Scala环境下Spark WordCount程序实现
需积分: 10 52 浏览量
更新于2024-09-09
收藏 1.43MB PDF 举报
"该资源是关于使用Scala编程语言设计WordCount程序的教程,适用于Hadoop和Spark环境。提供的软件包包括Scala SDK 4.0.0、Spark 1.6.2以及Hadoop 2.6.5。教程中详细介绍了如何在Scala IDE for Eclipse环境下配置开发环境,创建Spark项目,调整Scala版本,添加Spark库依赖,并编写WordCount的基本Scala代码。"
本文主要讲解了如何使用Scala设计一个简单的WordCount程序,这个程序通常用于统计文本中的单词频率,是大数据处理领域的基础示例。首先,我们需要准备合适的软件环境,包括安装和配置Hadoop、Spark以及Scala的相关版本。在这个例子中,使用的Scala版本是2.10.4,而Spark版本为1.6.2,它们都是针对Hadoop 2.6.5设计的。
在软件环境准备阶段,我们需要将下载的Scala SDK解压并找到Eclipse可执行程序启动IDE。然后,我们可以在Scala IDE中创建一个新的Spark项目,确保项目的Scala版本与我们安装的版本一致,这里需要将默认的Scala 2.11.*版本更改为2.10.*。
接下来,为了使项目能够正确引用Spark库,我们需要在项目构建路径中添加外部JAR文件。这些JAR文件位于Spark安装目录的lib文件夹下,特别是`spark-assembly-1.6.2-hadoop2.6.0.jar`,它是Spark的核心库,包含了运行Spark程序所需的所有依赖。
在项目结构设置完成后,我们就可以创建一个新的Scala对象(即类),命名为WordCount。在代码编辑器中,我们可以编写WordCount程序的核心逻辑。在本地运行的情况下,WordCount程序的代码通常会包含以下部分:
```scala
package com.dt.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Word Count Example")
val sc = new SparkContext(conf)
// 读取数据,例如从本地文件系统
val textFile = sc.textFile("input.txt")
// 将文本数据拆分为单词
val words = textFile.flatMap(line => line.split("\\s+"))
// 计算每个单词的出现次数
val wordCounts = words.countByValue()
// 打印结果
wordCounts.foreach(println)
}
}
```
这段代码首先创建一个SparkConf对象来设置应用程序的名称,然后通过它创建一个SparkContext实例,这是Spark程序的主要入口点。`textFile`方法用于读取数据,`flatMap`用于将每行文本拆分成单词,`countByValue`计算每个单词的出现次数,最后`foreach`遍历结果并打印出来。
总结来说,这个教程涵盖了从设置开发环境到编写并理解WordCount程序的基本步骤,对于初学者来说是一个很好的起点,帮助他们了解如何在Scala和Spark框架下进行大数据处理。
1 / 8
使用 Scala 设计 WordCount 程序
(scala-SDK-4.0.0-vfinal-2. 11-linux.gtk.x86_64.tar.gz)
一、软件环境准备
1、将(scala-SDK-4.0.0-vfinal-2.11-linux.gtk.x86_64.tar.gz)拷贝到目录/root
2、tar –zxvf scala-SDK-4.0.0-vfinal-2.11-linux.gtk.x86_64.tar.gz
3、解压后会在/root 生成子目录/root/eclipse
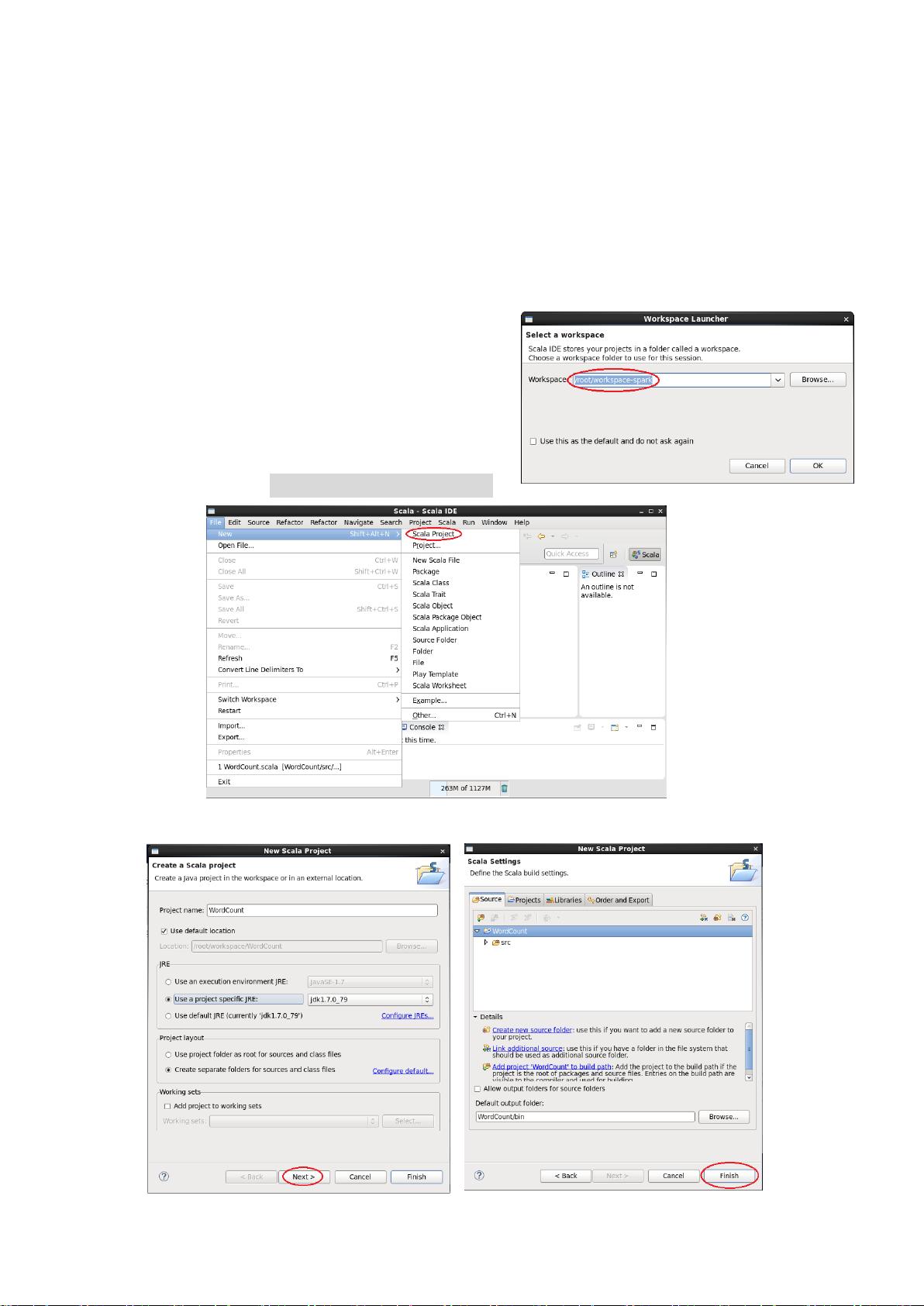
4、双击子目录/root/eclipse 下的可执行程序 eclipse 即可打开下图所示的集成开
发环境,工作空间设置为 /root/workspace-spark
二、程序设计过程
1、创建新的 Spark 项目(FileNewScala Project)
出现下列左图点击 Next,右图点击 Finish。
下载后可阅读完整内容,剩余7页未读,立即下载
2018-01-11 上传
2018-10-31 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-06-10 上传
2023-03-16 上传

wwyymmddbb
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
