优化SSD RAID阵列一致性:CG-Resync同步方案
80 浏览量
更新于2024-08-26
收藏 205KB PDF 举报
本文主要探讨了在大规模系统中广泛采用的基于固态硬盘(SSD)的RAID阵列的数据一致性问题。RAID(Redundant Array of Independent Disks/Independent Disks with Redundancy)技术的一个关键需求是确保数据的一致性,特别是在处理写入请求时。传统上,为了实现这一目标,NVRAM(Non-Volatile Random Access Memory)和日志记录机制被用来保证数据完整性,但这往往带来了高昂的成本或显著影响性能。
对于基于SSD的RAID阵列,一种常见的策略是在系统崩溃后重启期间扫描整个存储空间来恢复数据一致性,这种方法虽然可以解决问题,但其同步时间较长,对系统效率和成本构成了挑战。为了解决这个问题,作者提出了CG-Resync(Conversion-Guided Resynchronization)方案。CG-Resync巧妙地利用了几乎所有SSD中已经内置的日志记录机制,来适应闪存的非破坏性写入需求,从而提供了一种高效且经济的SSD RAID一致性保障策略。
CG-Resync的核心思想是通过在正常运行时对写操作进行日志记录,当系统发生故障时,只需根据这些日志进行精确定位和恢复,而不是全面扫描存储空间。这种方法大大减少了重新同步所需的时间,降低了对系统资源的需求,并可能节省了硬件成本。该方案通过结合SSD的特性,兼顾了数据一致性和性能,对于现代数据中心和云计算环境中的SSD RAID设计具有重要意义。
论文详细讨论了CG-Resync的设计原理、实施细节,以及如何在实际应用中优化其性能和兼容性。它还可能包含实验结果,展示了CG-Resync在各种工作负载和故障场景下的表现,以及与其他一致性解决方案的对比分析。这篇研究论文旨在为SSD RAID阵列的设计者和管理员提供一个实用且经济的解决数据一致性问题的新方法,以提升系统的可靠性和效率。
CG-Resync: Conversion-Guided Resynchronization
for a SSD-based RAID Array
∗
Letian Yi
†
, Jiwu Shu
†§
, Jiaxin Ou
†
, Weimin Zheng
†
†
Department of Computer Science and Technology, Tsinghua University, Beijing, China
†
Tsinghua National Laboratory for Information Science and Technology, Beijing, China
lonat.front@gmail.com, shujw@tsinghua.edu.cn
Abstract—SSD-based RAID arrays have been widely adopted
in large-scale systems. One requirement on a RAID is to provide
data consistency, which can be an issue during serving write
requests. While using NVRAM or on-storage logging can ensure
the consistency, the approaches can either be very expensive or
substantially compromise performance. For SSD-based RAID,
scanning the entire storage space during rebooting after a crash
can recover the consistency. However, it takes a long resychro-
nization time. To address the issue efficiently and cost-effectively,
we propose CG-Resync, a scheme providing consistency assur-
ance for SSD-based RAIDs by leveraging logging mechanism
readily available in almost all SSDs for accommodating flash’s
out-of-place-write requirement. To identify uncompleted writes
resulting in inconsistent stripes, we use guided conversion in
managing SSD’s internal logs. In particular, only when a stripe
becomes consistent does CG-Resync allow the updated data on
the stripe to be removed from the log. We evaluate CG-Resync
and experiments show that it provides improved RAID reliability
and availability upon a crash with little performance loss during
regular I/O operations.
Index Terms—SSD array; resynchronization; consistency;
I. Introduction
A consistency problem arises when a SSD RAID array
crashes. We illustrate how the consistency can be compromised
in Figure 1. The diagram depicts the steps involved in serving
a write request on a stripe of a RAID-5 array composed of
five SSDs. In the example, among the five sectors in the stripe,
Sector P is the parity sector. While the RAID intends to carry
out requested write into the S
1
data sector, it must also update
the P parity sector in the stripe. As illustrated at Step 1, the
host issues write request for updating the data sector. Upon
receiving the request, the RAID recalculates a new parity for
the stripe at Step 2, and issues two writes to S
1
and P on SSD
1
and SSD
5
at Steps 3 4, respectively. A write request arriving
at the SSD is first queued in the SSD’s controller, and then
is scheduled to commit its data to the flash memory. The two
updates (of the data and parity) are committed on the flash
memory of SSD
5
and SSD
1
probably at different times in
Step 5 and Step 6 in the example, respectively. Between Step
§
Corresponding author: Jiwu Shu (shujw@tsinghua.edu.cn).
∗
This work is supported by the National Natural Science Foundation
of China (Grant No. 60925006,61232003), the National High Technology
Research and Development Program of China (Grant No. 2013AA013201),
and the research fund of Tsinghua-Tencent Joint Laboratory for Internet
Innovation Technology, and Tsinghua University Initiative Scientific Research
Program.
z
X
z
Y
z
Z
z
[
w
ᴺ KRVWZULWHV6
ᴼ LVVXLQJD
ZULWHWR66'
ᴻ FRPSXWLQJ
DQHZSDULW\
ᴿGDWDLV
FRPPLWWHGRQ
WKHIODVKRI
66'
ᴾSDULW\LV
FRPPLWWHGRQ
WKHIODVKRI
66'
66'
66'
66'
66'
66'
ᴽ LVVXLQJD
ZULWHWR66'
Fig. 1: Illustration of servicing a write request from the host
in the RAID-5 array.
5 and Step 6, the stripe is in a window of vulnerability. During
this time window, if the array crashes, a concurrent failure of
any of the remaining SSDs (SSD
2
, SSD
3
,orSSD
4
) would
result in data loss. Apparently when the stripe’s data and parity
stays in an inconsistent state, the data residing on a failed SSD
cannot be reconstructed. As the vulnerability is due to crash
of the array’s component SSD, we name this failure scenario
as array crash model.
If the RAID controller resides in the host machine, or the
SSD is a software RAID, incidents such as operating system
crashes and power outage can also lead to the vulnerability. In
the example, if the RAID controller crashes between Steps 3
and 4, and all SSDs remain active, the stripe will be left in an
inconsistent state after S
1
is committed on SSD
1
. We define
this failure scenario as RAID crash model.
To facilitate the presentation, we formally define a trans-
action of a RAID array in the context as a unit of work that
comprises all SSD writes for processing a single host’s write.
In the above example, a transaction includes writes to S
1
and
P. After all SSD writes of the transaction are completed at
Step 6, the transaction is considered as completed. If there are
uncompleted transactions in the event of a crash, the array lies
in vulnerable state.
II. The Design of CG-Resync
A. An Overview
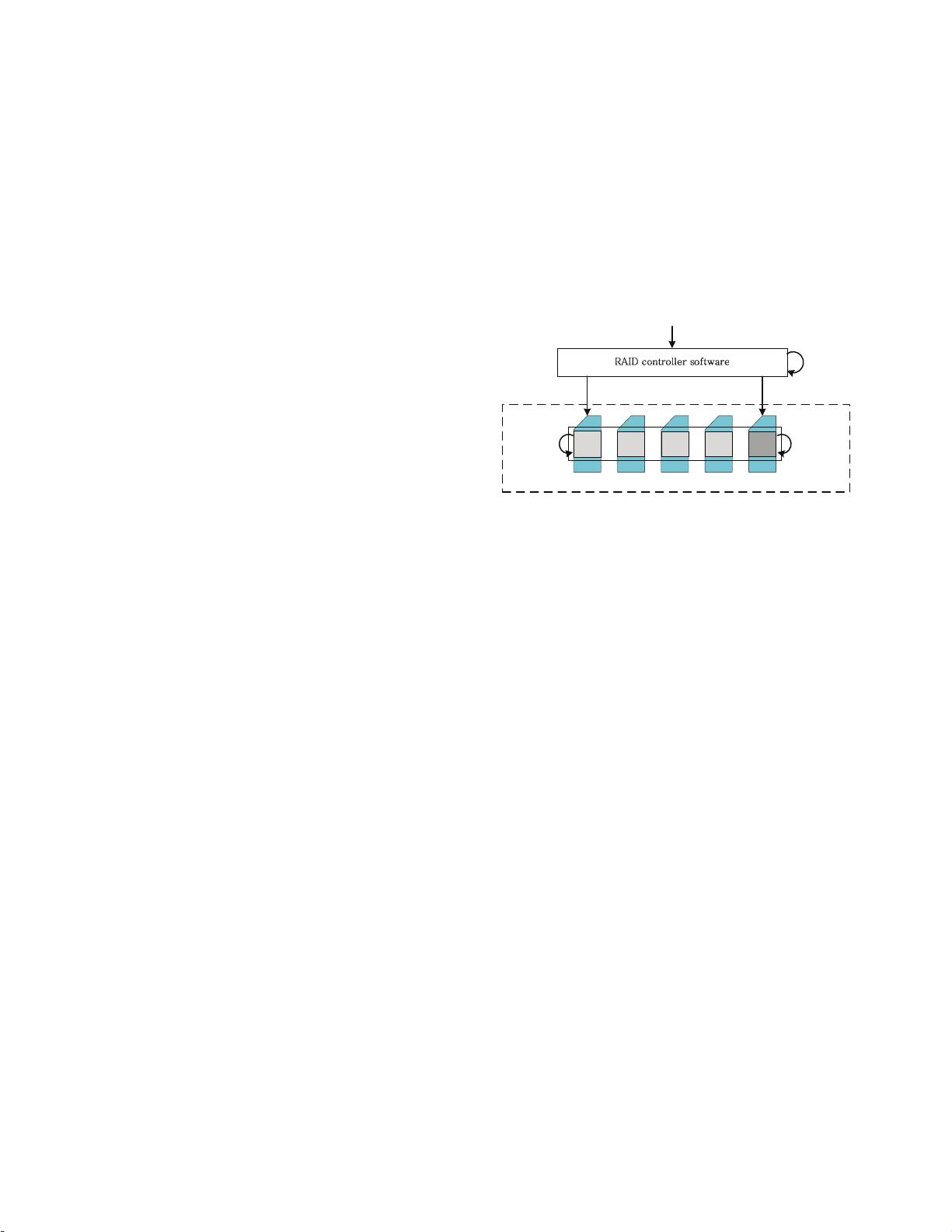
Figure 3 shows diagram CG-Resync in the SSD-based array
architecture. To identify an uncompleted transaction, we need
to maintain the relationship between the updates and their cor-
responding transactions. To this end, the Tx shepherd module
978-1-4799-2987-0/13/$31.00 ©2013 IEEE
455
下载后可阅读完整内容,剩余3页未读,立即下载
2023-04-12 上传
2023-04-12 上传
2021-06-30 上传
2021-03-26 上传
2021-05-22 上传
2021-02-25 上传
2021-07-10 上传
2021-05-22 上传
2021-02-05 上传

weixin_38747211
- 粉丝: 12
- 资源: 901
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
