Python Scrapy框架爬取豆瓣电影实战教程
134 浏览量
更新于2024-08-31
1
收藏 308KB PDF 举报
"Python利用Scrapy框架爬取豆瓣电影的实例教程"
在Python中,Scrapy是一个强大的网络爬虫框架,适用于高效地抓取网站数据并提取结构化信息。本教程将详细阐述如何使用Scrapy来爬取豆瓣电影的相关信息。
1、Scrapy框架介绍
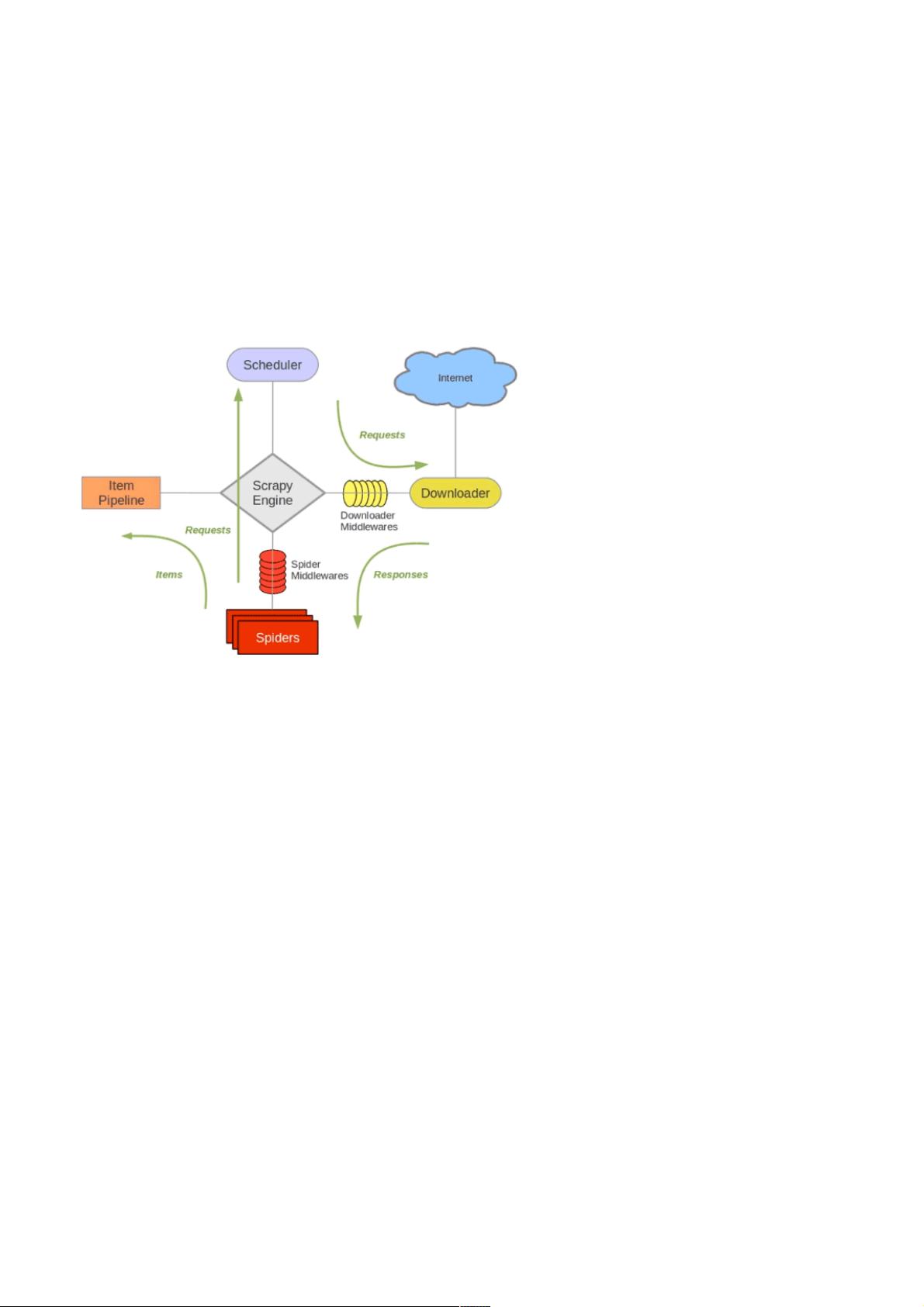
Scrapy是一个高度模块化的爬虫框架,它的核心组成部分包括:
- **引擎(Scrapy Engine)**:负责控制整个系统的数据流,调度请求(Requests)和分发响应(Responses)。
- **调度器(Scheduler)**:接收引擎发送的请求,并按照一定的策略进行队列管理,确保请求顺序执行。
- **下载器(Downloader)**:负责实际的网络交互,从互联网上下载网页内容,并将响应传递回引擎。
- **爬虫(Spiders)**:解析响应内容,提取所需数据,同时可能发现新的URL,将这些URL提交给引擎。
- **管道(Item Pipeline)**:对爬取到的数据进行清理、验证和持久化存储。
- **下载中间件(Downloader Middlewares)**:允许在请求(Requests)被下载器处理之前和响应(Responses)被传递给爬虫之后添加额外的功能,如设置代理、处理验证码等。
- **爬虫中间件(Spider Middlewares)**:在爬虫处理请求(Requests)和响应(Responses)之间添加功能,用于定制爬虫的行为。
Scrapy的工作流程如下:
1. 爬虫从入口URL开始,将URL提交给引擎。
2. 引擎将URL放入调度器。
3. 调度器按照策略返回下一个请求(Request)给引擎。
4. 引擎将请求发送给下载器。
5. 下载器下载网页内容,生成响应(Responses)返回给引擎。
6. 引擎将响应传递给爬虫进行解析。
7. 爬虫处理响应,提取数据,可能产生新的URL,再将数据和新URL提交给引擎。
8. 新URL进入调度器,重复上述过程,直到所有URL爬取完毕。
2、创建Scrapy项目
要开始使用Scrapy,首先需要在Python环境中创建一个新的Scrapy项目。在命令行中,导航到你的工作目录,然后运行以下命令:
```bash
scrapy startproject my_douban_movie
```
这将创建一个名为`my_douban_movie`的新Scrapy项目。接着,你需要创建一个爬虫,可以使用Scrapy的`genspider`命令:
```bash
cd my_douban_movie
scrapy genspider my_spider douban.com
```
这将生成一个名为`my_spider`的爬虫,用于爬取`douban.com`上的数据。接下来,你需要在`my_spider.py`文件中编写爬虫逻辑,包括如何启动爬取、如何解析HTML、如何提取所需数据等。
3、配置Scrapy
在项目目录下的`settings.py`文件中,你可以配置Scrapy的各种参数,如设置下载延迟以避免对目标网站造成过大的压力,或者定义中间件和管道。
4、编写爬虫逻辑
在`my_spider.py`中,你需要定义一个或多个爬虫类,继承自Scrapy的`Spider`基类。这里可以定义爬取的起始URL,以及如何解析HTML响应来提取数据。
5、运行爬虫
完成爬虫逻辑后,使用以下命令启动爬虫:
```bash
scrapy crawl my_spider
```
Scrapy将自动执行爬虫逻辑,抓取和处理数据。如果需要将数据保存到文件,可以配置`Item Pipeline`来处理。
通过理解Scrapy框架的基本原理和组件,以及掌握如何编写爬虫逻辑,你可以轻松地实现Python利用Scrapy框架爬取豆瓣电影信息。这个过程涉及到网络请求、HTML解析、数据提取等多个环节,需要结合Python基础知识和Web开发知识来完成。
Python利用利用Scrapy框架爬取豆瓣电影示例框架爬取豆瓣电影示例
主要介绍了Python利用Scrapy框架爬取豆瓣电影,结合实例形式分析了Python使用Scrapy框架爬取豆瓣电影信息的具体操作步
骤、实现技巧与相关注意事项,需要的朋友可以参考下
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影。分享给大家供大家参考,具体如下:
1、概念、概念
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的
程序中。
通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包
pip install scrapy
scrapy的组成结构如下图所示
引擎引擎Scrapy Engine,用于中转调度其他部分的信号和数据传递
调度器调度器Scheduler,一个存储Request的队列,引擎将请求的连接发送给Scheduler,它将请求进行排队,但引擎需要时再将队列中的第
一个请求发送给引擎
下载器下载器Downloader,引擎将请求Request链接发送给Downloader之后它就从互联网上下载相应的数据,并将返回的数据Responses交给
引擎
爬虫爬虫Spiders,引擎将下载的Responses数据交给Spiders进行解析,提取我们需要的网页信息。如果在解析中发现有新的所需要的url连
接,Spiders会将链接交给引擎存入调度器
管道管道Item Pipline,爬虫会将页面中的数据通过引擎交给管道做进一步处理,进行过滤、存储等操作
下载中间件下载中间件Downloader Middlewares,自定义扩展组件,用于在请求页面时封装代理、http请求头等操作
爬虫中间件爬虫中间件Spider Middlewares,用于对进入Spiders的Responses和出去的Requests等数据作一些修改
scrapy的工作流程:首先我们将入口url交给spider爬虫,爬虫通过引擎将url放入调度器,经调度器排队之后返回第一个请求Request,引
擎再将请求转交给下载器进行下载,下载好的数据交给爬虫进行爬取,爬取的数据一部分是我们需要的数据交给管道进行数据清洗和存储,还
有一部分是新的url连接会再次交给调度器,之后再循环进行数据爬取
2、新建、新建Scrapy项目项目
首先在存放项目的文件夹内打开命令行,在命令行下输入scrapy startproject 项目名称,就会在当前文件夹自动创建项目所需的python文
件,例如创建一个爬取豆瓣电影的项目douban,其目录结构如下:
Db_Project/
scrapy.cfg --项目的配置文件
douban/ --该项目的python模块目录,在其中编写python代码
__init__.py --python包的初始化文件
items.py --用于定义item数据结构
pipelines.py --项目中的pipelines文件
settings.py --定义项目的全局设置,例如下载延迟、并发量
spiders/ --存放爬虫代码的包目录
__init__.py
...
之后进入spiders目录下输入scrapy genspider 爬虫名 域名,就会生成爬虫文件douban.py文件,用于之后定义爬虫的爬取逻辑和正则表
达式等内容
scrapy genspider douban movie.douban.com
下载后可阅读完整内容,剩余4页未读,立即下载
5377 浏览量
2128 浏览量
193 浏览量
409 浏览量
137 浏览量
1741 浏览量
118 浏览量
409 浏览量

weixin_38622125
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Spring-Struts-Hibernate集成应用教程
- 工作流基础与jBpm开源引擎解析
- JSP入门教程:基础语法与示例解析
- MD5加密算法详解与安全性分析
- Visual FoxPro 6.0 教程:从基础到面向对象编程
- 新型轴流压缩机防喘振控制系统设计与应用
- 软件开发编码规范与约定详解
- 麦肯锡方法与结构化问题解决
- Vim编辑器完全指南:动手实践版
- 富士变频器RS485通讯卡详细指南:远程操作与扩展功能
- Spring框架入门教程
- C++/C编程规范与指南
- Struts框架详解:构建高效Web应用
- 迈克尔·巴雷的C/C++嵌入式系统编程指南
- Google搜索技巧详解:从基础到高级
- Windows系统管理命令大全
