机器学习算法详解与常用模型
需积分: 23 110 浏览量
更新于2024-07-18
收藏 209.26MB PDF 举报
"这是一份由Jim Liang创建的关于机器学习算法的个人学习笔记,主要涵盖了一些知名的机器学习算法,如最近邻算法、支持向量机、线性回归、逻辑回归、神经网络、梯度下降、朴素贝叶斯、K-均值聚类、主成分分析、决策树、AdaBoost和随机森林。此外,文档还提到了机器学习的基本概念,包括整体概述、业务理解、数据理解、数据准备、建模、模型评估和模型部署。"
在机器学习领域,算法是构建智能系统的基石。以下是对这些算法的详细说明:
1. **最近邻算法 (Nearest Neighbor)**:这是一种懒惰学习方法,不进行显式训练,而是在预测时寻找与新样本最相似的训练样本,并根据其类别进行预测。
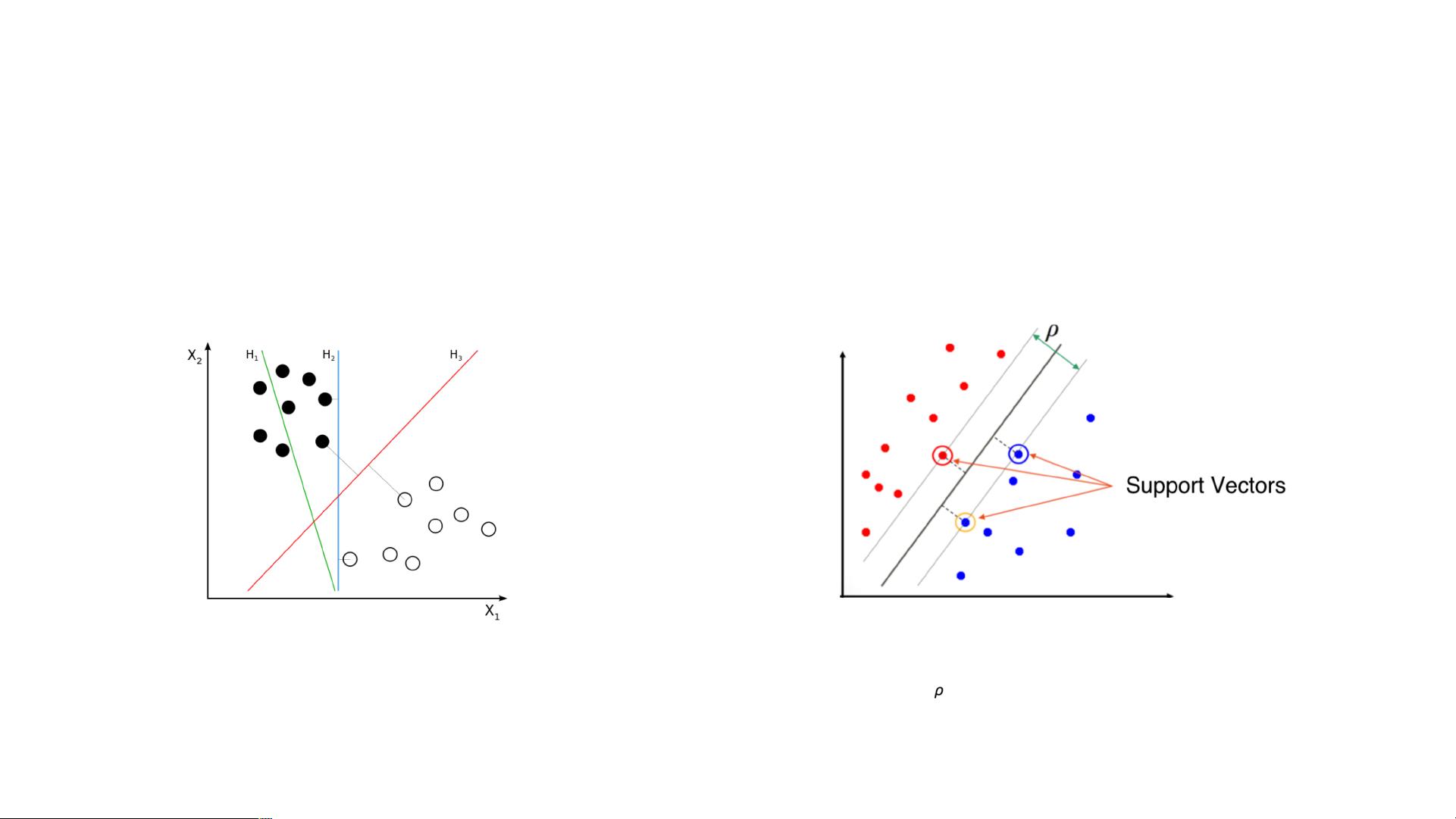
2. **支持向量机 (Support Vector Machines, SVM)**:SVM是一种二分类模型,通过找到一个最优超平面最大化类别间隔来划分数据。在高维空间中,它能够处理非线性数据,并且可以使用核函数进行映射。
3. **线性回归 (Linear Regression)**:线性回归用于预测连续数值型的目标变量。它假设因变量与自变量之间存在线性关系,并通过最小化残差平方和找到最佳拟合线。
4. **逻辑回归 (Logistic Regression)**:尽管名字中含有“回归”,但实际上是分类算法。它通过sigmoid函数将线性回归的结果转换为0-1之间的概率,常用于二分类问题。
5. **神经网络 (Neural Networks)**:神经网络是受生物神经元结构启发的复杂模型,通过多层节点(称为神经元)和权重进行非线性建模,适用于解决分类和回归问题,尤其在深度学习领域表现出色。
6. **梯度下降 (Gradient Descent)**:这是一种优化算法,用于寻找损失函数最小值。在机器学习中,常用于调整模型参数以最小化误差。
7. **朴素贝叶斯 (Naïve Bayes)**:基于贝叶斯定理和特征条件独立假设的分类器,简单且在某些情况下效果良好,如文本分类。
8. **K-均值聚类 (K-means Clustering)**:这是一种无监督学习算法,通过迭代寻找数据的最佳k个聚类中心,将数据点分配到最近的聚类。
9. **主成分分析 (Principal Component Analysis, PCA)**:降维技术,通过找到数据方差最大的方向(主成分),减少数据的维度,同时保留大部分信息。
10. **决策树 (Decision Trees)**:通过树状结构进行分类或回归,每个内部节点表示一个特征测试,每个分支代表一个测试输出,而叶节点则代表类别或数值。
11. **AdaBoost**:一种集成学习算法,通过迭代训练弱分类器并调整它们的权重来提升整体性能。
12. **随机森林 (Random Forest)**:由多个决策树组成的集成学习模型,每个树都基于不同的随机子集数据生成,最终结果是所有树预测的加权平均。
机器学习过程通常遵循CRISP-DM(Cross-Industry Standard Process for Data Mining)流程,包括业务理解、数据理解、数据准备、建模、模型评估和模型部署等步骤,确保模型的实用性和有效性。这些算法和流程是理解和应用机器学习的基础。
Created by: Jim Liang
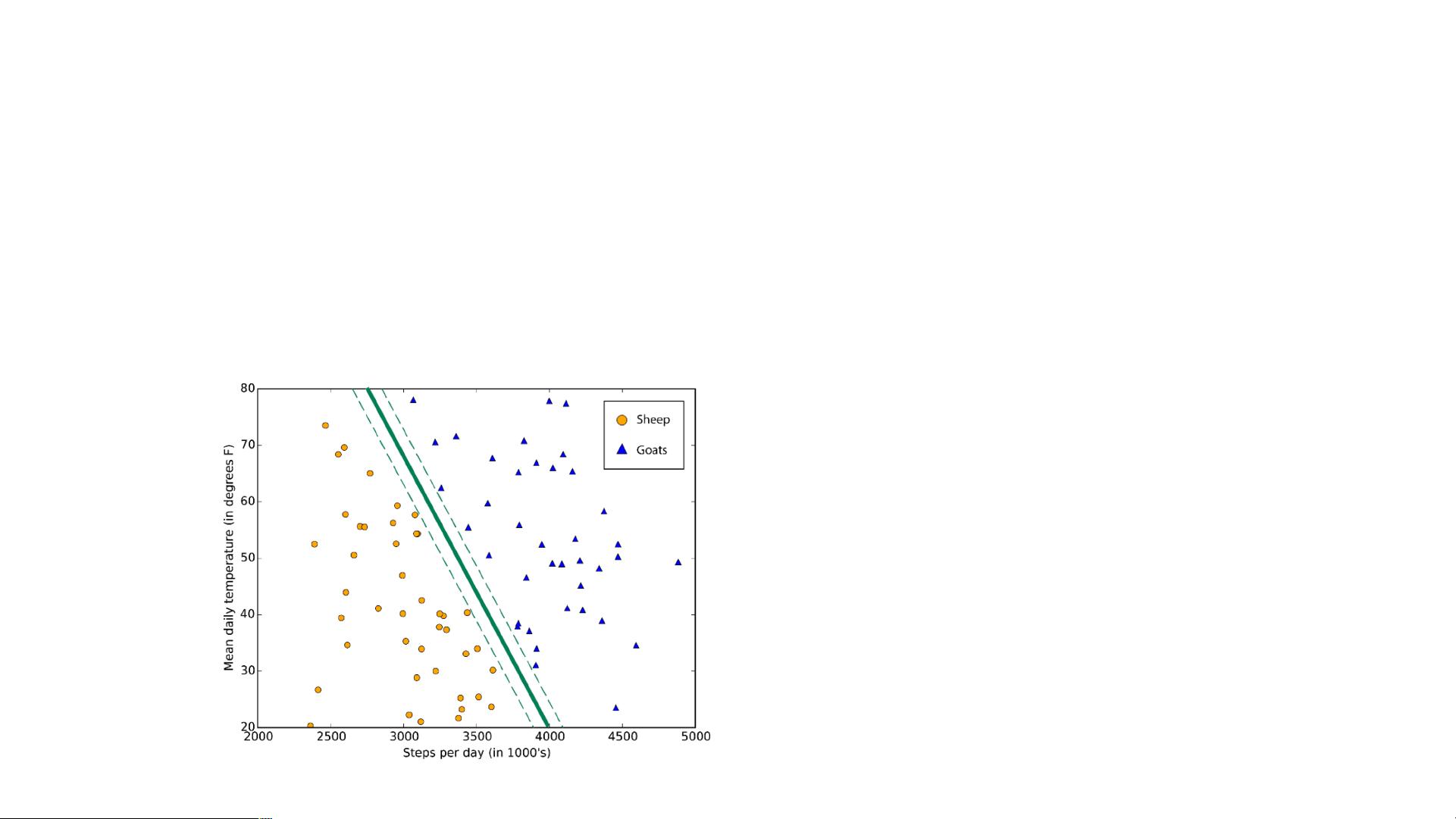
SVMs are a set of supervised learning methods used for classification, regression and outliers detection
Classifies data by finding the linear decision boundary (hyperplane) that separates all data points of one class from those of the other class. The best hyperplane for an
SVM is the one with the largest margin between the two classes, when the data is linearly separable.
1
Hyperplane
Support vector machines (SVMs) find the boundary that separates
classes by as wide a margin as possible. SVMs are capable of both
classification and regression.
Best Used...
2
• For data that has exactly two classes (you can also use it for
multiclass classification with a technique called error- correcting
output codes)
• For high-dimensional, nonlinearly separable data
• When you need a classifier that’s simple, easy to interpret, and
accurate
.
1 &2 Source: Mathworks, Applying Supervised Learning
Image Source: Microsoft, https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-algorithm-choice
:: Support Vector Machine (SVM)
剩余310页未读,继续阅读
635 浏览量
336 浏览量
266 浏览量
465 浏览量
151 浏览量
928 浏览量
166 浏览量

SebastianHe
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Subclipse 1.8.2版:Eclipse IDE的Subversion插件下载
- Spring框架整合SpringMVC与Hibernate源码分享
- 掌握Excel编程与数据库连接的高级技巧
- Ubuntu实用脚本合集:提升系统管理效率
- RxJava封装OkHttp网络请求库的Android开发实践
- 《C语言精彩编程百例》:学习C语言必备的PDF书籍与源代码
- ASP MVC 3 实例:打造留言簿教程
- ENC28J60网络模块的spi接口编程及代码实现
- PHP实现搜索引擎技术详解
- 快速香草包装技术:速度更快的新突破
- Apk2Java V1.1: 全自动Android反编译及格式化工具
- Three.js基础与3D场景交互优化教程
- Windows7.0.29免安装Tomcat服务器快速部署指南
- NYPL表情符号机器人:基于Twitter的图像互动工具
- VB自动出题题库系统源码及多技术项目资源
- AndroidHttp网络开发工具包的使用与优势
