动态BERT:自适应宽度与深度的高效预训练模型
需积分: 14 164 浏览量
更新于2024-07-16
收藏 1.22MB PDF 举报
动态BERT(DynaBERT)是华为诺亚实验室提出的一种创新的预训练语言模型,旨在解决传统BERT和RoBERTa模型在计算资源和内存效率上的局限性。这些大型模型虽然在自然语言处理任务中表现出色,但它们的复杂架构使得在不同的边缘设备上部署时面临挑战,特别是对于硬件性能各异的设备来说,固定的压缩方案往往无法完全满足需求。
DynaBERT的核心在于其动态适应性,它允许模型在运行时根据硬件条件动态调整宽度(即隐藏层的数量)和深度(即Transformer层的堆叠层数)。这一设计是在首先训练一个宽度可适应的BERT模型基础上实现的。通过知识蒸馏技术,模型将全尺寸BERT的精华传递给小型子网络,确保了在减小规模的同时仍能保持较高的性能。
在训练过程中,DynaBERT采用了一种网络重连策略,这有助于保留那些对多個子网络都重要的注意力头和神经元,从而在减小模型规模的同时尽可能地保持关键功能。这种策略有助于提高模型的泛化能力和效率,使得DynaBERT能够在各种硬件环境中高效运行,无论是资源丰富的服务器还是低功耗的嵌入式设备。
实验结果显示,DynaBERT在面对严格的效率约束时,不仅能有效压缩模型大小,而且在保持或甚至提升任务性能的同时,显著降低了计算和存储需求。这对于那些对计算资源有限但需要高效NLP解决方案的应用场景来说,是一个重要的进步。通过动态调整模型结构,DynaBERT实现了在灵活性和性能之间的良好平衡,为未来的预训练语言模型设计提供了新的思路。
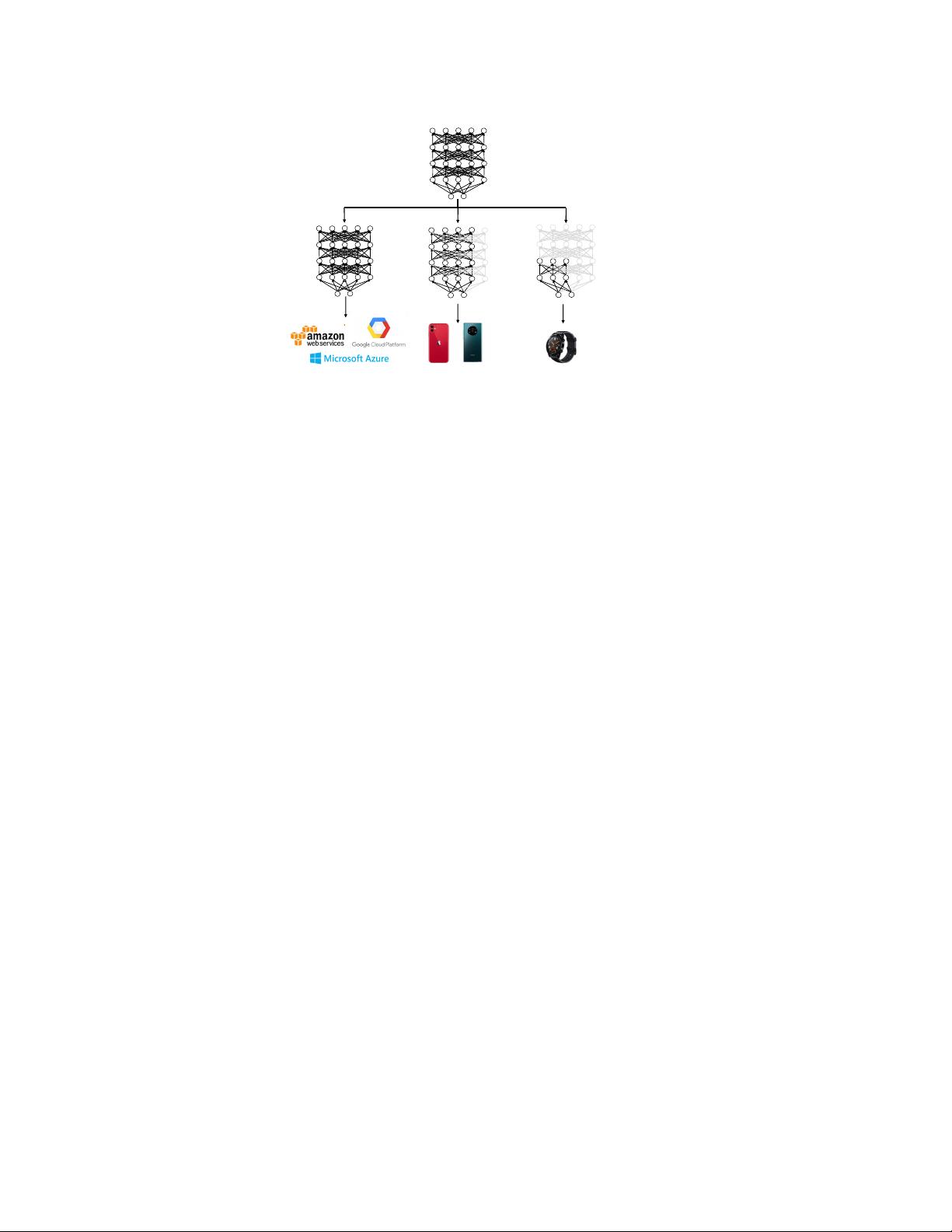
Figure 1: A network with adaptive width and depth. One single model can run at different depths
and widths to satisfy various deployment requirements.
9], considering compression and acceleration only in the depth direction can be limited. Recent
studies show that the width direction of the Transformer-based models also has high redundancy.
For example, it is shown in [23, 17] that comparable accuracy can be well maintained even when
many attention heads are pruned.
3 Method
In this section, we elaborate the training method of our DynaBERT model. The training process
includes two stages. We first train a width-adaptive DynaBERT
W
in Section 3.1 and then train the
both width- and depth-adaptive DynaBERT in Section 3.2.
3.1 Training DynaBERT
W
with Adaptive Width
Before describing the training process, we first need to define the width of BERT model. Compared
to CNNs stacked with regular convolutional layers, the BERT model stacked with Transformer lay-
ers is much more complicated. In each Transformer layer, the computation of the MHA contains
the linear transformation and multiplications of keys, queries, values for multiple heads. Moreover,
the MHA and the FFN in each Transformer layer perform transformations in different dimensions,
making it hard to trivially determine the width of the Transformer layer.
3.1.1 Using Attention Heads and Intermediate Neurons in FFN to Adapt the Width
Following [17], we divide the computation of the MHA into the computations for each attention
head as in (1). Thus the width of the MHA can be decided by the number of attention heads. The
width of the FFN can be decided by the number of neurons in the intermediate layer. We do not adapt
the number of neurons in the embedding dimension because they are connected through skip con-
nections across all Transformer layers and cannot be flexibly scaled for one particular Transformer
layer. Therefore, for a Transformer layer, we adapt its width by varying the number of attention
heads of the MHA and neurons in the intermediate layer of the FFN.
In each Transformer layer, when the width multiplier is m
w
, the MHA retains the leftmost bm
w
N
H
c
attention heads, and the FFN intermediate layer retains the leftmost bm
w
d
ff
c neurons. In this case,
each Transformer layer is roughly compressed by the ratio m
w
. Note that this is not strictly equal
because layer normalization and biases in linear layers also have a small fraction of parameters.
Different Transformer layers, or the attention heads and the neurons in the same layer, can also have
different width multipliers. In this paper, for simplicity, we focus on using the same width multiplier
for the attention heads and neurons in all Transformer layers.
4
剩余15页未读,继续阅读
2016-08-02 上传
2020-05-10 上传
2023-09-02 上传
2023-09-16 上传
2023-11-21 上传
2023-06-10 上传
2023-05-05 上传
2024-02-01 上传
2023-06-07 上传

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
