ChatGLM-6B:预训练对话模型的技术实践与优化
需积分: 0 149 浏览量
更新于2024-06-22
收藏 5.02MB PDF 举报
预训练模型技术实践是当前自然语言处理领域的重要研究方向,其核心在于通过大量的无标注文本数据进行学习,以提升模型在各种任务上的性能。ChatGLM-6B是一个典型的预训练大模型,它在中文和英文双语数据集上进行了充分的训练,拥有强大的语言理解和生成能力。
ChatGLM-6B的特点包括:
1. 双语能力:ChatGLM-6B在1:1比例的中英双语数据上进行了预训练,处理了1.4万亿个token,这使得它在处理两种语言时都表现出色,提升了跨语言交互的效率和准确性。
2. 低部署门槛:模型在FP16半精度下运行需要至少13GB显存,但通过模型量化技术,可以进一步降低至10GB(INT8)和6GB(INT4),适应更广泛的硬件环境,甚至能在消费级显卡上运行。
3. 长序列处理:相比GLM-10B的1024个token的序列长度,ChatGLM-6B可以处理长达2048个token的序列,而ChatGLM2-6B更是达到了惊人的8192个token,这使得它能应对更复杂的对话场景和应用。
4. 人类意图对齐:ChatGLM-6B采用了监督微调、反馈自助和人类反馈强化学习等方法,增强了模型理解人类指令意图的能力,使其在交互过程中更加智能和贴近用户需求。
对比ChatGLM-6B和ChatGLM2-6B,后者在多个方面有所改进,如推理速度提升42%,训练量增加到1.4万亿token,最小部署显存降低,同时在英文综合能力、中文综合能力和数学能力上均有显著提升。
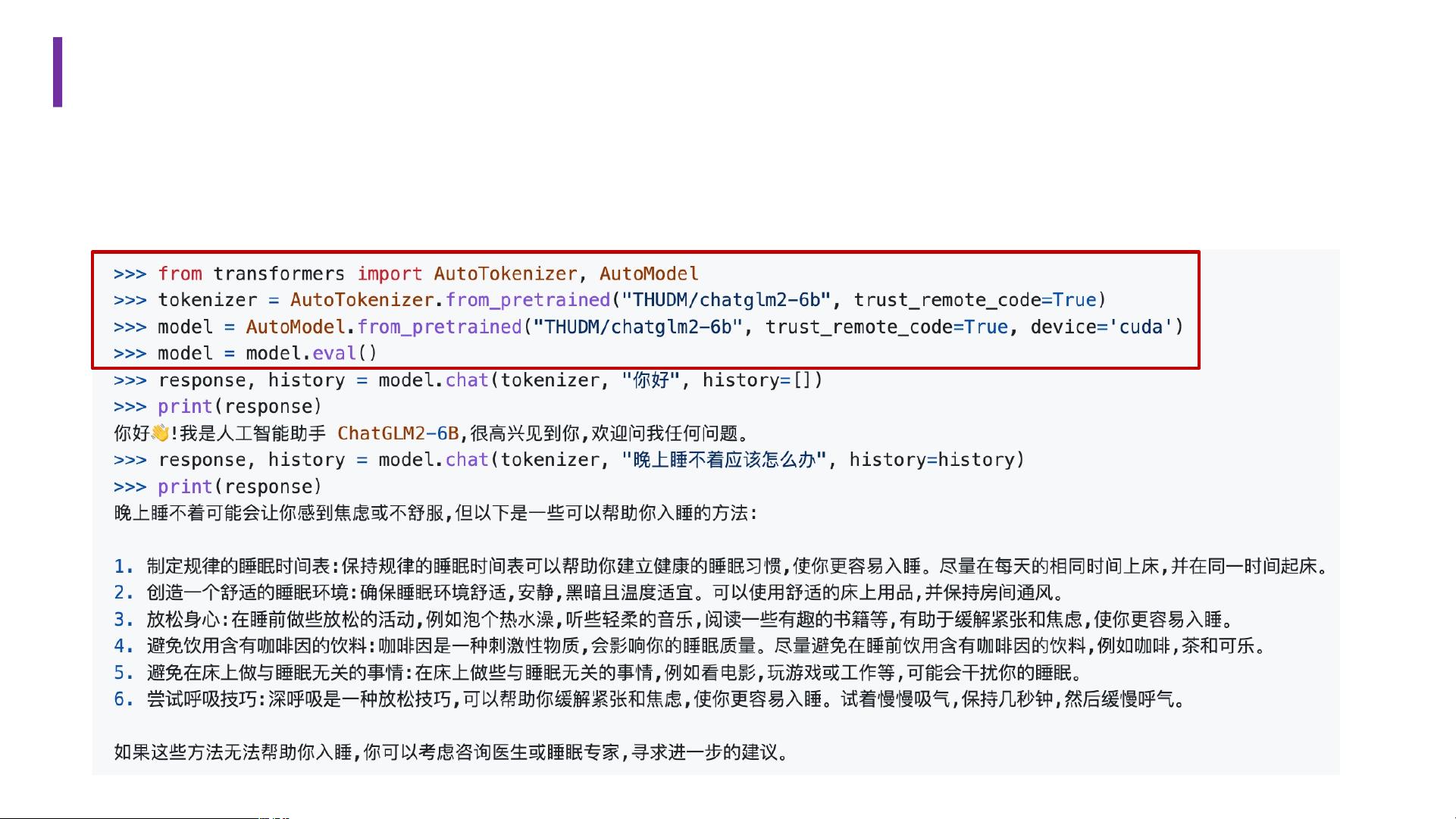
对于ChatGLM-6B的本地部署与微调,开发者可以在单机上运行模型进行对话,即使资源有限,也能通过高效微调来优化模型性能。部署过程涉及设备和基础环境的配置,Python依赖的安装,以及模型权重的准备。可以通过Huggingface平台下载模型,或者从清华云盘获取模型参数文件,然后在本地加载模型路径。
预训练模型技术实践,尤其是ChatGLM-6B及其升级版ChatGLM2-6B,展示了预训练模型在对话生成、多语言处理和适应性方面的巨大潜力,同时也提供了便捷的部署和微调方案,使得这些先进技术能够更广泛地应用于实际场景。通过不断的优化和创新,预训练模型将为人工智能领域的进步带来更大的推动力。

ChatGLM2-6B 部署: 基础环境配置
7
1)设备和基础环境
2)python依赖安装
剩余41页未读,继续阅读
2022-03-18 上传
2021-07-08 上传
2021-08-30 上传
2021-06-03 上传
2022-03-18 上传
2022-03-18 上传

fly-iot
- 粉丝: 1w+
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
