HBase关键算法详解:区域定位与WAL高可用机制
版权申诉
72 浏览量
更新于2024-06-26
收藏 638KB PPTX 举报
7.2列存储数据库-3.pptx文件深入探讨了HBase这一列式存储数据库的关键算法和工作原理。主要内容包括:
1. 区域(Region)定位:
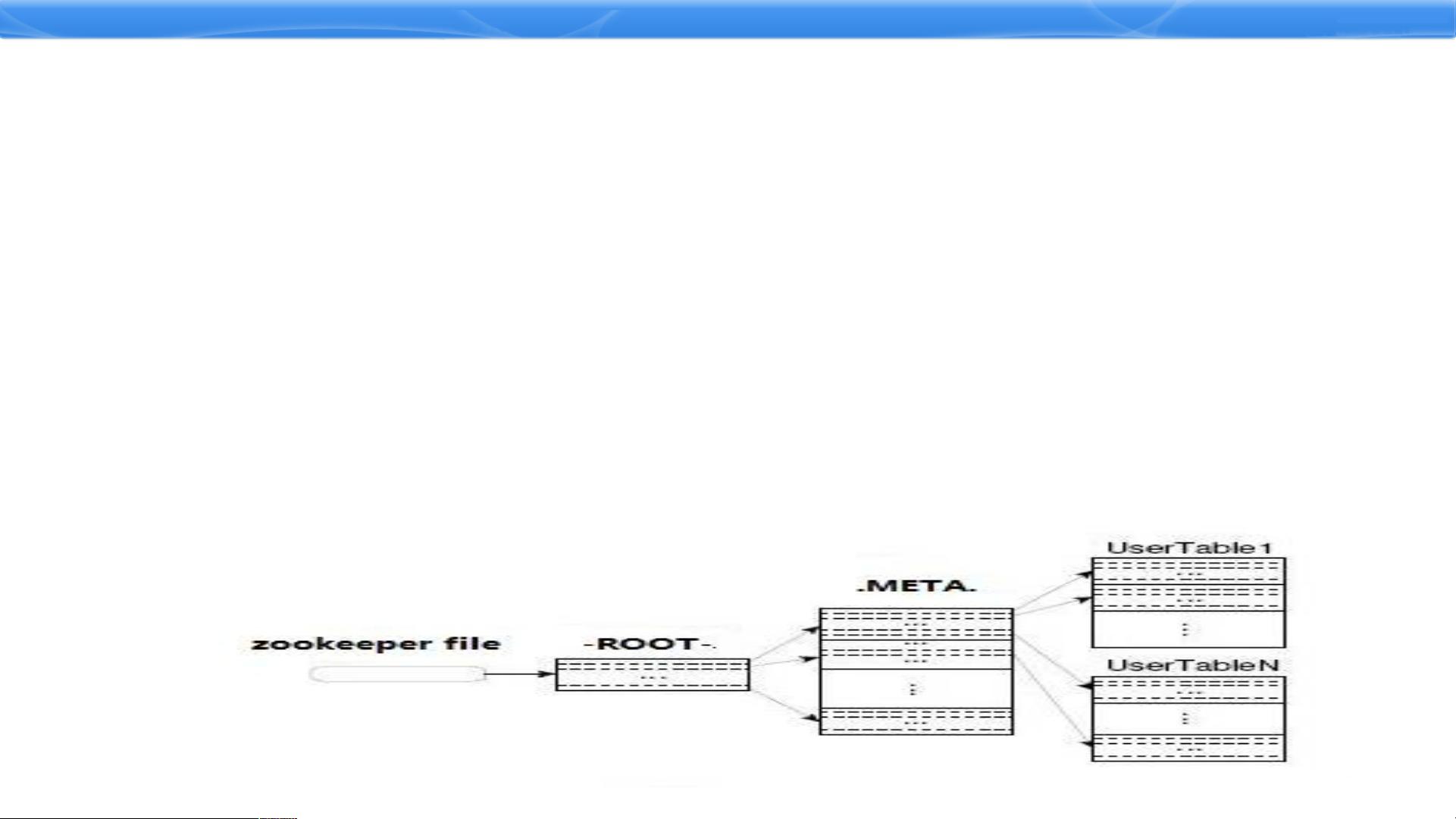
HBase的核心数据组织是基于区域的,每个表由多个区域组成,这些区域分布在不同的RegionServer上。-ROOT-表作为根节点,仅包含一个区域,通常用于存储元数据如表的其他区域列表。而.META.表则包含了所有用户数据区域及其对应的RegionServer地址,这个表中的每个行键由表名和一个特殊的编码构成。客户端通过Zookeeper快速定位区域,即使缓存失效,最多只需6次网络请求就能找到正确的区域。
2. 高可用性:
HBase通过Write-Ahead-Log (WAL)机制确保数据的高可用性。WAL是一种预写日志技术,它在数据写入到内存的MemStore之前就先写入磁盘,这样即使在RegionServer发生故障时,也能通过WAL恢复丢失的数据。此外,HBase还依赖于Zookeeper进行集群状态管理和节点的高可用性管理,如主服务器的切换。
3. 数据读写流程:
客户端请求数据时,首先从Zookeeper获取区域信息,然后连接到对应的RegionServer进行数据查找。整个过程经过精心设计,以优化性能和容错性。
4. 区域服务器与主服务器机制:
区域服务器负责处理数据的读写操作,当区域服务器需要下线或上线时,主服务器会协调资源分配。主服务器通过监控RegionServer的状态,确保数据的一致性和可靠性。
5. 基础系统结构图:
文件提供了HBase的基础系统结构图,直观展示了区域、.META.表、Zookeeper、RegionServer以及主服务器之间的关系,帮助理解HBase的整体架构。
通过学习这部分内容,可以深入了解HBase如何利用列式存储和分布式架构提供高效的数据处理,并掌握关键算法和系统设计如何确保数据的稳定性和可用性。这对于理解和应用HBase在大数据存储和处理场景中至关重要。
4
数据库原理及应用
电子科技大学-张凤荔
数据库系统原理与开发
1.区域(Region)的定位
• 原理图-----ROOT、 META
• -ROOT-:表包含.META.表所在的region列表,该表只会有一个
Region;Zookeeper中记录了-ROOT-表的location。
• .META.: 表包含所有的用户空间region列表,以及
RegionServer的服务器地址。
剩余21页未读,继续阅读
2021-02-26 上传
2021-09-22 上传
2024-04-24 上传
2024-04-26 上传
2021-09-23 上传
2021-10-08 上传









