Flink API详解:Environment、Source、Transform与Sink基础
需积分: 0 112 浏览量
更新于2024-08-05
收藏 931KB PDF 举报
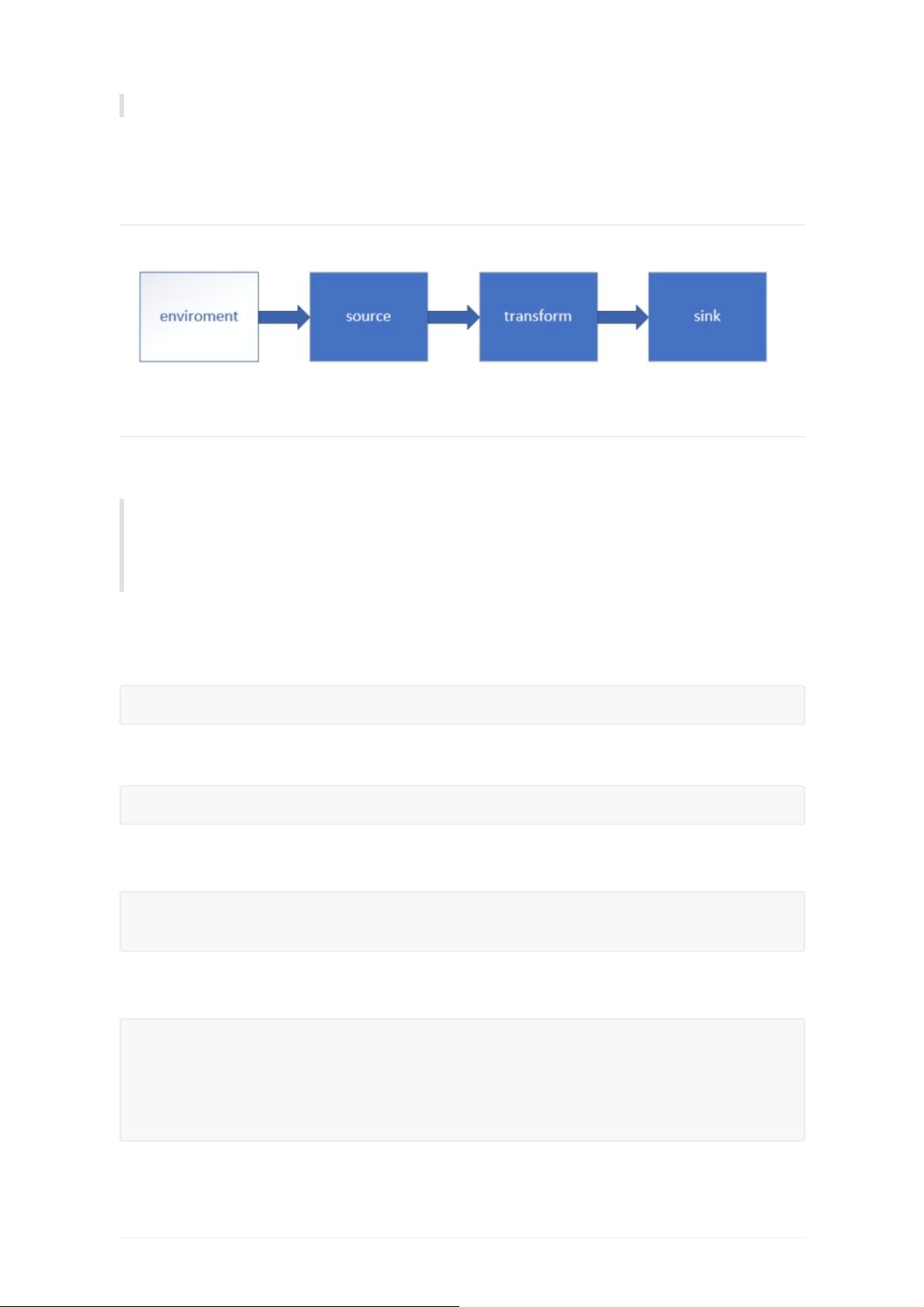
在Flink API的学习路径中,第03部分着重于环境(Environment)、源(Source)、转换(Transform)和sink的理解与使用。首先,我们从Environment开始,这是Flink程序的基础,它代表了整个程序的运行上下文和依赖环境。在Flink中,`getExecutionEnvironment`方法是创建执行环境的核心入口,它根据程序的执行方式决定返回本地环境还是集群环境。本地环境通常用于开发测试,而集群环境适用于分布式部署,如通过`createRemoteEnvironment`函数,需要提供JobManager的地址、端口以及要运行的jar包。
源(Source)是数据进入Flink处理系统的起点。Flink支持多种数据源,如文件系统(`fromCollection`用于读取本地或HDFS中的文本文件,`TextFileInputFormat`等可用于其他文件格式),以及实时数据源如Kafka。在这个示例中,定义了一个`SensorReading`类,展示了如何通过`env.fromCollection`从一个集合中读取数据。
转换(Transform)阶段是数据处理的核心,它包括一系列的操作,如map、filter、reduce等,对源数据进行处理和转换。Flink提供了丰富的操作符来实现各种计算逻辑,例如对`SensorReading`数据进行进一步处理,可能包括时间窗口操作、聚合统计或者实时分析。
最后,sink是数据处理的终点,将转换后的数据输出到目标系统。Flink支持多种sink,如打印到控制台、写入文件、数据库或消息队列。在示例中,尽管没有明确展示sink的具体实现,但可以预期的是,经过处理后的`SensorReading`对象会被写入到某个目的地,可能是文件、数据库,或者再次发送到另一个消息队列。
总结来说,这部分内容深入讲解了Flink API中如何创建执行环境,选择合适的源数据,并通过transform进行数据处理,最后将结果输出到目标。这涵盖了Flink编程的基本流程,对于理解和实际操作Flink进行大数据处理至关重要。在实际项目中,根据业务需求,开发者会灵活运用这些API,构建高效且可扩展的数据处理管道。
人生有两大悲剧,一是万念俱灰,而是踌躇满志
FlinkAPI之Environment-Source-
Transform-Sink
Environment
getExecutionEnvironment
创建一个执行环境,表示当前执行程序的上下文。 如果程序是独立调用的,则此方法返回本地
执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,也就
是说,getExecutionEnvironment会根据查询运行的方式决定返回什么样的运行环境,是最常用
的一种创建执行环境的方式。
环境直接理解为程序运行所依赖的包和变量的集合
批处理环境
流处理环境
createLocalEnvironment
createRemoteEnvironment
Source
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 返回本地执行环境,需要在调用时指定默认的并行度。
val env = StreamExecutionEnvironment.createLocalEnvironment(1)
// 返回集群执行环境,将Jar提交到远程服务器。需要在调用时指定JobManager的IP和端口号,并指定要
在集群中运行的Jar包。
val env = ExecutionEnvironment
.createRemoteEnvironment("jobmanage-hostname",
6123,"YOURPATH//wordcount.jar")
下载后可阅读完整内容,剩余9页未读,立即下载
495 浏览量
点击了解资源详情
103 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
120 浏览量
271 浏览量

耄先森吖
- 粉丝: 1143
 我的内容管理
展开
我的内容管理
展开







最新资源
- Windows CMD命令大全:实用操作与工具
- 北京大学ACM训练:算法与数据结构实战
- 提升需求分析技巧:理解冲突与深度沟通实例
- Java聊天室源代码示例与用户登录实现
- Linux一句话技巧大全:陈绪精选问答集锦
- OA办公自动化系统流程详解
- Java编程精华500提示
- JSP数据库编程实战指南:Oracle应用详解
- PCI SPC 2.3:最新规范修订历史与技术细节
- EXT中文教程:入门到进阶指南
- Ext2核心API中文详细解析
- Linux操作系统:入门与常用命令详解
- 中移动条码凭证业务:开启移动支付新时代
- DirectX 9.0 游戏开发基础教程:3D编程入门
- 网格计算新纪元:大规模虚拟组织的基础设施
- iReport实战指南:从入门到精通
