SEDA:一种可扩展的互联网服务架构
需积分: 15 75 浏览量
更新于2024-09-15
收藏 299KB PDF 举报
"seda-sosp"
SEDA(Staged Event-Driven Architecture)是一种设计高度并发互联网服务的新架构,由Matt Welsh、David Culler和Eric Brewer在加利福尼亚大学伯克利分校的计算机科学部门提出。该架构的主要目标是满足大规模并发需求,并简化构建性能良好的服务。SEDA的核心思想是将应用程序分解为一系列相互连接的事件驱动阶段,并通过显式队列进行通信。这样的设计允许服务在负载变化时保持良好的运行状态,防止资源过载。
在SEDA架构中,每个阶段都是一个独立的、事件驱动的处理单元,它们各自处理特定类型的任务。当请求到达时,会被放入适当的队列,然后由相应的阶段进行处理。这种分离的设计有助于避免单个组件成为整个系统的瓶颈,因为每个阶段可以独立扩展,同时保持其操作性能。
为了应对负载波动,SEDA引入了动态资源控制器。这些控制器可以监控各个阶段的性能,根据负载情况调整资源分配,如线程池大小、事件批处理和自适应的负载削峰策略。线程池大小的调整允许服务根据当前需求动态增减执行线程;事件批处理能减少上下文切换的开销,提高效率;而自适应负载削峰则是在系统过载时,有选择地丢弃或延迟非关键请求,确保关键服务的稳定运行。
作者们还介绍了一种基于SEDA架构实现的互联网服务平台,并对其进行了评估。实验结果表明,SEDA能够有效地提高服务的可扩展性,同时保持良好的响应时间,即使在高负载下也能保持服务的稳定性。
此外,SEDA还强调模块化和可重用性,使得开发人员可以专注于编写处理特定任务的阶段,而不是关注底层的并发控制和调度问题。这降低了复杂性,提高了代码的可维护性和可复用性,有利于构建复杂且高性能的互联网服务。
总结来说,SEDA是一种创新的软件架构,它通过将服务划分为事件驱动的阶段并采用动态资源管理策略,解决了传统互联网服务在高并发环境下的性能和稳定性问题。这一架构不仅提供了更好的服务条件,也简化了开发流程,对大规模并发服务的建设和优化具有重要的指导意义。
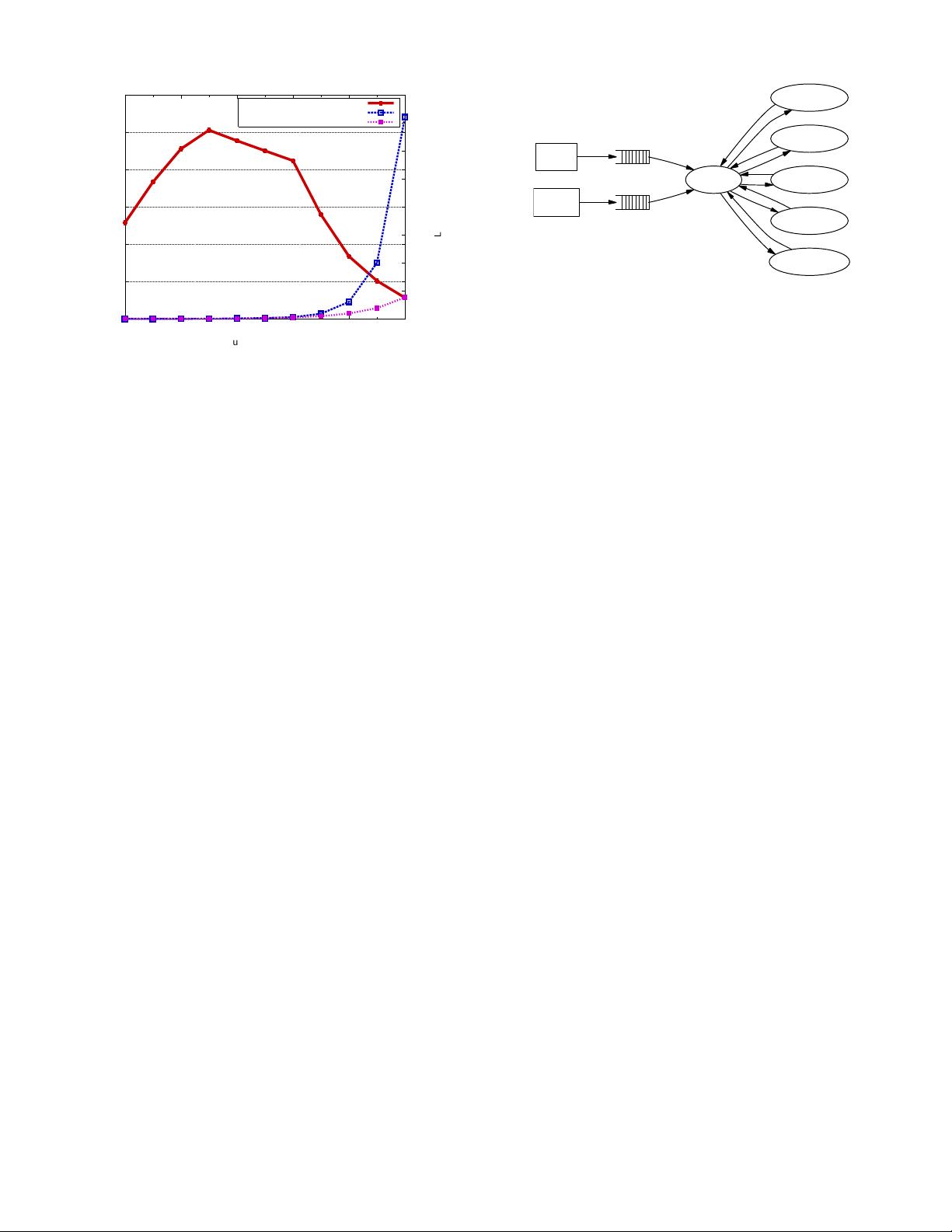
0
5000
10000
15000
20000
25000
30000
1 4 16 64 256 1024
0
50
100
150
200
250
300
350
400
Throughput, tasks/sec
Latency, msec
Number of threads
Throughput
Latency
Linear (ideal) latency
Figure 2: Threaded server throughput degradation: This benchmark mea-
sures a simple threaded server which creates a single thread for each task in the
pipeline. After receiving a task, each thread performs an 8 KB read from a disk
file; all threads read from the same file, so the data is always in the buffer cache.
Threads are pre-allocated in the server to eliminate thread startup overhead
from the measurements, and tasks are generated internally to negate network
effects. The server is implemented in C and is running on a 4-way 500 MHz
Pentium III with 2 GB of memory under Linux 2.2.14. As the number of con-
current tasks increases, throughput increases until the number of threads grows
large, after which throughput degrades substantially. Response time becomes
unbounded as task queue lengths increase; for comparison, we have shown the
ideal linear response time curve (note the log scale on the x axis).
identify internal performance bottlenecks in order to perform tuning
and load conditioning. Consider a simple threaded Web server in which
some requests are inexpensive to process (e.g., cached static pages) and
others are expensive (e.g., large pages not in the cache). With many
concurrent requests, it is likely that the expensive requests could be the
source of a performance bottleneck, for which it is desirable to perform
load shedding. However, the server is unable to inspect the internal
request stream to implement such a policy; all it knows is that the thread
pool is saturated, and must arbitrarily reject work without knowledge of
the source of the bottleneck.
Resource containers [7] and the concept of paths from the Scout op-
erating system [41, 49] are two techniques that can be used to bound
the resource usage of tasks in a server. These mechanisms apply ver-
tical resource management to a set of software modules, allowing the
resources for an entire data flow through the system to be managed as a
unit. In the case of the bottleneck described above, limiting the resource
usage of a given request would avoid degradation due to cache misses,
but allow cache hits to proceed unabated.
2.3 Event-driven concurrency
The scalability limits of threads have led many developers to eschew
them almost entirely and employ an event-driven approach to manag-
ing concurrency. In this approach, shown in Figure 3, a server consists
of a small number of threads (typically one per CPU) that loop continu-
ously, processing events of different types from a queue. Events may be
generated by the operating system or internally by the application, and
generally correspond to network and disk I/O readiness and completion
notifications, timers, or other application-specific events. The event-
driven approach implements the processing of each task as a finite state
machine, where transitions between states in the FSM are triggered by
events. In this way the server maintains its own continuation state for
each task rather than relying upon a thread context.
The event-driven design is used by a number of systems, including
scheduler
network
disk
request FSM 1
request FSM 2
request FSM 3
request FSM 4
request FSM N
Figure 3: Event-driven server design: This figure shows the flow of events
through an event-driven server. The main thread processes incoming events from
the network, disk, and other sources, and uses these to drive the execution of
many finite state machines. Each FSM represents a single request or flow of
execution through the system. The key source of complexity in this design is the
event scheduler, which must control the execution of each FSM.
the Flash [44], thttpd [4], Zeus [63], and JAWS [24] Web servers, and
the Harvest [12] Web cache. In Flash, each component of the server
responds to particular types of events, such as socket connections or
filesystem accesses. The main server process is responsible for contin-
ually dispatching events to each of these components, which are imple-
mented as library calls. Because certain I/O operations (in this case,
filesystem access) do not have asynchronous interfaces, the main server
process handles these events by dispatching them to helper processes
via IPC. Helper processes issue (blocking) I/O requests and return an
event to the main process upon completion. Harvest’s structure is very
similar: it is single-threaded and event-driven, with the exception of the
FTP protocol, which is implemented by a separate process.
The tradeoffs between threaded and event-driven concurrency mod-
els have been studied extensively in the JAWS Web server [23, 24].
JAWS provides a framework for Web server construction allowing the
concurrency model, protocol processing code, cached filesystem, and
other components to be customized. Like SEDA, JAWS emphasizes
the importance of adaptivity in service design, by facilitating both static
and dynamic adaptations in the service framework. To our knowledge,
JAWS has only been evaluated under light loads (less than 50 concur-
rent clients) and has not addressed the use of adaptivity for conditioning
under heavy load.
Event-driven systems tend to be robust to load, with little degrada-
tion in throughput as offered load increases beyond saturation. Figure 4
shows the throughput achieved with an event-driven implementation of
the service from Figure 2. As the number of tasks increases, the server
throughput increases until the pipeline fills and the bottleneck (the CPU
in this case) becomes saturated. If the number of tasks in the pipeline is
increased further, excess tasks are absorbed in the server’s event queue.
The throughput remains constant across a huge range in load, with the
latency of each task increasing linearly.
An important limitation of this model is that it assumes that event-
handling threads do not block, and for this reason nonblocking I/O
mechanisms must be employed. Although much prior work has in-
vestigated scalable I/O primitives [8, 9, 33, 46, 48], event-processing
threads can block regardless of the I/O mechanisms used, due to inter-
rupts, page faults, or garbage collection.
Event-driven design raises a number of additional challenges for the
application developer. Scheduling and ordering of events is probably
the most important concern: the application is responsible for deciding
when to process each incoming event and in what order to process the
FSMs for multiple flows. In order to balance fairness with low response
time, the application must carefully multiplex the execution of multiple
剩余13页未读,继续阅读
2021-04-22 上传
2012-04-03 上传
2022-07-06 上传
2021-04-22 上传
2022-08-04 上传
2021-07-02 上传
2019-04-13 上传
2021-08-05 上传
237 浏览量

sdslnmdJAVA
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
