EM算法详解:极大似然与高斯混合模型应用
需积分: 12 125 浏览量
更新于2024-07-18
收藏 811KB PDF 举报
EM算法是一种迭代优化方法,常用于统计学和机器学习领域,特别是处理带有隐变量的模型。它最初由A. P. Dempster、N. M. Laird和D. B. Rubin在1977年提出,用于最大似然估计(MLE)问题的求解。在实际应用中,EM算法特别适用于高斯混合模型(GMM),即多个高斯分布组成的概率模型,常用于数据聚类和密度估计。
算法的核心思想在于“期望最大化”(Expectation-Maximization),分为两个主要步骤:
1. **期望(E-step)**:在给定当前模型参数的情况下,计算每个未观测到的隐变量的条件期望。在这个阶段,假设我们知道了每个样本可能属于的类别(尽管真实类别未知),然后根据这些可能性更新每个样本的似然度。
2. **最大化(M-step)**:基于上一步计算的期望值,重新估计模型参数,以最大化整体似然函数。这个过程通常涉及到最大化含有未知隐变量的似然函数的下界,即使这些隐变量本身无法直接估计。
以身高数据为例,如果有两类学生(男生和女生)的身高数据,且每个性别的身高服从高斯分布,但具体参数未知,EM算法可以帮助我们估计这两个高斯分布的参数,即使类别标签并未完全明确。
在更复杂的问题中,如硬币抛掷实验,EM算法可以处理多个类别和复杂的联合分布。通过假设每个样本可能来自两个硬币中的任意一个,并迭代调整每种硬币的参数,以使观察到的结果概率最大化。
当样本的类别标签部分未知时,直接最大似然估计变得困难,因为需要考虑所有可能的类别组合。EM算法通过引入隐变量并交替执行E步和M步,解决了这个问题。这种方法巧妙地将问题转化为更容易处理的形式,即使在计算复杂性增加的情况下也能找到参数的近似最优解。
EM算法是解决复杂概率模型参数估计的有效工具,它在机器学习中尤其有用,尤其是在无监督学习和混合模型中。通过迭代求解,EM算法能够逐步接近全局最优解,为数据分析和模型构建提供了强大的支持。
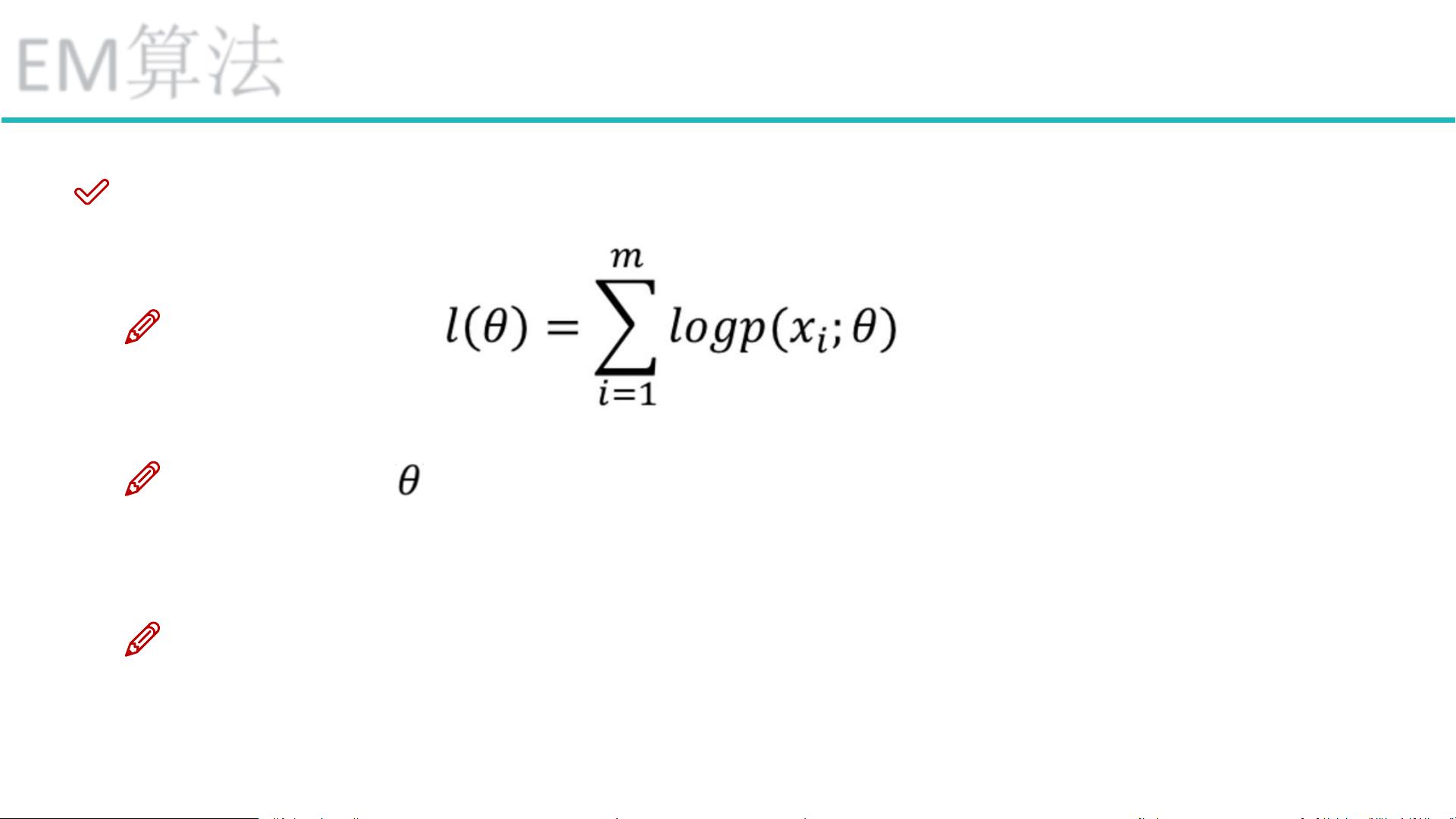
EM算法
最大似然数学问题(100名学生的身高问题)
最大似然函数: (对数是为了乘法转加法)
什么样的参数 能够使得出现当前这批样本的概率最大
已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,
参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。
剩余16页未读,继续阅读
2018-11-21 上传
2024-05-29 上传
2023-06-06 上传
2023-07-31 上传
2023-06-01 上传
2024-10-27 上传
2023-08-24 上传

cc623213878
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
