强相关性下的多项式拟合与优度分析
需积分: 0 48 浏览量
更新于2024-08-05
收藏 533KB PDF 举报
在本篇关于多项式曲线拟合的文章中,主要讨论了两个关键环节:相关性分析和多项式拟合。
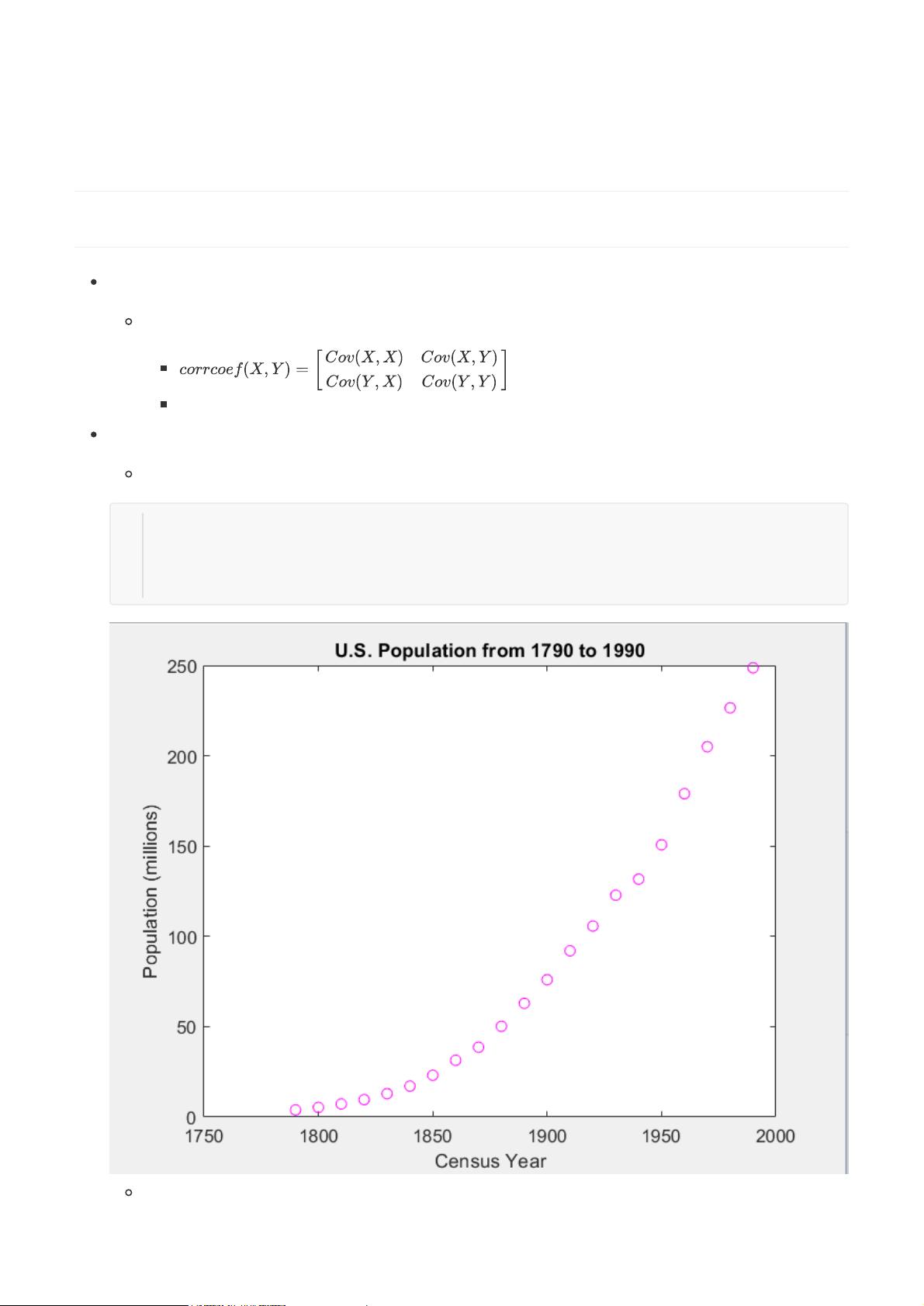
首先,我们探讨了相关性分析。通过观察原始样本数据,散点图显示了U.S.人口数据从1790年到1990年的关系,呈现出较强的线性趋势。协方差矩阵的系数接近于1,这进一步证实了数据之间存在高度正相关性。在统计学中,当两个变量的协方差接近于1,意味着它们的变化方向和强度几乎一致,对于预测和建模非常有利。
接下来,文章介绍了多项式拟合的方法。在进行拟合之前,通常会进行特征缩放,即标准化处理,这是为了确保不同特征维度间的可比性。标准ization(标准化)将数据转换为零均值和单位方差,这对于很多机器学习算法如SVM、逻辑回归和神经网络的输入是非常重要的。在Matlab的CurveFittingTool工具箱中,用户可以选择“Center and Scale”选项来实现这一操作。
在拟合过程中,作者使用了poly2和poly6等高阶多项式进行数据拟合,并提供了代码示例。通过`corrcoef`函数计算了cdate和pop变量之间的相关系数,结果显示两者非常接近1,表明拟合效果良好。此外,拟合优度分析是评估拟合质量的关键指标,包括:
1. SSE(残差平方和):它衡量了模型预测与实际值之间的差异总和。SSE越小,说明模型对数据的拟合越精确。
2. RMSE(均方根误差或标准差):这是一种衡量预测误差大小的常用指标,值越小代表预测精度越高。
通过`poly2`拟合的代码片段,可以看到如何准备数据并执行拟合,同时生成了拟合曲线和残差图,这些图可以帮助评估模型的拟合效果和数据剩余变异性。
总结来说,本文介绍了如何通过观察数据的相关性、标准化预处理以及使用多项式拟合方法来分析和解释美国人口数据。同时,通过计算SSE和RMSE等指标,我们可以全面评估多项式拟合的优劣,为后续的数据分析和模型选择提供依据。
下载后可阅读完整内容,剩余5页未读,立即下载
204 浏览量
2020-08-29 上传
2022-07-13 上传
2024-10-09 上传
2018-01-02 上传
2018-08-14 上传
2022-09-14 上传
2010-08-11 上传

鲸阮
- 粉丝: 26
- 资源: 303
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
