深入解析XGBoost算法:二阶导数与正则化的结合
需积分: 0 139 浏览量
更新于2024-08-05
收藏 1.33MB PDF 举报
"XGBoost原理解析参考资料:陈天奇博士的slides:Introduction to Boosted Trees XGBoost是“Extreme Gradient Boosting”的缩写,由陈天奇博士于2014年提出,是对Gradient Boosting的一种改进算法。"
XGBoost是一种高效的、可扩展的梯度提升框架,尤其适用于大规模数据集。它的全称是“极端梯度提升”,是对传统梯度提升算法的优化,通过引入二阶导数和正则化项来提高模型的准确性和泛化能力。
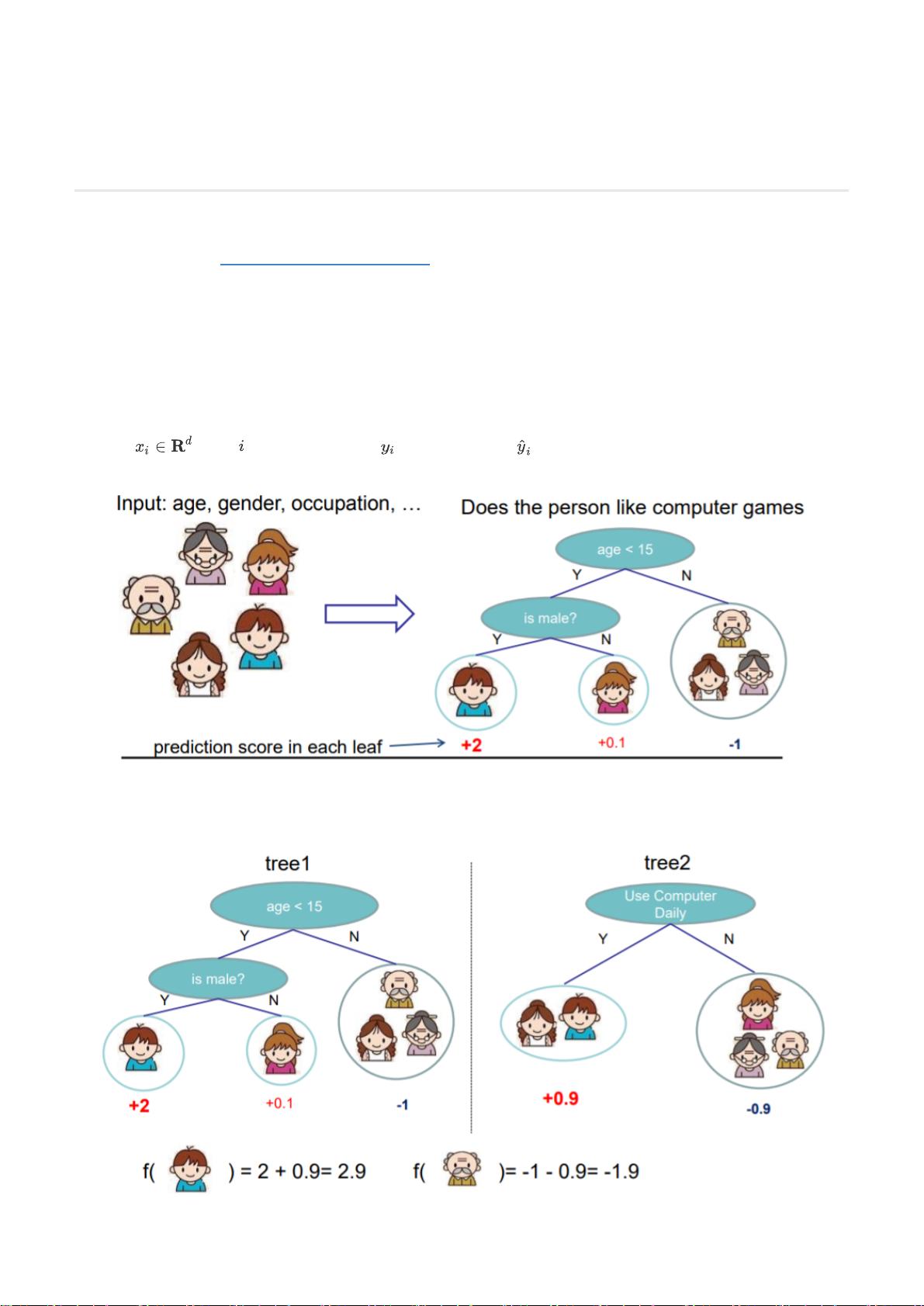
在XGBoost中,每个训练样本用表示,对应的标签是,模型的预测值记为。通常,XGBoost使用CART(分类与回归树)作为基学习器,构建回归或分类的集成模型。对于回归问题,例如预测一个人对电脑游戏的喜爱程度,XGBoost会构建一棵棵决策树,形成一个树的集合,即加性模型,其预测结果是所有树预测值的总和。
目标函数是优化的核心,它通常由训练损失函数和正则化项组成。训练损失函数衡量模型预测与真实值之间的差距,而正则化项则用于防止过拟合,控制模型复杂度。在XGBoost中,正则化项包括两部分:树的结构复杂度(如叶节点数量、深度和分割次数)和叶节点权重的L2范数,这是XGBoost区别于其他梯度提升算法的一个特点。
XGBoost使用加性模型和前向分布算法进行训练,即逐步添加新树以最小化目标函数。在第t步,目标函数可以被改写为一个关于新树的函数,通过泰勒展开进一步简化。对于平方损失函数,我们可以利用一阶导数和二阶导数的信息,将目标函数转化为更便于优化的形式。
决策树在XGBoost中被表示为一个映射函数,将样本映射到对应的叶节点,并在每个叶节点上赋予一个权重。树的复杂度则综合考虑叶节点的数量和权重的L2范数。这样,目标函数可以重写为一系列独立的二次函数的和,使得优化过程更加高效。
总结来说,XGBoost的关键在于引入二阶导数信息和正则化,这使得它可以更精确地拟合数据并减少过拟合的风险。同时,其优化策略和决策树的表示方式也大大提升了计算效率,使得XGBoost成为数据科学和机器学习领域广泛应用的工具。
XGBoost原理解析
参考资料:
陈天奇博士的slides:Introduction to Boosted Trees
XGBoost是“Extreme Gradient Boosting” 的缩写,是Gradient Boosting的一种改进算法,由陈天奇博士于2014年
提出。这里我们直接按照他的PPT思路来对XGBoost的原理进行介绍。
从名字就可以看出,传统的gradient boosting的基础是梯度,或者说一阶导数,而XGBoost不仅使用了一阶导数,
还使用了二阶导数。
我们约定 代表第 个训练样本,标签是 ,模型的预测值为 。使用CART回归树作为基学习器,我们首先从
回归问题出发,考虑下面这个例子:
这里我们的目标是根据年龄、性别、职业等特征预测一个人对电脑游戏的喜爱程度。
传统的回归树ensemble可能得到像下面这样的模型:
下载后可阅读完整内容,剩余6页未读,立即下载
2020-05-28 上传
2018-09-24 上传
2017-04-20 上传
2018-06-24 上传
2022-08-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

滚菩提哦呢
- 粉丝: 543
- 资源: 341
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ Qt影院票务系统源码发布,代码稳定,高分毕业设计首选
- 纯CSS3实现逼真火焰手提灯动画效果
- Java编程基础课后练习答案解析
- typescript-atomizer: Atom 插件实现 TypeScript 语言与工具支持
- 51单片机项目源码分享:课程设计与毕设实践
- Qt画图程序实战:多文档与单文档示例解析
- 全屏H5圆圈缩放矩阵动画背景特效实现
- C#实现的手机触摸板服务端应用
- 数据结构与算法学习资源压缩包介绍
- stream-notifier: 简化Node.js流错误与成功通知方案
- 网页表格选择导出Excel的jQuery实例教程
- Prj19购物车系统项目压缩包解析
- 数据结构与算法学习实践指南
- Qt5实现A*寻路算法:结合C++和GUI
- terser-brunch:现代JavaScript文件压缩工具
- 掌握Power BI导出明细数据的操作指南
