
C. Mao, C. Xu and Q. He / Knowledge-Based Systems 164 (2019) 122–138 125
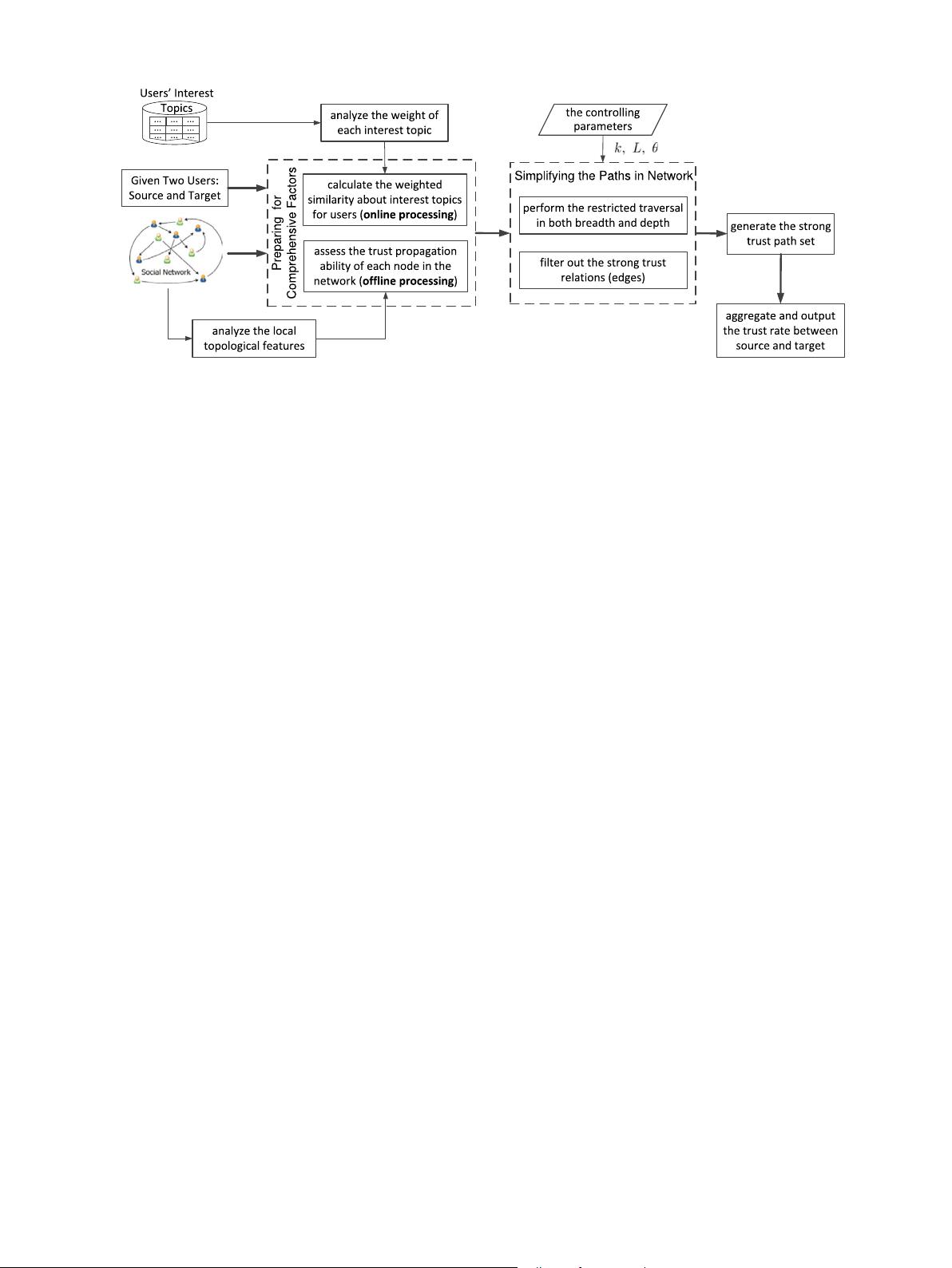
Fig. 1. The technical framework for comprehensively inferring trust between two individuals.
edge (n
s
, n
t
) from source to target in the trust graph G, the weight
of edge (n
s
, n
t
) can be directly viewed as the trust rate from source
to target. Therefore, we mainly focus on the case where there is
no edge pointing from source to target directly in G. In such a case,
there is no direct trust information from source to target, we need
to make full use of the feature information of these two users
and the topological information about their indirect connections to
infer the trust between them. We infer the trust rate between them
based on their interest topics and the trust relations of relevant
users. In addition to the concerned user pair source and target, our
algorithms take the following two inputs: (1) the corresponding
trust graph of the given social network; and (2) the collections of
all users’ interest topics extracted from their activities in the social
network. The interest topics of a user are usually reflected by his
(or her) review comments or purchasing records.
In order to efficiently infer the trust rate from source to target,
for each intermediate node, only some of its neighbors in the next
step are taken into account for trust path identification. Therefore,
the key task is to select its most relevant neighbors. During the
neighbor selection, our method mainly considers the following two
issues: the trust similarity based on interest topics and the trust
propagation ability of the node.
Given a trust graph G, the trust propagation ability of a node
n
i
(1 ≤ i ≤ |N|) in G can be evaluated with a topology structure
analysis. In the field of social network analysis, the measures for
depicting the information spreading ability of a node are usually
classified into two categories: (1) global measures which can ac-
curately describe the information diffusion ability of nodes but
require expensive computation such as the identification of the
shortest paths; and (2) local measures which only focus on the
local topological characteristics of the node for low computational
overhead. To ensure efficient trust inference, we design a local
measure to estimate the trust propagation ability of a node in
a social network. For the proposed measure, the corresponding
computation for an intermediate node in social network G is inde-
pendent from nodes source and target. Therefore, the assessment
of trust propagation ability can be performed offline. In other
words, the evaluation of a node’s trust propagation ability in G is
independent of the parameters source and target.
For the second factor, the trust similarity between two users
in a social network G is calculated based on their interest topics.
During the trust propagation, user source mainly concerns about
intermediate users who are relevant to the topics of users source
and target. Thus, the evaluation of the trust similarities between a
user and its neighbors in G should take into account the interest
topics of source and target. Accordingly, the computation of trust
similarity needs to be performed online. Different from the work
presented in [20], different interest topics play different roles in
calculating the trust similarity between users. Thus, different in-
terest topics are assigned with different weights. Here, the weight
of a topic is determined by the frequency of its appearances in the
topic sets of all users. Obviously, the weight of each interest topic
can be calculated offline.
In our framework, trust is inferred through finding the strong
trust paths (S
path
) in the social network. The nodes in each path
of set S
path
are selected based on the following two measures: the
weighted topic similarity between two adjacent nodes and the
trust propagation ability of nodes. As shown in Fig. 1, once the
above two measures are calculated, the strong trust paths in social
network G can be identified through a restricted traversal. During
the traversal, control parameters k on breadth and L on depth are
used to control the scope of search over G. At each level of traversal,
for a given node, only its top-k most similar neighbors are taken
into consideration as the next nodes in the strong trust paths. On
the other hand, according to the ‘‘small world’’ theory [2,22] in the
field of complex network, the depth of traversal is limited to L to
accelerate the identification of S
path
without significantly reducing
the effectiveness of trust inference. That is, the paths with more
than L steps in G are considered as weak trust paths and are pruned.
Under the guideline of the ‘‘small world’’ theory, parameter L is set
to 6. During the trust path identification, the most important task
is to prune weak trust paths. Given a current node, if the trust rate
on the edge pointing from this node to its neighbor is lower than a
threshold (denoted as θ ), the corresponding edge is pruned to stop
further traversal. Based on the above pruning strategy, the set of
strong trust paths (i.e., S
path
) can be efficiently identified. Finally,
the trust rate from the source node (source) to the target node
(target) is inferred based on the strong trust path set (S
path
) with
a specific aggregation strategies [51,52].
In short, the main tasks at the offline stage are to calculate the
weights of all interest topics, and to measure the trust propagation
ability of each node in network G. At the online processing stage,
the key task is the restricted traversal for identifying the strong
trust paths from source to target. For each current node during the
traversal, the trust similarities to its neighbors are calculated at
runtime. Then, both trust similarity and trust propagation ability
are taken account to find the strong trust paths. After the strong
trust paths are identified for the given user pair (source, target),
the trust rates on the edges of a trust path are aggregated as the
trust score of that path. Finally, the trust scores of the strong trust
paths in S
path
are further aggregated to produce the final trust rate.
剩余16页未读,继续阅读

weixin_38622125
- 粉丝: 7
- 资源: 939
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


