深入理解MySQL加锁:动态视角看InnoDB锁机制
需积分: 0 131 浏览量
更新于2024-07-01
收藏 1.03MB PDF 举报
"30.答疑文章(二):用动态的观点看加锁1"
这篇文章主要探讨了MySQL InnoDB存储引擎的加锁机制,特别是从动态的角度来理解和分析加锁规则。作者林晓斌针对读者在前两篇文章关于间隙锁、next-key lock以及加锁规则的反馈,选取了几个典型问题进行解答。
首先,文章强调了两个核心原则:
1. 加锁的基本单位是next-key lock,这是一个前开后闭的区间。
2. 只有在查找过程中访问到的对象才会被加锁。
接着,文章提到了两个优化策略:
1. 当进行索引上的等值查询,且该索引是唯一索引时,next-key lock会退化为行锁。
2. 在索引上的等值查询中,如果向右遍历且遇到的最后一个值不满足等值条件,next-key lock会退化为间隙锁。
同时,文章指出一个已知的bug:
在唯一索引上的范围查询会加锁到不满足条件的第一个值。
文章以一个具体示例深入解析了不等号条件下的等值查询。在查询语句"SELECT * FROM t WHERE id > 0 AND id < 15 ORDER BY id DESC"中,加锁范围包括主键索引上的(0,5]、(5,10]和(10,15),但id=15的行未被加上行锁。这是因为虽然查询条件是不等式,但在索引上进行查找时,数据库内部实际上会执行一系列的等值比较。当查找到达id=15时,由于不满足条件,根据优化2,next-key lock退化成了间隙锁(10,15)。
文章通过图表进一步解释了这个过程,展示了表t的主键索引id的数据结构。在这个过程中,理解加锁行为的关键在于从索引数据结构的角度出发,分析语句执行时如何与数据交互并确定加锁的范围。
总结来说,本文深入浅出地讲解了InnoDB的加锁机制,特别是next-key lock在不同场景下的表现,帮助读者理解查询语句背后的锁行为,对于优化数据库操作和避免死锁等问题具有实际指导意义。
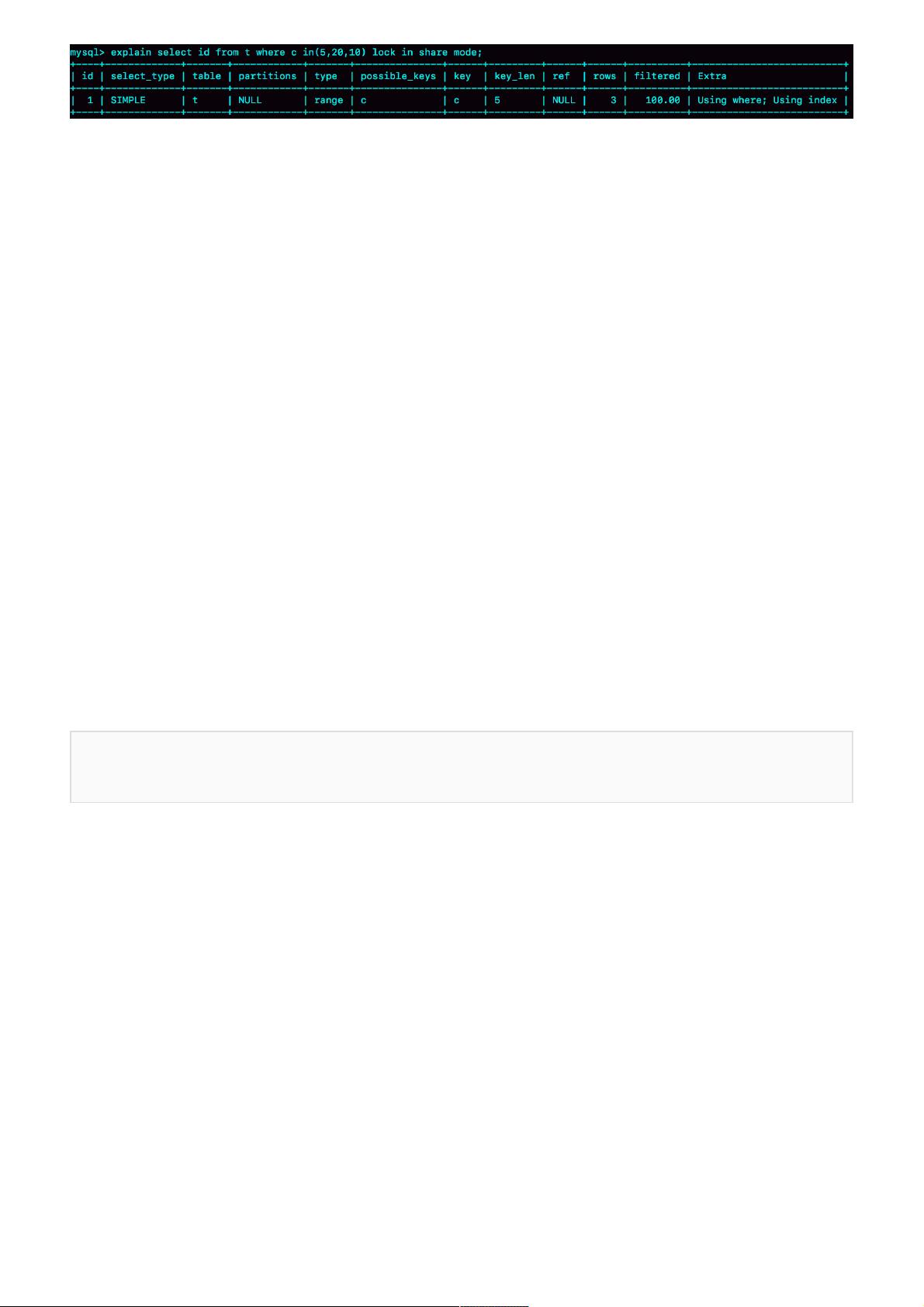
图2 in语句的explain结果
可以看到,这条in语句使用了索引c并且rows=3,说明这三个值都是通过B+树搜索定位的。
在查找c=5的时候,先锁住了(0,5]。但是因为c不是唯一索引,为了确认还有没有别的记录c=5,
就要向右遍历,找到c=10才确认没有了,这个过程满足优化2,所以加了间隙锁(5,10)。
同样的,执行c=10这个逻辑的时候,加锁的范围是(5,10] 和 (10,15);执行c=20这个逻辑的时
候,加锁的范围是(15,20] 和 (20,25)。
通过这个分析,我们可以知道,这条语句在索引c上加的三个记录锁的顺序是:先加c=5的记录
锁,再加c=10的记录锁,最后加c=20的记录锁。
你可能会说,这个加锁范围,不就是从(5,25)中去掉c=15的行锁吗?为什么这么麻烦地分段说
呢?
因为我要跟你强调这个过程:这些锁是“在执行过程中一个一个加的”,而不是一次性加上去的。
理解了这个加锁过程之后,我们就可以来分析下面例子中的死锁问题了。
如果同时有另外一个语句,是这么写的:
此时的加锁范围,又是什么呢?
我们现在都知道间隙锁是不互锁的,但是这两条语句都会在索引c上的c=5、10、20这三行记录
上加记录锁。
这里你需要注意一下,由于语句里面是order by c desc, 这三个记录锁的加锁顺序,是先锁
c=20,然后c=10,最后是c=5。
也就是说,这两条语句要加锁相同的资源,但是加锁顺序相反。当这两条语句并发执行的时候,
就可能出现死锁。
关于死锁的信息,MySQL只保留了最后一个死锁的现场,但这个现场还是不完备的。
有同学在评论区留言到,希望我能展开一下怎么看死锁。现在,我就来简单分析一下上面这个例
子的死锁现场。
select id from t where c in(5,20,10) order by c desc for update;
剩余17页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-23 上传
2014-10-05 上传
2009-07-01 上传
2009-07-01 上传
2009-07-01 上传
点击了解资源详情









