新数组的对应位置问题出就出在头插法头插法。
void transfer(Entry[] newTable)
{
//src旧数组
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry e = src[j];
if (e != null) {
src[j] = null;
do {
Entry next = e.next;
下载后可阅读完整内容,剩余5页未读,立即下载
相关推荐





weixin_38719578
- 粉丝: 6
- 资源: 928
 我的内容管理
展开
我的内容管理
展开







