网易大数据平台建设与实战经验
147 浏览量
更新于2024-08-27
1
收藏 428KB PDF 举报
"网易大数据平台架构实践分享!"
网易在应对互联网业务快速增长的背景下,逐步构建和完善其大数据平台,旨在加快数据获取和分析速度,提升数据价值。在这个过程中,网易不仅利用开源技术,还以产品化的思路来打造自身的数据平台,以解决调度、安全、元数据管理等关键问题。以下是具体的实践内容和关键技术:
1. **大数据平台概述**
网易从传统的数据库系统转向Hadoop,然后进一步发展为包含网易猛犸和网易有数在内的自研平台。网易猛犸是一个内部大数据处理平台,而网易有数则专注于智能可视化分析,这两个产品的出现表明网易在大数据处理上追求更高的效率和用户体验。
2. **Sloth:实时计算**
Sloth可能是网易用于实时数据处理的组件,可能类似于Apache Flink或Spark Streaming,提供低延迟的实时数据流处理能力,以满足快速响应的业务需求。
3. **Kudu:实时更新存储**
Kudu是Cloudera开发的一个列式存储系统,它支持快速的插入和更新操作,适合于需要实时分析的场景。网易采用Kudu可能为了实现数据的实时更新和高效查询。
4. **Kyuubi:Spark多租户**
Kyuubi是Apache Spark的多租户管理工具,它允许多个用户或应用共享Spark集群资源,确保资源的有效管理和隔离,提升了Spark在网易大数据平台中的使用效率和安全性。
5. **SQL流计算**
网易可能使用SQL接口来简化数据处理流程,使得非技术人员也能更方便地进行数据分析。这通常涉及到将SQL查询语言与流处理框架(如Apache Flink或Apache Beam)结合,实现对实时数据流的SQL查询。
6. **高性能查询引擎**
高性能查询引擎可能指的是类似Apache Parquet、Google Dremel或Apache Hive等技术,它们优化了数据的存储格式和查询性能,以支持大规模数据的快速分析。
在面临的技术挑战方面,网易可能遇到数据一致性、系统稳定性、安全性和易用性等问题。他们通过构建类数据库内核的架构,将组件如Kafka、HDFS、HBase和Spark整合,以保证系统的高性能和稳定性。此外,他们认识到大数据系统的复杂性,致力于提高使用效率,使平台更加用户友好。
未来的规划可能包括持续优化现有技术栈,引入新的大数据技术,例如机器学习和人工智能服务,以及进一步提升平台的智能化和自动化程度,以适应不断变化的业务需求和数据处理挑战。网易的大数据平台实践体现了对技术演进的敏锐洞察和对业务需求的深入理解,为其他企业和开发者提供了有价值的参考。
网易大数据平台架构实践分享!网易大数据平台架构实践分享!
随着网易云音乐、新闻、考拉、严选等互联网业务的快速发展,网易开始加速大数据平台建设,以提高数据获取速度,提升数
据分析效率,更快发挥数据价值。 本次演讲主要分享网易如何围绕和改造开源技术,以产品化思维打造网易自己的大数据平
台, 也会分享一下网易在大数据平台构建和支撑互联网业务过程中面临的技术挑战,以及我们在调度、安全、元数据管理、
spark多租户、SQL流计算、高性能查询引擎等关键技术环节的实践经验。 最后会介绍一下,网易大数据平台未来的技术路线
规划。
分享大纲:
1、大数据平台概述
2、Sloth:实时计算
3、Kudu:实时更新存储
4、Kyuubi:Spark 多租户
5、未来规划
正文:
2008年之前,网易一直在使用传统数据库软件,随着数据量的增大逐渐过渡到Hadoop平台。2009年,网易发现单独的
Hadoop平台不足以满足内部数据量的需求,便开始着手研发相关工具。2014年之后,随着网易云音乐和网易考拉等业务的发
展,网易原有工具也无法支撑庞大的数据使用诉求,网易开始进入平台化阶段,推出网易猛犸和网易有数两款产品。
网易猛犸是面向网易集团内部的大数据平台软件,网易有数是企业级智能可视化分析平台。网易之所以推出这两款产品,是因
为单纯维护Hadoop并不能满足数据使用诉求,我认为最核心的原因是大数据系统难以使用,以下是一个典型的数据处理流
程:
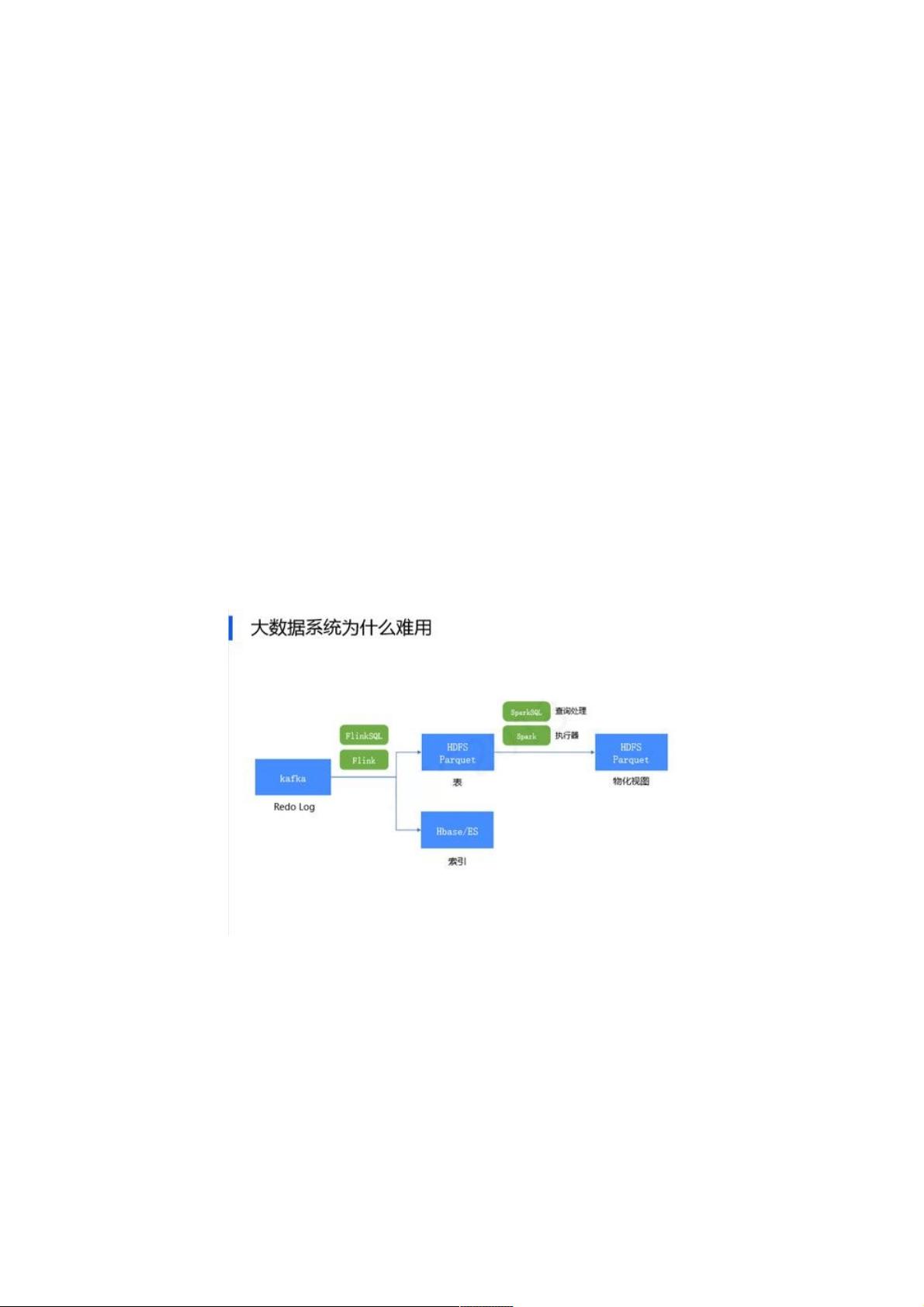
数据从Kafka出发,通过Flink处理同时写入HDFS和HBase。HDFS的数据经过Spark进一步处理最终将汇总数据返回HDFS,
传递给BI软件进行展示或者为线上数据提供支持。如果将大数据系统与数据库内核做对比,我们发现Kafka其实类似于数据库
中的Redo log,Hbase/ES代表一个索引,经过进一步汇总最终形成物化视图HDFS Parquet。
表和索引通过Kafka日志保证一致,相当于将组件重新组成类数据库内核的样子让各组件配合工作,保证系统的稳定性和性
能。整体来看,这件事情比较复杂,一番折腾下来,我们认为大数据系统还是比较难用的,需要花费大量精力组装搭配,虽然
这也证明了大数据系统比较灵活,但确实进入门槛较高。
我们考虑要做一个大数据平台,就需要先搞清楚我们的需求是什么。我认为主要有以下四点:
一是可提供大数据的基础能力;
二是在基础之上提高使用效率,所谓的使用是指用户在我们的大数据平台上开发数据业务,包括数据仓库、数据可视化、推荐
业务等的使用效率,这是大数据平台的核心价值;
三是提升管理效率,运营一个大数据平台会涉及到各方面的管理,比如升级、扩容、技术支持的代价等,我们需要提升管理效
率进而降低成本。
下载后可阅读完整内容,剩余7页未读,立即下载
276 浏览量
2021-10-14 上传
2022-05-30 上传
2022-03-04 上传
282 浏览量
2021-10-14 上传
299 浏览量
1158 浏览量
418 浏览量

weixin_38545463
- 粉丝: 6
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- teacheruz:乌兹别克斯坦地方大学的学生管理系统
- dbdot:为postgres db模式生成DOT描述
- facebook-rockin-最佳自动化-selenium-scrape-no-api-tool-bot-machine-made-to-destroy-facebook:Facebook自动化:登录,喜欢,共享,评论,发布,删除。 包含视频“实际中”。 目的主要是通过在Fakebook平台中填充垃圾内容来破坏Fakebook平台(例如,当您决定离开所有这些Fcking平台时,在其中自杀)。 请安装,测试并提交您自己的改进和功能! 谢谢!
- Trigger
- 意法半导体ST_LinkV2.7z
- banking_app_angular
- kiosk_system_rpi3:Raspberry Pi 3的Nerves QtWebEngine信息亭系统
- Tribeca
- springboot-guide:Not only Spring Boot but also important knowledge of Spring(不只是SpringBoot还有Spring重要知识点)
- maven及其maven本地仓库
- SecretSanta2020:秘密圣诞老人游戏Jam 2020的游戏
- WWH21:我的winterwonderhack2021项目
- assertj-bean-validation:Bean验证的AssertJ扩展
- pytesseract:Google Tesseract的Python包装器
- FifaOnline4Api
- Triadxs
