关联规则挖掘:超市购物篮分析与算法解析
需积分: 13 160 浏览量
更新于2024-07-09
收藏 3.05MB PPTX 举报
"数据挖掘导论(第二版)中文第5章:关联规则-基础"
关联分析是数据挖掘中的一个重要领域,主要关注于在大量数据中寻找物品或事件之间的有趣关联或模式。这一章主要讲解了关联规则的基础概念和算法,以购物篮分析为例进行阐述。
关联规则挖掘的目标是发现事务数据中的规律,即在某些项目出现的情况下,可以预测其他项目也可能会一起出现。例如,著名的“尿布与啤酒”现象,即顾客在购买尿布时,很可能也会购买啤酒。然而,关联规则并不涉及因果关系,它只表明两种商品的共同出现频率较高,而并不意味着一种商品导致了另一种商品的购买。
在关联规则挖掘中,关键概念包括频繁项集、支持度和置信度。频繁项集是指在事务数据库中出现次数超过某个最小支持度阈值的项目集合。支持度是衡量一个项集在整个事务库中出现频率的指标,计算公式为项集出现的事务数除以总事务数。例如,如果“牛奶、面包、尿布”出现在2次事务中,总事务有5次,那么其支持度为2/5。
置信度则是评估关联规则强度的指标,表示在项集X发生的条件下,项集Y也发生的概率。计算公式为X与Y同时出现的事务数除以X出现的事务数。例如,规则"{牛奶,尿布}→{啤酒}"的置信度为0.67,表示在购买了牛奶和尿布的事务中,有67%的概率会同时购买啤酒。
关联规则的发现通常涉及两步:频繁项集的生成和规则的提取。首先,通过Apriori或其他类似算法找出所有满足最小支持度的频繁项集。然后,从这些频繁项集中生成满足最小置信度阈值的关联规则。这个过程可以很耗时,尤其是当项目数量很大时,因为需要生成并检查的规则数量呈指数级增长。
在实际应用中,为了减少计算复杂性,可以使用各种优化策略,比如前缀闭合、闭频繁项集等。此外,还可以使用诸如FP-growth这样的高效算法来降低计算成本。
总结来说,关联规则挖掘是一种强大的工具,可以帮助企业识别产品之间的关联,优化销售策略,进行客户行为分析等。理解和掌握关联规则的基本概念以及评价标准,对于进行有效的数据挖掘至关重要。
02/14/2018 11
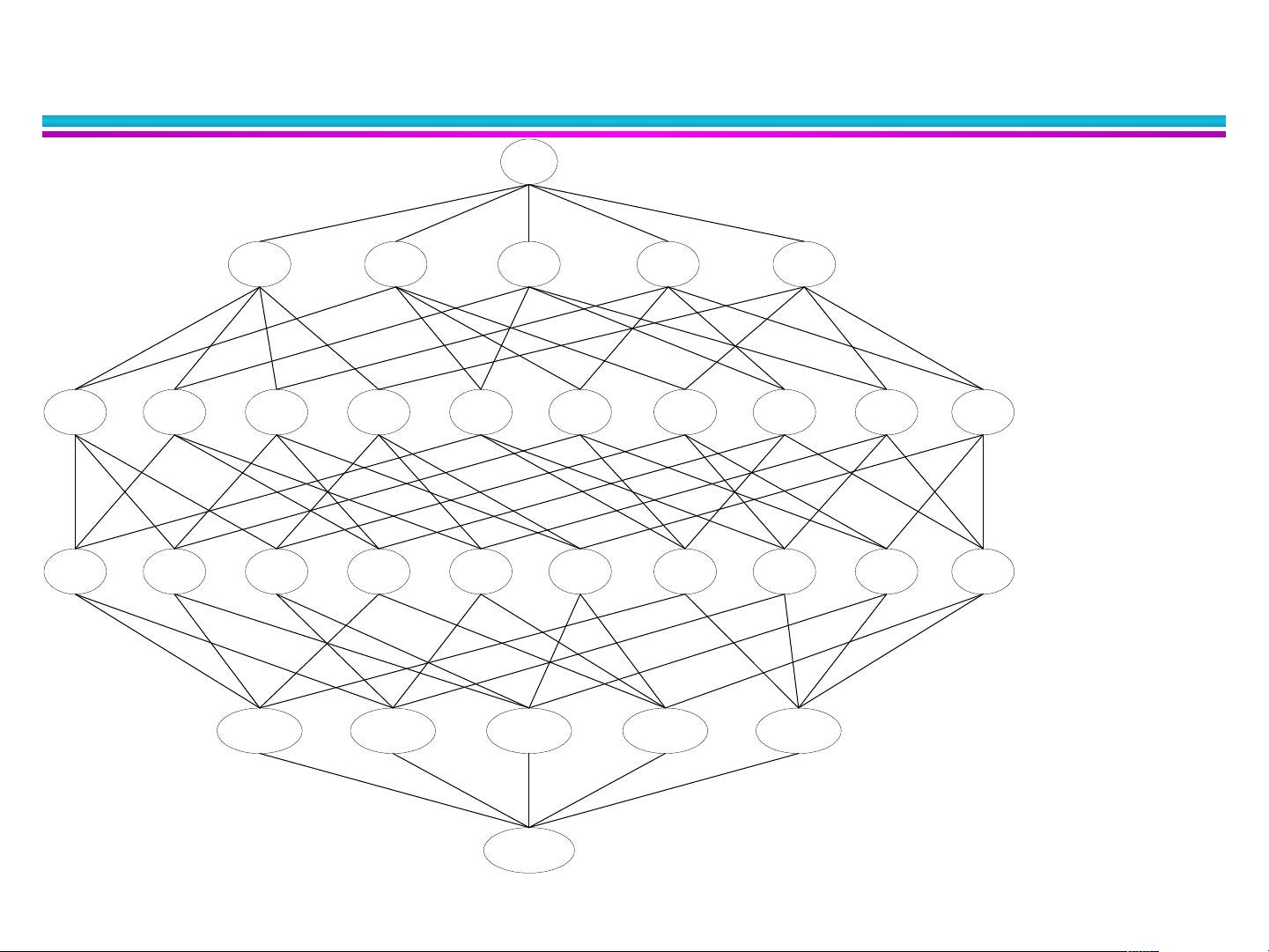
频繁项目集产生
给定 d 个项目 , 就会
产生 2
d
可能的 项集
null
AB AC AD AE BC BD BE CD CE DE
A B C D E
ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE
ABCD ABCE ABDE ACDE BCDE
ABCDE

剩余63页未读,继续阅读
2021-09-30 上传
2021-09-30 上传
2023-05-18 上传
2023-06-02 上传
2023-07-20 上传
2023-04-01 上传
2023-05-21 上传
2023-06-02 上传
2023-08-03 上传

hj_911
- 粉丝: 3
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
