深度剖析:Spark性能调优实战——数据倾斜与shuffle优化
本文主要探讨的是Spark应用程序的高级调优策略,特别是针对数据倾斜和shuffle调优的问题。数据倾斜是Spark在处理大规模数据时常见的性能瓶颈,它会导致部分任务执行时间过长,严重影响整体作业的执行效率。当数据在分布式环境中不均匀分布,即某些键值对(key-value pairs)在某些节点上集中大量出现,而其他键值对则相对较少时,就会引发数据倾斜。
数据倾斜的具体表现通常包括大部分任务迅速完成,而少数任务长时间运行,甚至可能导致内存溢出。例如,一个包含1000个任务的作业中,997个任务在短时间内结束,但剩下的少数几个任务执行时间显著延长。这主要是因为在shuffle阶段,Spark尝试将相同键值的任务聚集到同一节点处理,如果数据量差距悬殊,就会形成性能瓶颈。
定位数据倾斜的关键在于理解数据流在Spark中的运作机制。shuffle操作通常由distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup等算子触发。要找出问题,需要检查这些操作的源代码,特别是那些可能导致数据分布不均的操作,如join操作中的一方数据过大,或者key-value数据的分布特性。
解决数据倾斜的方法通常包括但不限于以下几点:
1. **数据预处理**:在数据进入Spark之前,可以使用工具如Hive或Flink进行预处理,比如重采样或分区,确保数据在各个节点间的分布更加均衡。
2. **动态分区**:在shuffle前,可以调整Spark的分区策略,使数据更均匀地分布在各个分区中。
3. **数据倾斜检测**:使用内置的倾斜检测工具,如`spark.sql.shuffle.partitions`参数,来监控并调整任务分区数量,以便平衡负载。
4. **任务并行度调整**:根据实际情况,适当调整map和reduce阶段的并行度,避免过多的task集中在少数节点。
5. **使用局部性原则**:对于重复性较高的计算,尝试使用局部性优化,如广播变量或pipelining,减少远程数据交换。
6. **优化join操作**:如果是join操作导致的数据倾斜,可以通过改变join策略(如broadcast join、shuffled join)或调整join键的大小来减轻问题。
数据倾斜调优是Spark性能优化的重要环节,通过对数据分布和shuffle过程的深入理解,以及合理配置和优化代码,可以显著提升Spark作业的执行效率和稳定性。在实际应用中,需要根据具体场景灵活选择和组合这些策略。

异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的
几个 key 之后,直接在程序中将那些 key 给过滤掉。
解决方案三:提高 shue 操作的并行度
方案适用场景:如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为
这是处理数据倾斜最简单的一种方案。
方案实现思路:在对 RDD 执行 shue 算子时,给 shue 算子传入一个参数,比如
reduceByKey(1000),该参数就设置了这个 shue 算子执行时 shue read task 的数
量。对于 Spark SQL 中的 shue 类语句,比如 group by、join 等,需要设置一个参数,
即 spark.sql.shue.partitions,该参数代表了 shue read task 的并行度,该值默认
是 200,对于很多场景来说都有点过小。
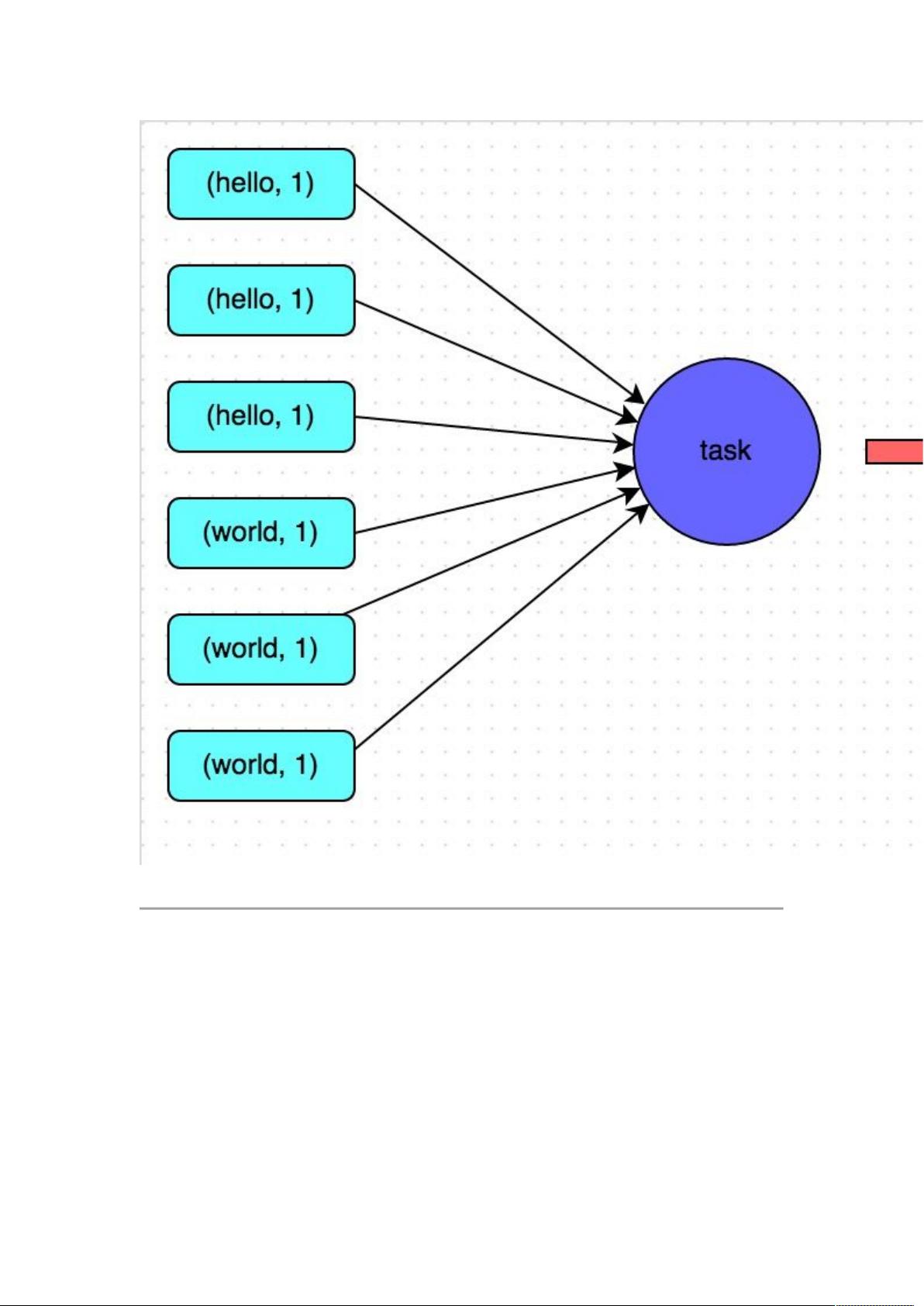
方案实现原理:增加 shue read task 的数量,可以让原本分配给一个 task 的多个 key
分配给多个 task,从而让每个 task 处理比原来更少的数据。举例来说,如果原本有 5 个
key,每个 key 对应 10 条数据,这 5 个 key 都是分配给一个 task 的,那么这个 task 就
要处理 50 条数据。而增加了 shue read task 以后,每个 task 就分配到一个 key,即
每个 task 就处理 10 条数据,那么自然每个 task 的执行时间都会变短了。具体原理如下
图所示。
方案优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有
限。
方案实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某
个 key 对应的数据量有 100 万,那么无论你的 task 数量增加到多少,这个对应着 100 万
数据的 key 肯定还是会分配到一个 task 中去处理,因此注定还是会发生数据倾斜的。所
以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用嘴简单的方法缓
解数据倾斜而已,或者是和其他方案结合起来使用。

剩余62页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-16 上传
2024-07-12 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

蚂蚁大哥大
- 粉丝: 150
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







